本文主要是介绍Alexa Prize 2019 比赛及 Topical-Chat 数据集介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文将介绍 Alexa Prize Socialbot Challenge 2019 的比赛情况以及 Topical-Chat 数据集
Aelxa Prize 介绍
Alexa 是为 Amazon Echo 提供支持的语音服务,它使客户仅使用语音即可以更直观的方式与周围的世界互动。
Alexa Prize Socialbot Grand Challenge 是一项旨在促进对话 AI 发展的大学生竞赛,比赛中要求参赛队伍开发一个社交机器人(将作为 Alexa 的一项技能),可以在热门话题和新闻事件上与人类进行连贯和持续的互动交流。
参赛队伍的任务包括知识获取,自然语言理解,自然语言生成,上下文建模,常识推理和对话管理。具体来说,机器人需要具备的能力包括:1)自然的话题切换;2)合理地选择知识;3)能够将事实和观点(知识)融入到对话中。
参赛队伍的机器人将与全美 Alexa 用户进行对话,并且 Alexa 用户可以进行打分和反馈,来将帮助参赛队伍改进算法。
最终获胜的队伍将获得50万美金的大奖。
Alexa Prize 2019
Alexa Prize 从 2017 年开始,目前已经举办三届,第三届(即 Alexa Prize 2019)于不久前结束(2020年7月)。
时间安排
Alexa Prize 2019 整个比赛持续一年多,具体时间安排如下:
| 时间 | 事件 |
|---|---|
| 2019年3月-5月 | 队伍申请阶段 |
| 2019年6月 | 宣布参赛队伍(10支) |
| 2019年12月 | 向Alexa用户开放 |
| 2020年2月-3月 | 四分之一决赛(9支) |
| 2020年3月-4月 | 半决赛(5支) |
| 2020年5月-7月 | 决赛(3支) |
| 2020年7月 | 专家团评审 |
比赛结果
半决赛期间,所有队伍的平均得分(Alexa 用户评分,最高5分)为 3.47 分
| year | average score |
|---|---|
| 2017 | 2.91 |
| 2018 | 3.19 |
| 2019 | 3.47 |
来自埃默里大学的冠军队伍平均对话时长为 7分37秒
| award | final score | team | school | last |
|---|---|---|---|---|
| $500,000 | 3.81 | Emora | The Emory University | #4 |
| $100,000 | 3.17 | Chirpy Cardinal | Stanford University | - |
| $50,000 | 3.14 | Alquist | Czech Technical University | #2 |
Alexa 用户最感兴趣的话题(橙色)包括电影、科技和音乐;其中 Other 为其他主题,COVID-19 新冠病毒占比重较大

比赛过程中,参赛队伍将获得 Amazon 官方支持,包括 研究经费,Alexa 设备,AWS 服务等。除此以外,本次比赛还提供了对话机器人工具包(CoBot)以及主题对话数据集(Topical-Chat)。
Conversaton Bot (CoBot)
Advancing the State of the Art in Open Domain Dialog Systems through the Alexa Prize
系统图
CoBot 是一个对话式机器人工具包,提供一系列的基本模块和预训练模型供参赛队伍使用,可以最大程度上减少参赛队伍在基础架构部署和扩展上耗费的精力,
CoBot 的系统图和工作流程如下:
- Alexa Skill Kit 提供基本的语音技术功能,比如进行自动语音识别(ASR,automatic speech recognize)以及意图识别等功能
- AWS lambda 是 AWS 的无服务器接口,开发者可以定义基本的响应事件,来调用后续的触发模块
- AWS ECS 是 Amazon 的云服务,可以托管预训练等模型
- TTS 将文本转为语音(text-to-speech)

架构图
CoBot 内置默认的处理流程,包括主题分类、情感识别和NER等 NLU 模块功能,Evi QA 服务,以及全局的状态管理器(用 key-value 形式保存在 DynamoDB 中),开发者可以在此基础上开发自定义功能及模块。

-
Dialog Act and Topic Classification
-
使用基于 层次RNN(HRNN)的主题和意图联合分类模型(单层 GRU)

-
-
Neural Response Generation
-
基于 GPT-2 在 Topical-Chat 数据集上训练融入知识的生成模型
-
调用时,输入使用的知识以及对话历史,输出融入知识的回复

