本文主要是介绍「从零入门推荐系统」18:Netflix prize推荐系统代码实战案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者 | gongyouliu
编辑 | gongyouliu
我们在前面章节将推荐系统的基本概念、算法原理、工程实践等相关的核心知识点都讲完了。从本章开始,我们会用3章的篇幅讲解推荐系统的具体代码实现。由于本系列是推荐系统入门课程,所以一定量的代码案例对读者从零开始熟悉推荐系统是非常有必要的。读者可以跟着作者的节奏去详细了解具体的实现过程,如果能够在这个基础上进行拓展和完善,那更好了。
第18章会讲解一个最古典的推荐系统代码案例。最古典的推荐系统案例要属Netflix Prize竞赛(2006年-2009年)了,正是这次竞赛才让推荐系统从学术界走向工业界,也奠定了国内以头条为首的将推荐系统作为产品核心功能的大厂最近十年的大爆发,这即是本章主要讲解的主题。
本章我们会从Netflix prize竞赛、Netflix prize数据集、数据预处理、推荐系统算法实现等4个部分来讲解。其中推荐系统算法实现是核心部分,在这个部分我们会讲解7个召回算法和4个排序算法,读者需要很好地掌握。
第19章会讲解一个较现代的推荐系统案例,是Kaggle在去年发布的H&M服装推荐系统,这个案例给到的数据更多样,我们在这一章会讲解一些更复杂的召回、排序算法,并且这一章的所有算法跟本章讲解的不会重叠。
第20章会讲解前面两章涉及到的各种召回、排序算法怎么部署成Web服务,这样才能让推荐系统真正服务于业务。另外,我们也会讲解推荐系统评估相关的知识点。
这章3中的所有代码都是作者亲自写的,通过写这些代码也让作者再一次体验到了实现推荐系统的乐趣。希望这3章的代码案例可以给读者提供一些参考,也希望读者多参与一些开源的推荐系统竞赛,来加深自己对推荐系统技术及业务的理解。
注:目前的代码是以实现功能为主,代码结构还不够完善,等所有代码优化好之后,作者会上传到github上,到时候读者可以克隆下来学习。具体github上的工程地址为:https://github.com/liuq4360/recommender_systems_abc。
18.1 Netflix prize竞赛简单介绍
