本文主要是介绍数据禾|2019年河北省耕地分布数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
河北省环抱首都北京,总面积18.85万平方公里,省会石家庄市。北距北京283公里,东与天津市毗连并紧傍渤海,东南部、南部衔山东、河南两省,西倚太行山与山西省为邻,西北部、北部与内蒙古自治区交界,东北部与辽宁省接壤。河北省地势西北高、东南低,由西北向东南倾斜。地貌复杂多样,高原、山地、丘陵、盆地、平原类型齐全,有坝上高原、燕山和太行山山地、河北平原三大地貌单元。
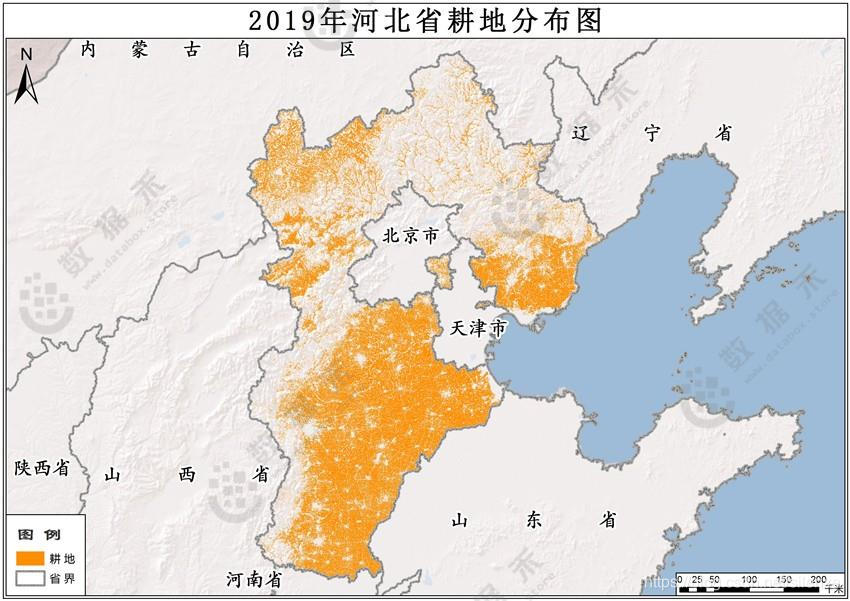
河北省2019年耕地分布数据,是通过采集河北省2019年多期的长序列多光谱遥感影像(包括陆地卫星系列、哨兵卫星系列、高分卫星系列等),基于影像中农业种植用地的几何形状、颜色特征、纹理特征以及空间分布特性等建立相应训练样本库,结合农作物的时间发展特点,利用随机森林等计算机智能算法监督分类得到的。河北省2019年耕地遥感解译样方库,是在覆盖不同时间节点特征的基础上,经过多次样本大小和样本数量的调整得到的,该样本库类型覆盖全面、数量丰富。分类结果参考多期影像进行人工局部修正,最终在河北省全域基于混淆矩阵完成总体精度检验。
2019年河北省耕地分布数据,主要涵盖的农业种植用地类型为旱地、水田和温室大棚。该数据数学基础采用GCS_WGS_1984空间参考坐标系,格式为栅格,空间分辨率为10米,空间范围覆盖全河北省,总体精度在78.2%以上。
这篇关于数据禾|2019年河北省耕地分布数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