-
Topical Chat 数据集
Topical-Chat : Towards Knowledge-Grounded Open-Domain Conversations
基本介绍
Topical-Chat 是一个基于知识的人人对话数据集,其基础知识涵盖8个主题,包括多个知识来源(Washington Post Articles,Reddit fun facts,Wikipedia articles about entities)。
每轮对话标注了说话人情感以及回复的质量,总共包括 10,000 个会话(conversation),230, 000 轮对话(utterance)。
对话中没有明确定义参与者的角色(Wizard of Wikipedia, WoW 中存在一个 Wizard 进行对话引导),更符合开放域真实对话特点。
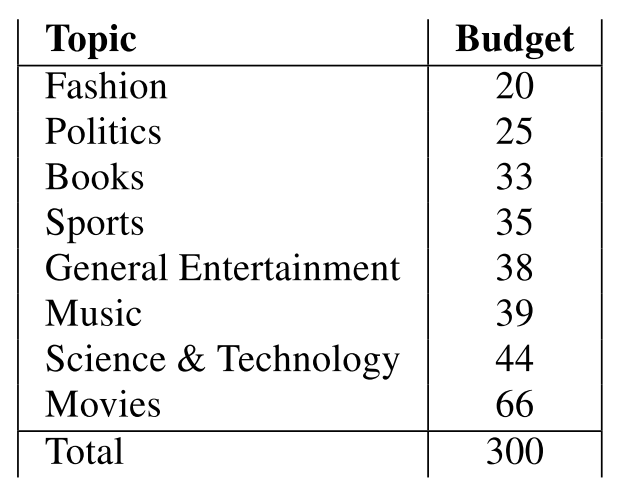
所有主题及对应的实体个数如下:
知识来源
知识库由三个原语构成:实体(entity),事实(fact)和文章(article),获取过程如下
- 实体选择(Entities Selection)
- 从前几届比赛用户的回复选择最受欢迎的 8 个主题共300个实体
- 事实选择(Fact Selection)
- 获取 300个实体的 Wikipedia 引言部分,然后使用 Reddit 众包为每个实体构造 8-10 个有趣的事实(根据 Wikipedia 引言构造)
- 对于每个实体,构造两个版本的 Wikipedia 引导部分,第一个是包含引导部分第一句话的短版本(50词),第二个是使用 TextRank 生成引导部分的摘要介绍(150 词)
- 文章选择(Article Selection)
- 获取 Washington Post 自2018年以来的文章(600-1000词),总共 3088篇文章,每篇文章至少包含三个上述的实体
知识集构造中,以article作为基础,并且构造多种信息不对称的知识集,并提供给对话双方使用(双方知识集可能不对称,模拟现实情况)。
对话构造过程中,每个实体包含 wikipedia 的短介绍或者摘要介绍以及有趣的事实,过程中对当前回复进行情感标注(Angry, Disgusted, Fearful, Sad, Happy, Surprised, Curious to Dive Deeper, Neutral),以及对对话上一个回复的知识使用进行质量评估(Poor,Not Good,Passable,Good and Excellent)。
数据获取
从 GitHub alexa/Topical-Chat 下载,需要构造知识源数据,过程如下
-
reddit 偏好设置 创建 API Key
参考 Instructions for getting Reddit API keys? #1

-
运行命令
# Ensure that your Python Interpreter >= 3.7 git clone https://github.com/alexa/Topical-Chat.git cd Topical-Chat/src pip install -r requirements.txt# Building the data requires Reddit credentials. # Please create your own Reddit API keys: https://www.reddit.com python3 build.py --reddit_client_id CLIENT_ID --reddit_client_secret CLIENT_SECRET --reddit_user_agent USER_AGENT -
构造过程(科学上网,用时2个小时)

数据示例
数据集中包含 frequent 和 rare 两种验证集,前者中的实体在训练集中频繁出现,后者在训练集中较少甚至没有出现过
| Train | Valid Freq. | Valid Rare | Test Freq. | Test Rare | All | |
|---|---|---|---|---|---|---|
| # conversations | 8628 | 539 | 539 | 539 | 539 | 10784 |
| # utterances | 188378 | 11681 | 11692 | 11760 | 11770 | 235434 |
| average # turns per conversation | 21.8 | 21.6 | 21.7 | 21.8 | 21.8 | 21.8 |
| average length of utterance | 19.5 | 19.8 | 19.8 | 19.5 | 19.5 | 19.6 |
-
对话文件
{ <conversation_id>: {"article_url": <article url>,"config": <config>, # one of A,B,C, D"content": [ # ordered list of conversation turns{ "agent": "agent_1", # or “agent_2”,"message" : <message text>,# Angry, Disgusted, Fearful, Sad, Happy, Surprised, Curious to Dive Deeper, Neutral"sentiment": <text>, # Factual Section 1-3, Article Section 1-4 and/or Personal Knowledge"knowledge_source" : ["AS1", "Personal Knowledge",...], "turn_rating": "Poor", # Note: changed from number to actual annotated text},…],"conversation_rating": {"agent_1": "Good", # Poor, Not Good, Passable, Good and Excellent"agent_2": "Excellent"}},...... } -
知识集合
{ <conversation_id> : {"config" : <config>,"agent_1": {"FS1": {"entity": <entity name>,"shortened_wiki_lead_section": <section text>,"fun_facts": [ <fact1_text>, <fact2_text>,...]},"FS2": {...}},"agent_2": {"FS1": {"entity": <entity name>,"shortened_wiki_lead_section": <section text>,"fun_facts": [ <fact1_text>, <fact2_text>,...],},"FS2": {...}},"article": {"url": <url>,"headline" : <headline text>,"AS1": <section 1 text>,"AS2": <section 2 text>,"AS3": <section 3 text>,"AS4": <section 4 text>}} ... }
这篇关于Alexa Prize 2019 比赛及 Topical-Chat 数据集介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