Netflix prize竞赛是Netflix在2006年启动的一项竞赛,他们提供真实的Netflix用户行为数据,希望参赛团队将RMSE这个离线评估指标(我们在第15章介绍过RMSE)提升10%,最先做到的团队获得100万美元的奖励。这个竞赛从启动到最终获奖经历了3年时间,最后是3个团队将模型融合构建一个混合模型(对这3个团队的论文感兴趣的读者可以阅读参考文献1、2、3),在2009年获得100万美元。
在这次竞赛中有非常多的新的推荐思路被提出,其中大家耳熟能详的矩阵分解推荐算法最早就是在这个竞赛过程中提出来的。作者最早在2010年研究推荐系统时,就开始用MATLAB分布式计算实现了好几个比较主流的推荐系统模型。下面我们利用这个竞赛中的数据集从零开始实现几个简单易懂并且也是很有实用价值的召回、排序算法模型。有兴趣的读者可以基于该数据集去实现更加复杂的模型。
18.2 Netflix prize竞赛数据集介绍
首先我们介绍一下Netflix prize竞赛数据集,该数据集主要包含如下几个文件,其中README是对数据集的简单介绍,training_set是训练数据集(原始数据比较大,mini_training_set是我自己构建的一个小一点的子集),主要就是用户行为数据(包括用户id、电影id和对电影的打分),movie_titles.txt是电影metadata数据,qualifying.txt是给参赛者用于预测的(Netflix prize是预测电影评分,从1到5一共5分制),你可以将你的预测结果提交给Netflix,然后它们会计算RMSE,看你能不能赢得大奖。probe.txt数据集让你在提交算法之前可以事先验证算法在该数据集上的RMSE,方便读者自己大致知道自己算法的效果。rmse.pl是一个简单计算RMSE的代码。

图1:Netflix prize数据集
我们重点说一下比较重要的两个数据集。其中training_set的数据形式参考下面图2,movie_titles.txt数据集的具体形式参考下面图3。具体各个数据集的介绍读者可以阅读README文件,这里不展开讲解。
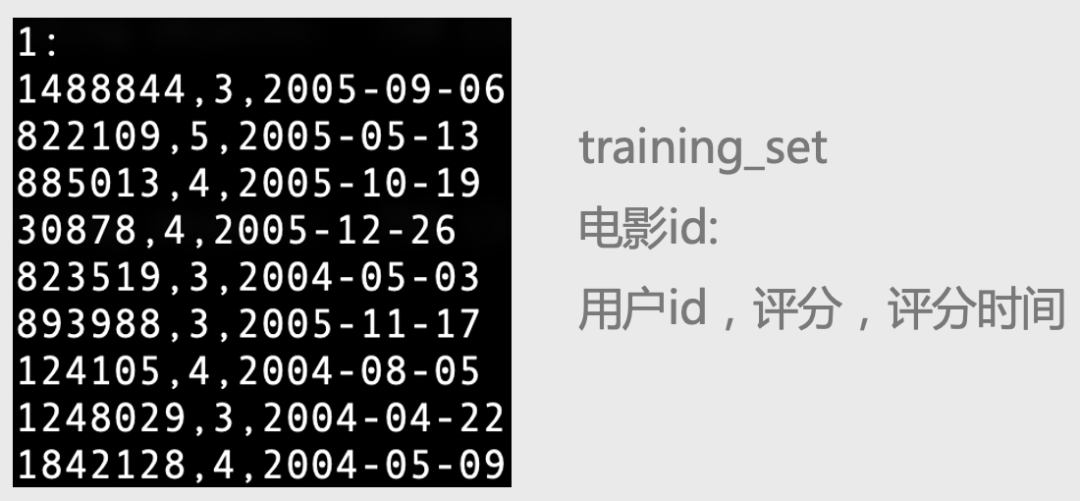
图2:training_set数据格式

图3:movie_titles.txt数据格式
可以看到,Netflix prize竞赛的数据集还是非常简单的,主要以用户行为数据为主,电影信息也不多,只有发布年代和标题,没有用户画像相关数据。由于数据不够多元化,能够实现的算法会比较受局限。介绍完了数据,我们下面简单讲讲数据预处理,这些处理的目的是方便后面的各种召回、排序算法的实现。
18.3 数据预处理
