本文主要是介绍LMAX Disruptor User Guide,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文翻译自https://lmax-exchange.github.io/disruptor/user-guide/index.html#_using_the_disruptor
文章目录
- 简介
- 核心概念
- Multicast Events(多播事件)
- 消费者依赖图
- 空间预分配
- 无锁
- Getting Started
- 基本应用
- 发布事件
- 使用原始方式发布消息
- 基础配置
- 单生产者和多生产者
- 等待策略
- 从ring buffer中清除对象
- 高级应用
- 处理大批量数据
LMAX Disruptor是一个高性能的线程间消息传递工具库。它源于LMAX对并发性、性能和非阻塞算法的研究,如今已成为Exchange基础设施的核心部分。
简介
Disruptor是一个具有并发环形缓冲区(Ring Buffer)数据结构的库。它在异步事件处理体系结构中提供了低延迟、高吞吐量的工作队列。
为了了解Disruptor的优势,我们可以将其与一些被充分理解且作用非常相似的东西进行比较。在java中,与之相似的是BlockingQueue。与queue一样,Disruptor也是在同一进程内的线程之间移动数据(例如消息或事件)。但是,Disruptor提供了其他关键特性,可以将其与queue区分开来:
- 同一个“事件”可以有多个消费者,消费者之间既可以并行处理,也可以相互依赖形成处理的先后次序(形成一个依赖图);
- 预分配用于存储事件或消息的内存空间;
- 针对极高的性能目标而实现的极度优化和无锁的设计。
下面将详细介绍上述三个特点。
核心概念
- Ring Buffer:环形缓冲区通常被认为是Disruptor主要对象。但是,从3.0开始,Ring Buffer只负责存储和更新通过Disruptor交换的数据(事件)。对于某些高级用例,用户甚至可以使用其他方式完全替换它。
- Sequence:Disruptor使用Sequence对交换的数据进行递增编号。每个消费者(事件处理器)维护一个序列,按照编号递增顺序逐个消费。它与java中的AtomicLong有很多相似的地方。事实上,两者之间唯一的区别在于Sequence可以防止不同的Sequence之间的CPU缓存伪共享(False Sharing)问题。
- Sequencer:Sequencer是Disruptor的真正核心。该接口的两种实现方式(单生产者、多生产者),它们可以用于在生产者和消费者之间快速、正确地传递数据。
- Sequence Barrier:Sequencer生成一个Sequence Barrier,其中包含对其他Sequencer的引用。它用于确定是否有事件可供消费者处理。
- Wait Strategy:等待策略确定消费者将如何等待事件。
- Event:从生产者传递到消费者的数据单位。
- Event Processor:它拥有消费者的Sequence,可以不断循环调用Event Handler处理事件。
- Event Handler:一个由用户实现的接口,也就是Disruptor消费者。
- Producer:也就是生产者,指调用Disruptor发布事件的用户代码。
下图是在LMAX的高性能核心服务中使用Disruptor的一个例子:
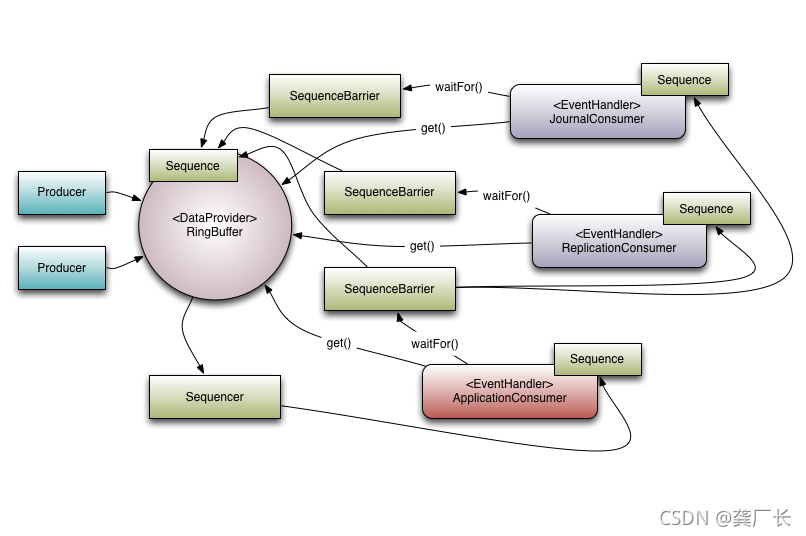
Multicast Events(多播事件)
这是队列和Disruptor之间最大的不同点。
当有多个消费者监听同一个Disruptor时,它会将所有事件发布给所有消费者。相反,队列将只向单个消费者发送事件。当需要对同一数据执行独立的多个并行操作时,可以使用Disruptor的这种行为。
消费者依赖图
为了支持并行处理的实际应用,需要协调消费者之间的执行顺序。
比如,在日志和复制消费者完成任务之前,必须阻止业务逻辑消费者进行下一步处理。我们称这一概念为“门控”。
“门控”发生需要满足以下两种情况:
- 我们需要确保生产者不会超过消费者。可以通过调用RingBuffer.addGatingConsumers()将消费者添加到Disruptor;
- 构建一个SequenceBarrier,该SequenceBarrier包含来自必须首先完成其处理的组件的Sequence。
参考上图,有3个消费者正在侦听来自ring buffer的事件。本例中有一个依赖关系图:
ApplicationConsumer依赖于JournalConsumer和ReplicationConsumer。这意味着JournalConsumer和ReplicationConsumer可以并行运行。从ApplicationConsumer的SequenceBarrier到JournalConsumer和ReplicationConsumer的Sequence的连接可以看出依赖关系。
通过使用依赖关系图,可以进行有趣的优化。因为ApplicationConsumer的序列保证小于或等于JournalConsumer和ReplicationConsumer的序列(这是依赖关系所确保的),所以Sequencer只需要查看ApplicationConsumer的序列。在更一般的意义上,Sequencer只需要知道作为依赖树中的叶节点的使用者的序列。
空间预分配
Disruptor的目标之一是在低延迟环境中使用。在低延迟系统中,有必要减少或删除内存分配所造成的的性能开销。在基于Java的系统中,目的是减少由于垃圾收集而导致的暂停次数。
为了解决这个问题,我们可以预先分配Disruptor内事件所需的存储空间。在启动时,Disruptor调用EventFactory构建事件对象来填充ring buffer中每个条目。当发布新事件时,Disruptor提供了API,允许程序获取之前构建的事件对象,然后调用该事件对象上的方法或者更新字段。Disruptor可以保证这些操作是并发安全的。
无锁
Disruptor广泛使用了无锁算法,使用内存屏障或CAS操作来保证内存可见性和正确性。