数据预处理步骤主要的目的是对原始数据进行转换,方便后面构建推荐模型。下面我们分别对下图中的4个预处理函数进行简单说明,具体细节读者可以查看代码。
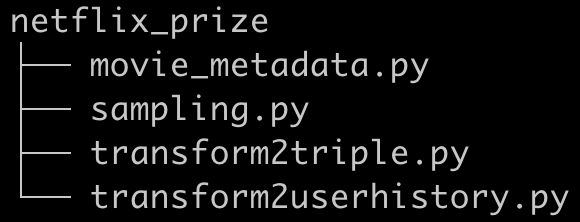
图4:数据预处理函数
上面的movie_metadata.py将原始的movie_titles.txt数据处理为{1781:(2004,Noi the Albino), 1790:(1966,Born Free)}这样的数据格式。sampling.py是将行为数据按照7:3分为训练集和测试集。transform2triple.py会将训练数据处理为(user_id, video_id , score ) 这样的三元组格式。transform2userhistory.py会将训练数据处理为{2097129: set([(3049, 2), (3701, 4), (3756, 3)]), 1048551: set([(3610, 4), (571, 3)])}这样的格式(其中key是用户id,value是该用户评分过的所有电影及评分构成的集合)。
18.4 推荐系统算法实现
下面我们针对Netflix prize数据集讲解我们实现的各种召回、排序算法。由于Netflix prize数据集年代比较早,给出的数据不够丰富(只有用户行为数据和电影年代标题数据),所以这里我们实现的都是非常基础、非常简单的召回排序算法(不过都是很实用的算法),更复杂的召回、排序算法我们留到下一章来讲解和实现。
18.4.1 召回算法
本节我们介绍Netflix prize数据集实现的7个召回算法,这里我们只讲算法的基本原理、实现思路和部分核心代码,具体的代码细节读者可以参考以后我们发布到github上的recommender_systems_abc中的具体实现。为了方便读者对照代码学习,这里先给出工程上的代码目录结构。
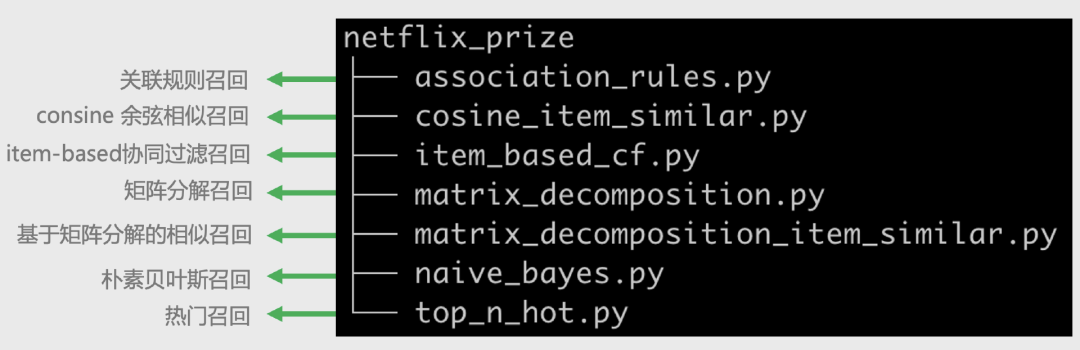
图5:7种召回算法对应的代码
18.4.1.1 热门召回
热门召回可以基于训练数据计算每个视频播放的评分之和,获得每个视频的总评分,然后按照总评分降序排列,最终取前面N个就可以了,计算逻辑非常简单,下面是具体的代码实现。这里的实现非常简单,没有考虑不同电影发布的时间不一样,对最新的电影可能不公平,读者也可以想想怎么优化这个热门召回的实现方案。
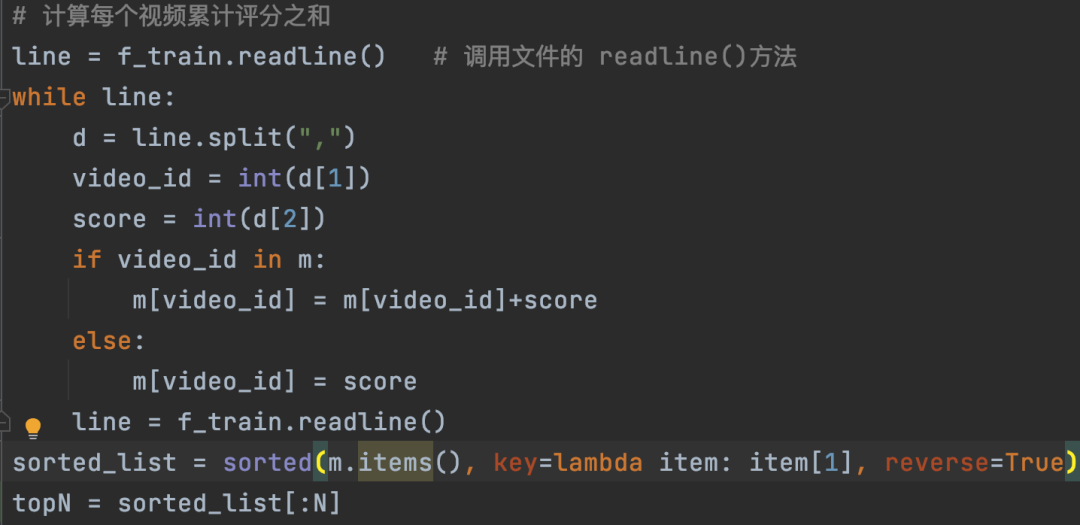
图6:热门召回的代码实现逻辑
18.4.1.2 consine余弦相似召回
consine余弦相似召回的计算逻辑是:先基于用户行为构建成用户行为矩阵,矩阵的列向量就可以看成是电影的表示向量,即每个电影可以看成一个向量,参考下图。
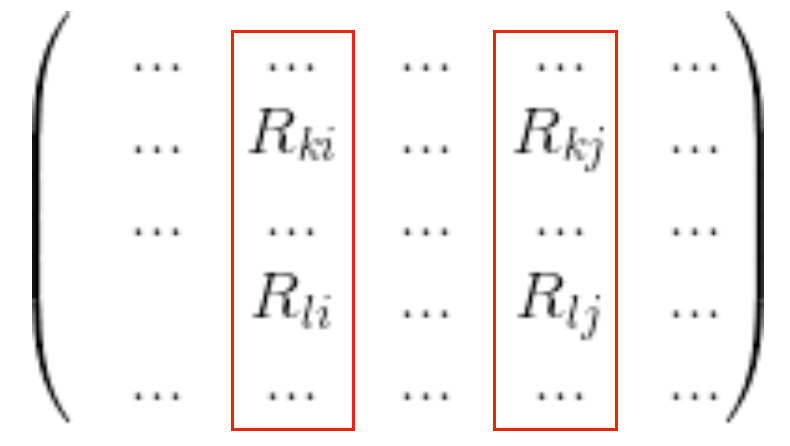
图7:由用户行为矩阵构建的电影列向量表示
基于consine余弦可以计算两个电影的相似度,然后针对某个电影,计算它与所有其它电影的consine余弦相似度,然后按照相似度降序排列,最终取相似度最大的N个,就是与该电影最相似的电影了。
下面简单说一下代码实现的步骤。代码实现主要包含如下4步(见图8),前面3步的代码很简单,大家可以基于下面的步骤对照github上的代码看看就可以了,这里不展开讲解。我们重点说一下第4步的实现,实现细节在图9中,读者应该可以很容易看懂,我们不赘述。

图8:计算consine余弦相似的步骤
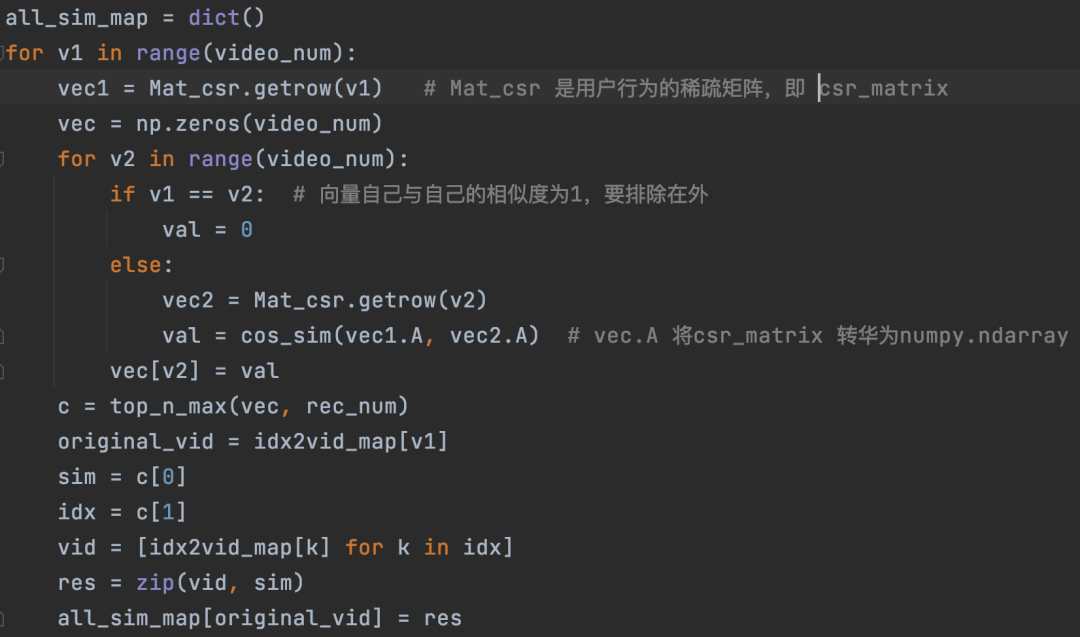
图9:为每个视频利用consine余弦计算topN召回
这里提一下步骤2为啥要生成自然数的映射关系,因为原始数据的视频id很大,构建的矩阵规模会更大,映射为从0开始的自然数,会降低矩阵规模。我们代码实现过程中用的稀疏矩阵,即使不做映射应该对存储和性能没有太大影响,但是如果是另外的数据集,视频id是字符串,那么就必须进行映射了,所以我们这里就提前实现了这种映射逻辑。
18.4.1.3 item-based协同过滤召回
item-based协同过滤的原理之前也讲过,这里只放具体公式(下面公式中S是用户观看集合,u代表用户,s代表视频),忘记的读者可以参考第8章《召回算法之5类基础召回算法》。
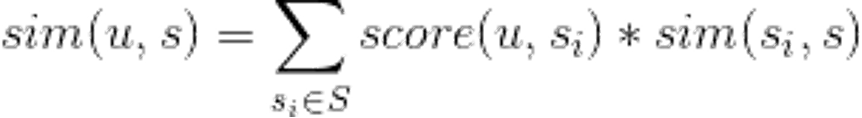
具体代码实现需要先计算出每个视频最相似的N个视频(采用18.4.1.2节的算法),即是下面代码中的similarity字典(这个计算结果我们也可以存到Redis中,采用sorted_set数据结构),其中play_action是在数据预处理阶段获得的,具体数据结构参考下图第一行。代码实现比较简单,读者可以基于上面的公式和下面图10对照一下,很容易就可以看懂了。
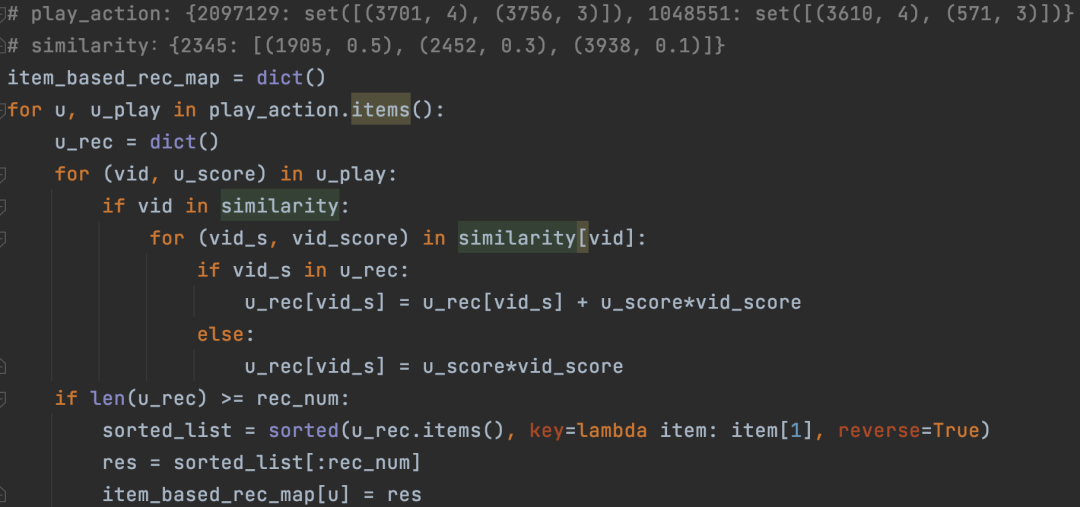
图10:item-based协同过滤召回的核心代码
18.4.1.4 矩阵分解召回