在BlockingWaitStrategy中,有一个场景需要使用到锁。这样做的原因是在等待新事件到达前可以停止运行线程。许多低延迟系统使用忙等待,来避免使用Condition可能造成的抖动;但是,大量忙等待会导致性能显著下降,尤其是在CPU资源严重受限的情况下,例如虚拟化环境中的web服务器。
Getting Started
可以从下面网址上获取Disruptor。
https://search.maven.org/artifact/com.lmax/disruptor
基本应用
下面用一个非常简单和虚构的例子来介绍如何使用Disruptor。我们将把单个长值从生产者传递给消费者,消费者只需打印出值。
目前对生产者和消费者有多种不同的实现方式,虽然它们在本质上都是相似的,但下面将介绍的每种方法可能都有细微差别。
首先,我们定义事件对象,该事件对于以下所有示例都是通用的:
public class LongEvent
{private long value;public void set(long value){this.value = value;}
}
为了使Disruptor预先分配事件内存空间,我们需要创建一个EventFactory:
public class LongEventFactory implements EventFactory<LongEvent>
{public LongEvent newInstance(){return new LongEvent();}
}
事件定义之后,我们需要创建一个消费者来处理这些事件。我们将创建一个EventHandler,将值打印到控制台。
public class LongEventHandler implements EventHandler<LongEvent>
{public void onEvent(LongEvent event, long sequence, boolean endOfBatch){System.out.println("Event: " + event);}
}
最后,我们需要定义一个事件源。为简单起见,我们假设数据来自某种类型的I/O设备,例如网络或文件。
发布事件
从Disruptor 3.0开始,就可以使用Lambda风格来编写程序。这是首选方法,因为它封装了许多复杂性。
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;public class LongEventMain
{public static void main(String[] args) throws Exception{int bufferSize = 1024; //指定ring buffer大小,必须是2的幂。//创建Disruptor对象Disruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);//创建消费者disruptor.handleEventsWith((event, sequence, endOfBatch) ->System.out.println("Event: " + event)); disruptor.start(); //启动Disruptor//获取ring buufer,用于发布事件RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); ByteBuffer bb = ByteBuffer.allocate(8);for (long l = 0; true; l++){bb.putLong(0, l);ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);Thread.sleep(1000);}}
}
请注意,publishEvent()的lambda只引用明确传入的参数。
如果按照下面方式编写代码:
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{bb.putLong(0, l);ringBuffer.publishEvent((event, sequence) -> event.set(bb.getLong(0)));Thread.sleep(1000);
}
上面代码意味着在将lambda传递给publishEvent()时,需要实例化一个对象来保存变量bb。这将创建额外的(不必要的)垃圾,因此如果需要低GC压力,则最好使用将参数传递给lambda。
考虑到可以使用方法引用而不是匿名lambda,可以用以下方式重写示例:
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.util.DaemonThreadFactory;import java.nio.ByteBuffer;public class LongEventMain
{public static void handleEvent(LongEvent event, long sequence, boolean endOfBatch){System.out.println(event);}public static void translate(LongEvent event, long sequence, ByteBuffer buffer){event.set(buffer.getLong(0));}public static void main(String[] args) throws Exception{int bufferSize = 1024;Disruptor<LongEvent> disruptor =new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);disruptor.handleEventsWith(LongEventMain::handleEvent);disruptor.start();RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();ByteBuffer bb = ByteBuffer.allocate(8);for (long l = 0; true; l++){bb.putLong(0, l);ringBuffer.publishEvent(LongEventMain::translate, bb);Thread.sleep(1000);}}