矩阵分解召回算法我们这里没有从零开始实现,而是采用了implicit这个开源库(参考文献4),这个库实现了比较主流的ALS矩阵分解算法(关于ALS矩阵分解算法,读者可以参考第8章8.5节的详细介绍)。implicit这个库的具体用法需要读者自己去学习一下,其中提供了直接为用户计算个性化推荐的接口,下面我们贴出实现的核心代码。
为了方便大家看懂,对下面图11中代码部分进行简单解释。其中plays是用户行为矩阵,采用的是scipy.sparse 库中 csr_matrix 矩阵(具体plays的构建过程读者自己看源代码,另外csr_matrix读者自行学习了解,这里不展开)。我们为每个用户计算的推荐是放到了mf_rec_map这个字典中,在实际业务中,我们可以存到放Redis中,采用sorted_set数据结构存储。
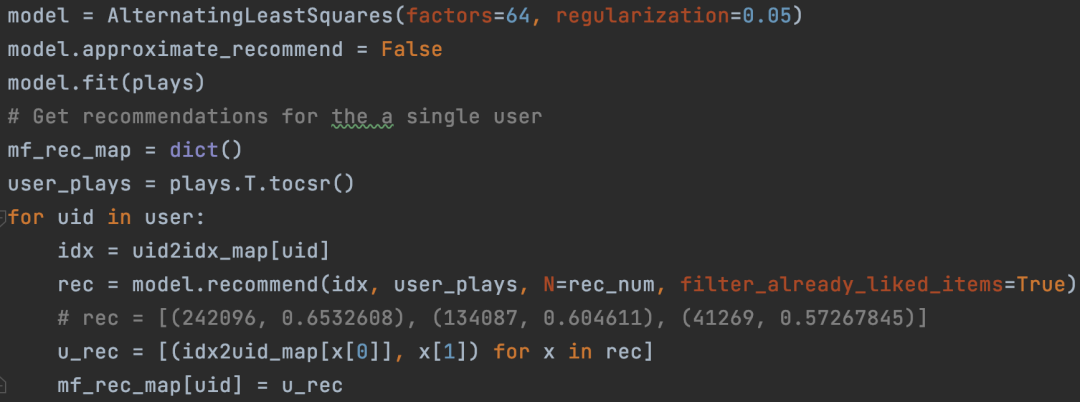
图11:ALS矩阵分解为每个用户计算个性化召回
18.4.1.5 基于矩阵分解的相似召回
这个是基于矩阵分解计算视频相似性。通过矩阵分解可以获得视频特征向量,那么就可以基于视频特征向量,采用计算consine余弦相似类似的方法(即18.4.1.2节的介绍)计算视频topN相似了(具体实现方案参考第8章8.5.1节的介绍)。implicit库中直接提供了具体的函数实现,非常方便,下面贴出实现的核心代码。
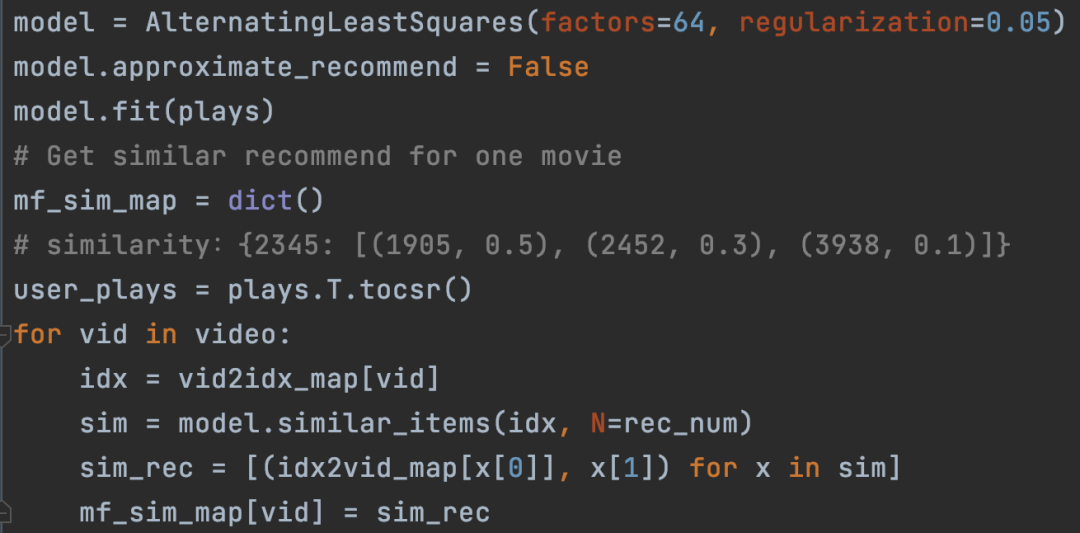
图12:ALS矩阵分解为每个电影计算相似召回
18.4.1.6 关联规则召回
我们在第8章的8.1节中对利用关联规则进行个性化召回的算法原理进行了介绍,不熟悉的读者可以看看那一章回顾一下。下面简单说明一下具体的代码实现细节。
我们计算关联规则的算法采用的是FP-Growth(见参考文献5、6),利用Python的开源pyfpgrowth包计算,这部分代码很简单,这里不展示,想了解的读者可以看参考文献7。挖掘出了关联规则,剩下的工作就是怎么基于用户行为和关联规则进行推荐。我们实现的方式跟8.1节介绍的思路基本是完全一样的,具体代码见下面图13。
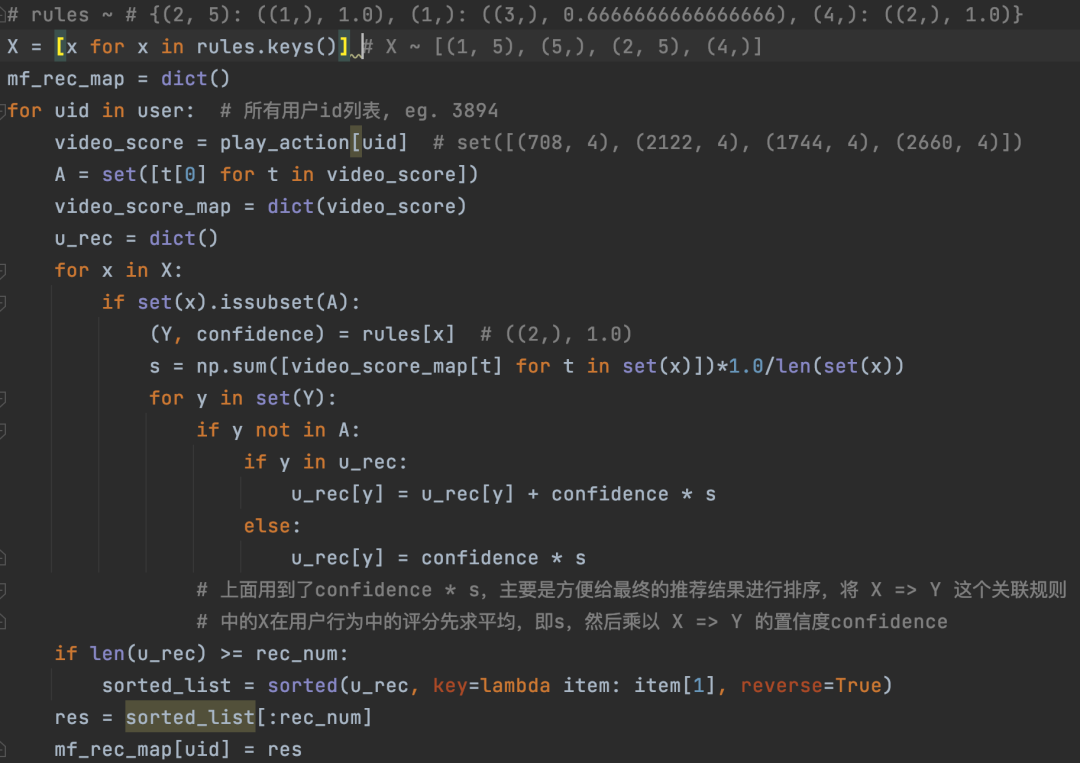
图13:利用关联规则为每个用户进行召回
18.4.1.7 朴素贝叶斯召回
我们在第8章的8.3节中对朴素贝叶斯算法原理进行了介绍,最终可以推导出如下的计算公式(读者可以自行推导一下,还是很容易的),下面先对公式加以说明,方便大家更好理解。
其中,![]() 是用户u对视频v评分为s的概率,
是用户u对视频v评分为s的概率,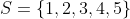 是所有可能的评分。
是所有可能的评分。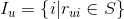 是用户
是用户![]() 有过评分的所有物品集,
有过评分的所有物品集,![]() 是用户u对视频v的评分。
是用户u对视频v的评分。
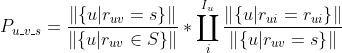
基于上面的公式,我们可以为每个用户 u,针对他没有评分过的视频 v,计算该视频被评分为s的概率值 ![]() ,然后可以用
,然后可以用 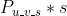 作为用户 u 对视频 v 的最终评分,公式如下:
作为用户 u 对视频 v 的最终评分,公式如下:
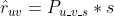
一旦有了用户 u 对每个视频 v 的评分,那么就可以基于评分降序排列,取topN,获得最终给用户u的个性化召回,具体代码实现如下(当然有一些细节上的特殊处理),具体实现细节,读者以后可以参考github代码仓库。
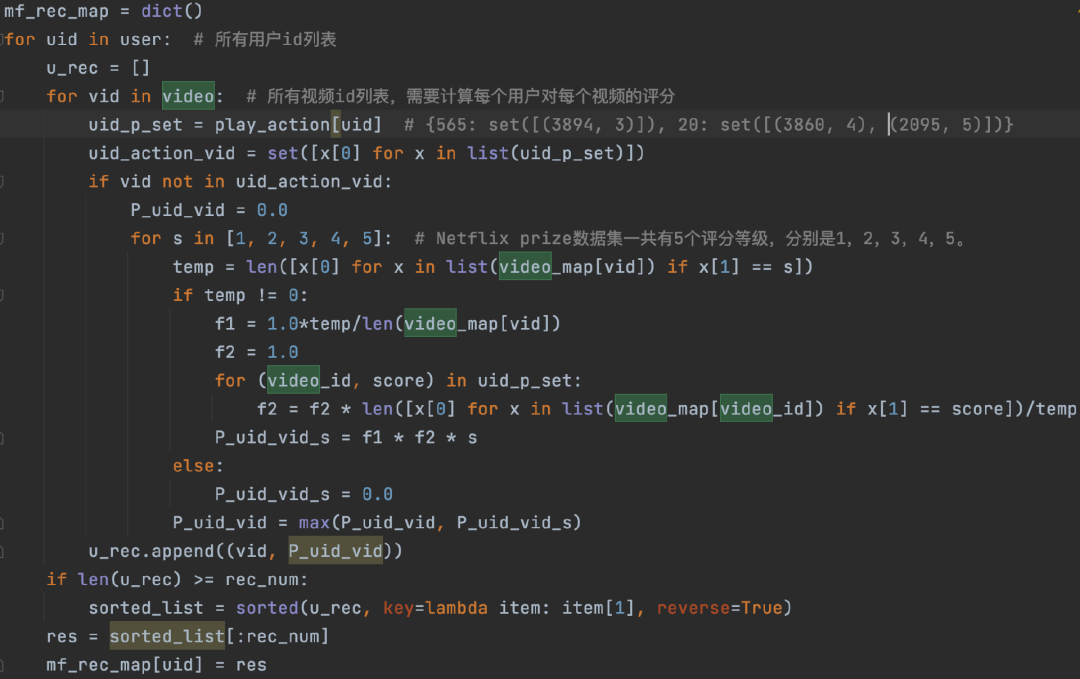
图14:朴素贝叶斯召回算法核心代码实现
18.4.2 排序算法
由于Netflix prize数据集提供的信息不是很多,我们不太容易实现非常复杂的排序算法,所以在本节我们实现4个非常简单的、但是也是很实用的排序算法。本节讲解的4个排序算法与我们的代码仓库中的函数对应关系参考下面图15。这里面提到的所有算法的实现原理之前已经在第11章中有介绍,不熟悉的读者可以重新了解一下。这里提一下,上面一节介绍的7个召回算法都可以作为下面介绍的排序算法的输入(工业级推荐系统一般采用多路召回,然后再接一个排序算法,最终获得给用户的推荐,具体业务流程,读者可以参考第5章《推荐系统业务流程与架构》)。
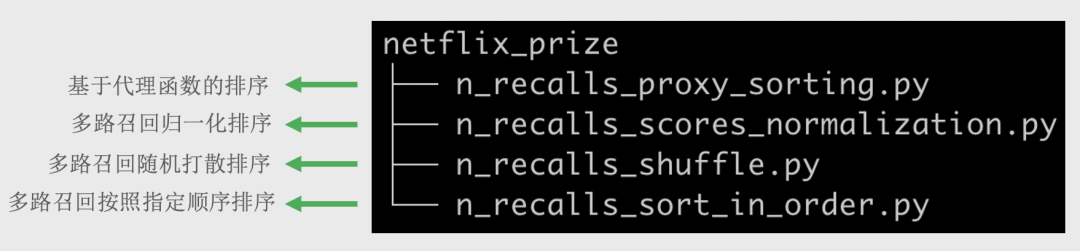
图15:排序算法名称对应关系
18.4.2.1 基于代理函数的排序
所谓代理函数,是一个可以评估视频质量的函数,基于这个函数对多路召回的结果进行排序,然后取topN获得最终的推荐结果。
针对Netflix prize数据集,我们可以算出每个电影的发行年代及每个电影的平均评分和总播放次数。利用这3个数据,采用下面图16中连乘的方式计算代理函数值,保证年代越新、平均评分越高、播放次数越多的电影评分越高,这样的电影会排在前面。