}
官网上还介绍了一些3.0以前版本发布消息的方式,本文不再介绍。
使用原始方式发布消息
下面介绍一种使用更“原始”的方法发布消息的方式:
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.examples.longevent.LongEvent;import java.nio.ByteBuffer;public class LongEventProducer
{private final RingBuffer<LongEvent> ringBuffer;public LongEventProducer(RingBuffer<LongEvent> ringBuffer){this.ringBuffer = ringBuffer;}public void onData(ByteBuffer bb){long sequence = ringBuffer.next(); try{LongEvent event = ringBuffer.get(sequence); event.set(bb.getLong(0)); }finally{ringBuffer.publish(sequence);}}
}
上面代码将消息发布放在try/finally块中。
如果我们在环形缓冲区中声明一个sequence(调用RingBuffer#next()),那么我们必须发布此sequence。不这样做可能导致Disruptor的崩溃。
具体来说,在多个生产者的场景下,这会导致消费者停滞,并且在不重新启动的情况下无法恢复。因此建议使用lambda。
最后把整个程序整合起来:
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.examples.longevent.LongEventFactory;
import com.lmax.disruptor.examples.longevent.LongEventHandler;
import com.lmax.disruptor.util.DaemonThreadFactory;import java.nio.ByteBuffer;public class LongEventMain
{public static void main(String[] args) throws Exception{LongEventFactory factory = new LongEventFactory();int bufferSize = 1024;Disruptor<LongEvent> disruptor =new Disruptor<>(factory, bufferSize, DaemonThreadFactory.INSTANCE);disruptor.handleEventsWith(new LongEventHandler());disruptor.start();RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();LongEventProducer producer = new LongEventProducer(ringBuffer);ByteBuffer bb = ByteBuffer.allocate(8);for (long l = 0; true; l++){bb.putLong(0, l);producer.onData(bb);Thread.sleep(1000);}}
}
基础配置
下面介绍一些在特殊场景下可以提高性能的配置。
有两个主要配置:
- 单个生产者和多个生产者;
- 可选择的等待策略。
这些选项都需要在创建Disruptor对象时指定。比如:
public class LongEventMain
{public static void main(final String[] args){//.....Disruptor<LongEvent> disruptor = new Disruptor(factory,bufferSize,DaemonThreadFactory.INSTANCE,//使用ProducerType#SINGLE创建SingleProducerSequencer;使用ProducerType#MULTI创建MultiProducerSequenceProducerType.SINGLE, new BlockingWaitStrategy() //设置等待策略);//.....}
}
单生产者和多生产者
提高并发系统性能的最佳方法之一是使用单生产者,这适用于Disruptor。如果程序中只有一个线程向Disruptor发布事件,那么可以利用这一点获得额外的性能。
为了说明通过这种技术可以获得多大的性能优势,我们可以执行OneToOne性能测试来看一下两者差异。测试在i7 Sandy Bridge MacBook Air上运行。
多生产者:
| 运行 | 测试结果 |
|---|---|
| Run 0 | Disruptor=26,553,372 ops/sec |
| Run 1 | Disruptor=28,727,377 ops/sec |
| Run 2 | Disruptor=29,806,259 ops/sec |
| Run 3 | Disruptor=29,717,682 ops/sec |
| Run 4 | Disruptor=28,818,443 ops/sec |
| Run 5 | Disruptor=29,103,608 ops/sec |
| Run 6 | Disruptor=29,239,766 ops/sec |
单生产者:
| 运行 | 测试结果 |
|---|---|
| Run 0 | Disruptor=89,365,504 ops/sec |
| Run 1 | Disruptor=77,579,519 ops/sec |