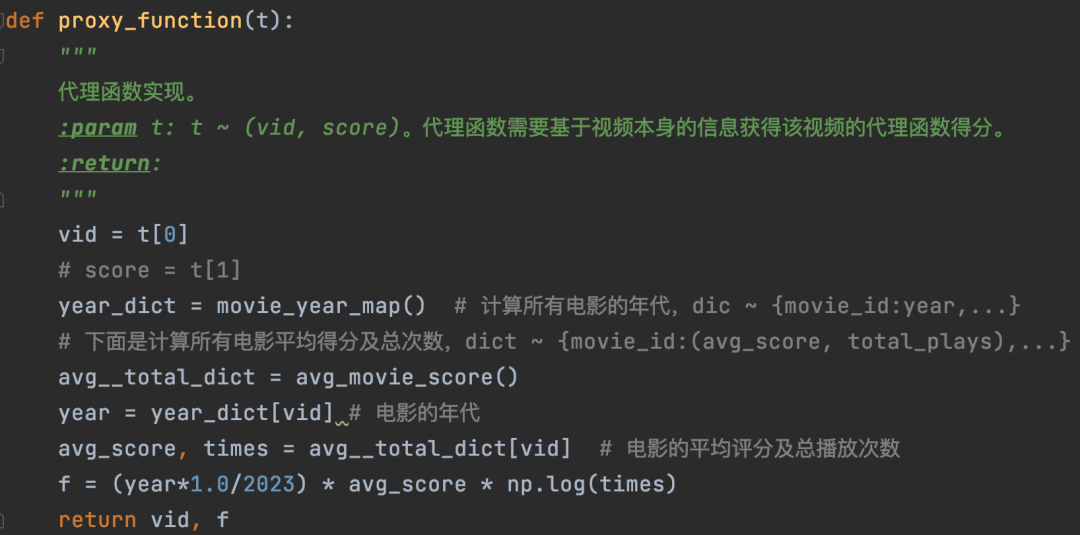
图16:代理函数的代码实现
有了上面的代理函数,从多路召回结果进行排序的实现方案就非常简单了。只要为每个召回列表中的视频计算代理函数值,这个值作为该视频的最终评分。最终所有召回的视频按照代理值降序排列就可以了。具体实现逻辑参考图17中的核心代码。
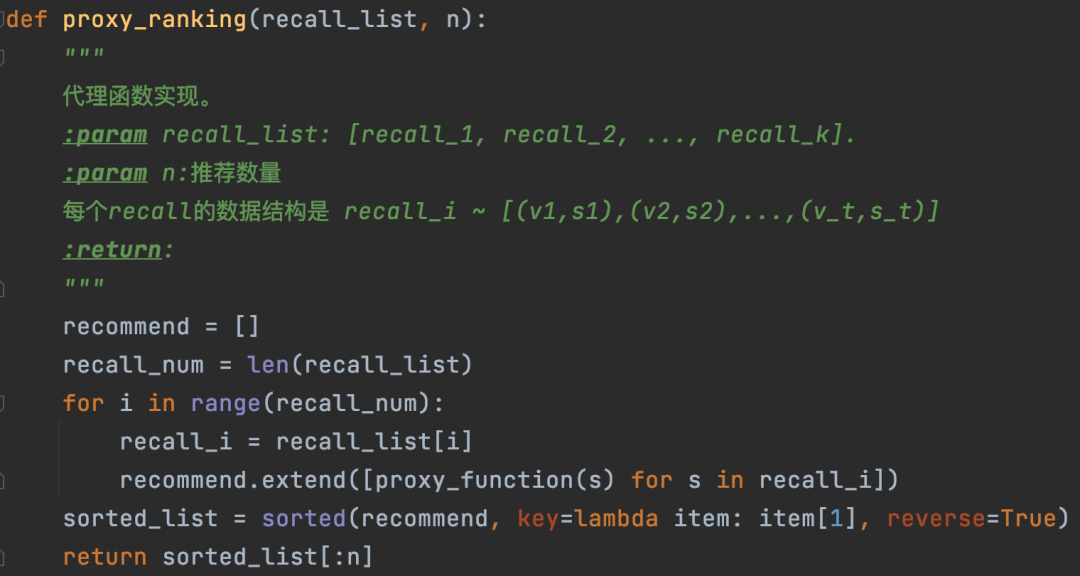
图17:基于代理函数的多路召回排序
18.4.2.2 多路召回归一化排序
我们这里用正态分布归一化排序。就是先将每路召回的推荐结果先按照正态分布归一化,公式如下,其中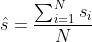 ,
, ![]() 是
是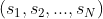 的标准差。
的标准差。
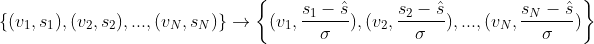
然后多路召回都进行上述变换后,将它们的推荐结果进行合并(如果有重复的,那么得分可以求和,重复说明多个召回算法都推荐了,这样的候选集是更好的选择),最终再统一降序排列,取topN作为最终的推荐结果。下面图18、19分别是正态分布归一化和多路召回归一化排序的代码实现。
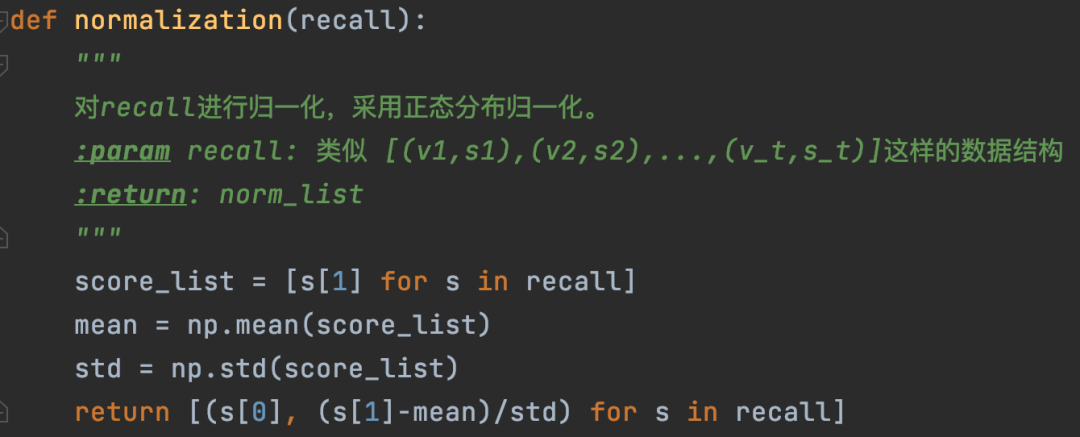
图18:对单路召回进行正态分布归一化
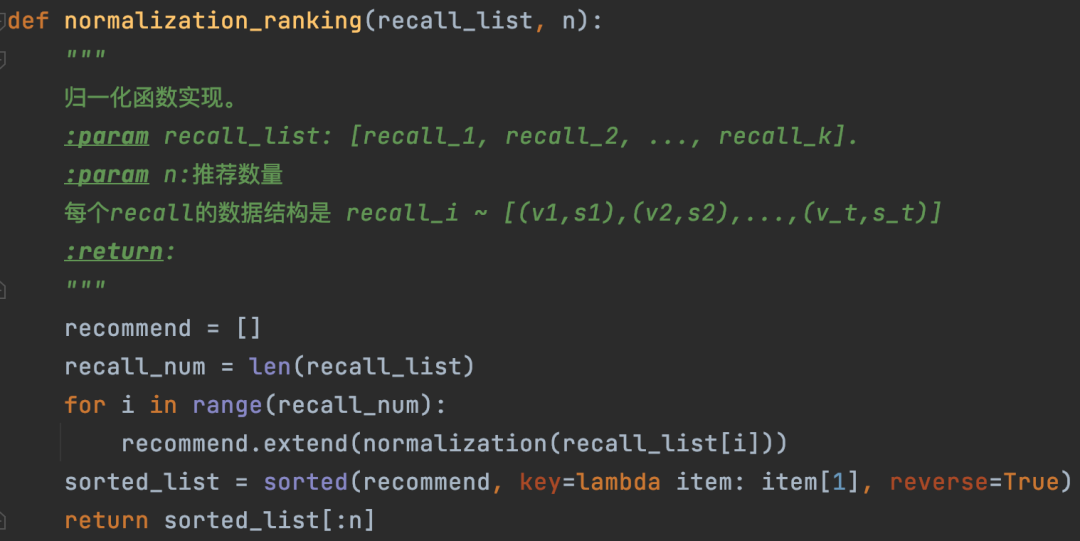
图19:利用归一化来进行多路召回排序
18.4.2.3 多路召回随机打散排序
这个方法更简单,就是将多路召回结果丢到一起,不考虑待推荐的候选集的得分,直接随机打散取topN作为最终推荐结果。这个方法非常简单,最大的价值是可以增加推荐的多样性,具体代码实现参考下面图20。这里说明一下,最终推荐的结果中是包含视频的得分的,不过这个得分是各个召回获得的得分,不具备可比较性,也不是按照降序排列的(因为是随机打散了)。
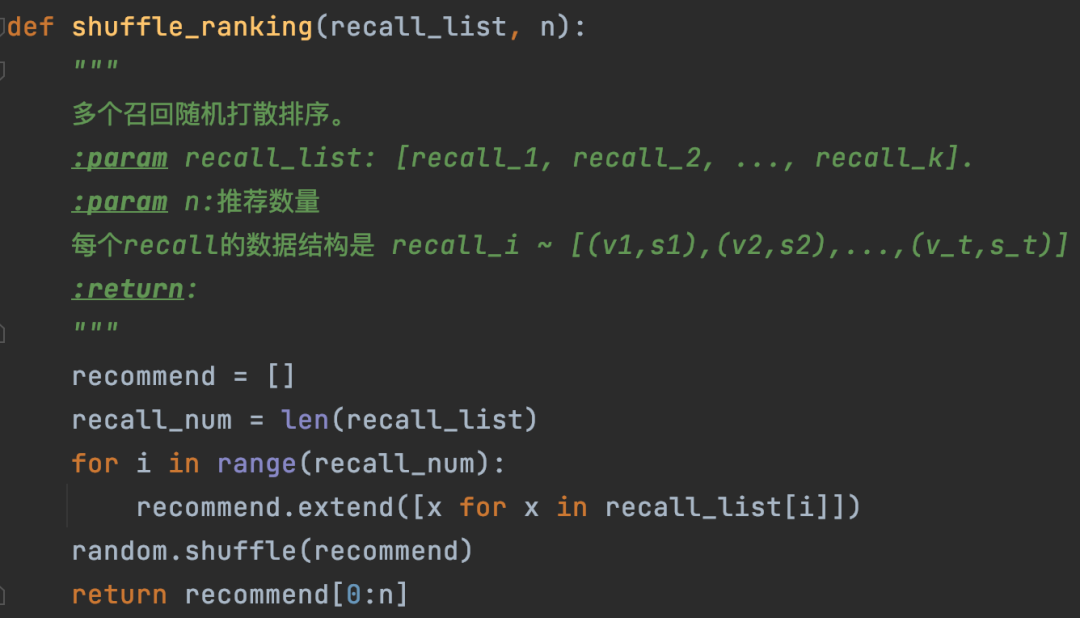
图20:按照多路召回随机打散排序
18.4.2.4 多路召回按照指定顺序排序
如果我们的k个召回有如下的次序关系(某些召回效果更好、更优):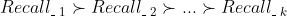 ,那么就可以按照这个次序依次从每个召回中选择n(为了简单起见,我们这里选取n=1)个来排成一列,直到选择的数量达到最终需要的数量N为止。具体的代码实现可以参考下面图21。
,那么就可以按照这个次序依次从每个召回中选择n(为了简单起见,我们这里选取n=1)个来排成一列,直到选择的数量达到最终需要的数量N为止。具体的代码实现可以参考下面图21。
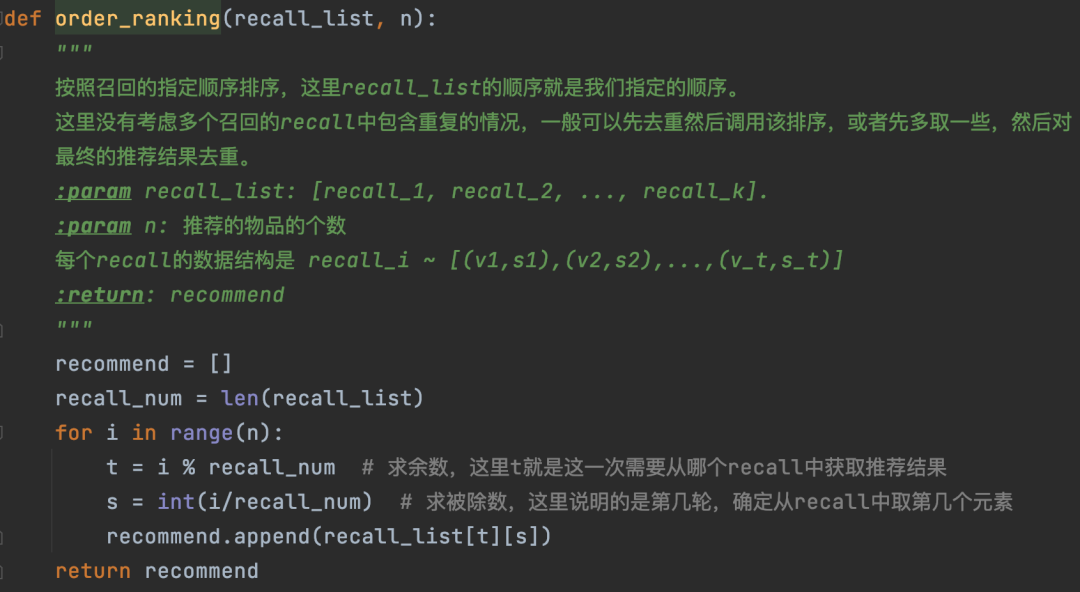
图21:按照多路召回的指定顺序排序
总结
本章我们以Netflix prize竞赛数据集为基础,构建了7类召回算法和4类排序算法。由于Netflix prize竞赛数据集是最早的推荐系统开源数据,数据形式比较单一,只有用户行为数据及电影年代、电影名,所以可以做的推荐算法是比较有限的。
本章实现的召回、排序算法都是比较基础的算法,不过他们在某些场景下也是非常实用的。这一系列文章作为入门基础文章,也非常适合初学者跟着作者的思路来逐步熟悉推荐系统的各种算法。我们在下一章会利用更现代、更多样化的数据构建更复杂的召回、排序算法。
参考文献
[2009] The BellKor Solution to the Netflix Grand Prize
[2009] The BigChaos Solution to the Netflix Grand Prize
[2009] The Pragmatic Theory solution to the Netflix Grand Prize
https://github.com/benfred/implicit
Haoyuan Li, Yi Wang, Dong Zhang, Ming Zhang, and Edward Y. Chang. 2008. Pfp: parallel fp-growth for query recommendation
Jiawei Han, Jian Pei, and Yiwen Yin. 2000.Mining frequent patterns without candidate generation.
https://fp-growth.readthedocs.io/en/latest/readme.html
大家如果对推荐系统感兴趣,可以点击下面链接购买我出版的图书《构建企业级推荐系统》,全面深入地学习企业级推荐系统的方法论。

这篇关于「从零入门推荐系统」18:Netflix prize推荐系统代码实战案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