| Run 2 | Disruptor=78,678,206 ops/sec |
| Run 3 | Disruptor=80,840,743 ops/sec |
| Run 4 | Disruptor=81,037,277 ops/sec |
| Run 5 | Disruptor=81,168,831 ops/sec |
| Run 6 | Disruptor=81,699,346 ops/sec |
等待策略
Disruptor默认等待策略是BlockingWaitStrategy。BlockingWaitStrategy使用一个典型的锁和条件变量来处理线程唤醒。BlockingWaitStrategy是等待策略中速度最慢的,但在CPU使用方面最为保守,并在多种不同环境下提供最一致的行为。
选择合适的等待策略,可以提高系统性能:
SleepingWaitStrategy
与BlockingWaitStrategy一样,SleepingWaitStrategy试图通过使用一个简单的忙等待来保守使用CPU。不同之处在于,忙等待期间,SleepingWaitStrategy调用LockSupport.parkNanos(1)暂停线程。在典型的Linux系统上,这将使线程暂停约60µs。
这样做的好处是,生产者线程不需要执行任何操作,只需增加适当的计数器,并且没有条件变量的开销。但是,生产者线程和消费者线程之间交换数据的平均延迟将更高。
它在不需要低延迟的情况下工作得最好,但会对生产线程产生一点小的影响。一个常见的例子是异步记录日志。
YieldingWaitStrategy
YieldingWaitStrategy是用于低延迟系统的两种等待策略之一。它选择消耗CPU周期来降低延迟。
YieldingWaitStrategy通过自旋的方式等待Sequence增加到合适的值。在循环内部,将调用Thread#yield(),以允许其他排队线程运行。
当需要非常高的性能,并且EventHandler线程数低于逻辑核心的总数时(例如,您启用了超线程),这是推荐的等待策略。
BusySpinWaitStrategy
BusySpinWaitStrategy是性能最高的等待策略。与YieldingWaitStrategy一样,它可以用于低延迟系统,但对部署环境的要求最高。
仅当EventHandler线程数低于机器上的物理内核数时,才应使用此等待策略,例如应禁用超线程。
从ring buffer中清除对象
当通过Disruptor传递数据时,数据对象可能比预期存活的更长。为避免发生这种情况,需要在处理事件后清除该数据。
如果只有一个事件处理程序,则在该处理程序中直接清除就可以了。如果是一个事件处理程序链,那么需要在链的末端放置一个特定的处理程序来清除对象。
事件对象:
class ObjectEvent<T>
{T val;void clear(){val = null;}
}
清理对象的处理程序,也就是消费者:
import com.lmax.disruptor.EventHandler;public class ClearingEventHandler<T> implements EventHandler<ObjectEvent<T>>
{public void onEvent(ObjectEvent<T> event, long sequence, boolean endOfBatch){//如果clear()执行失败,将导致事件对象里面的数据对象一直存活,直到被覆盖为止event.clear(); }
}
public static void main(String[] args){Disruptor<ObjectEvent<String>> disruptor = new Disruptor<>(() -> new ObjectEvent<>(), BUFFER_SIZE, DaemonThreadFactory.INSTANCE);disruptor.handleEventsWith(new ProcessingEventHandler()).then(new ClearingEventHandler());}
高级应用
处理大批量数据
public class EarlyReleaseHandler implements SequenceReportingEventHandler<LongEvent>
{private Sequence sequenceCallback;private int batchRemaining = 20;@Overridepublic void setSequenceCallback(final Sequence sequenceCallback){this.sequenceCallback = sequenceCallback;}@Overridepublic void onEvent(final LongEvent event, final long sequence, final boolean endOfBatch){processEvent(event);boolean logicalChunkOfWorkComplete = isLogicalChunkOfWorkComplete();if (logicalChunkOfWorkComplete){sequenceCallback.set(sequence);}batchRemaining = logicalChunkOfWorkComplete || endOfBatch ? 20 : batchRemaining;}private boolean isLogicalChunkOfWorkComplete(){//用于判断当前批次是否处理完成return --batchRemaining == -1;}private void processEvent(final LongEvent event){// Do processing}
}
这篇关于LMAX Disruptor User Guide的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








