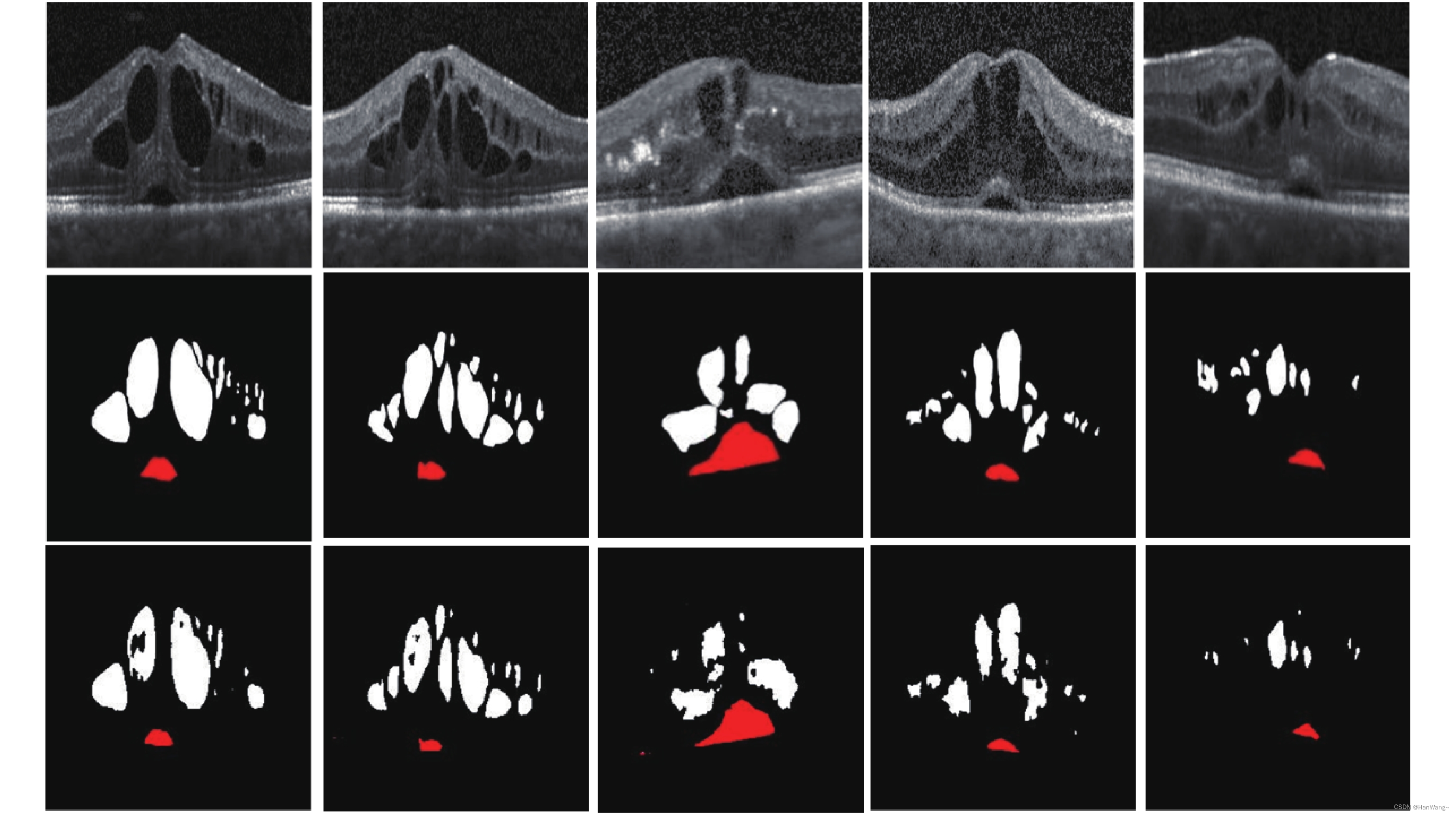
本文主要是介绍DUKE大学BOE数据集 OCT图像积液分割数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用此数据集用来做积液分割研究
地址:http://people.duke.edu/~sf59/Chiu_BOE_2014_dataset.htm
使用python将.mat转换为图片格式
#对BOE .MAT格式文件处理成图片
import cv2
import scipy.io as scio
import os# [0,1]=>[0,255]
def changeImg(gray):H, W = gray.shapefor i in range(0, W):for j in range(0, H):if gray[j, i] != 0:gray[j, i] = 255return grayfolder = 'BOE/2015_BOE_Chiu'
path = os.listdir(folder)
srcdst = 'BOE/img/srcimg/'
m1dst = 'BOE/img/m1img/'
m2dst = 'BOE/img/m2img/'for each_mat in path:print(each_mat)first_name, second_name = os.path.splitext(each_mat)print('mat名',first_name,first_name[-2:])# 拆分.mat文件的前后缀名字,注意是**路径**# breakeach_mat = os.path.join(folder, each_mat)array_struct = scio.loadmat(each_mat)img_data = array_struct['images'] # 原图像src_count = img_data.shape[2] #图像个数# print(img_data[0][0],img_data[1],img_data[2])for i in range(src_count):cv2.imwrite(srcdst + first_name[-2:] + '/img' + first_name[-2:] +'index'+str(i)+ '.jpg', img_data[:, :, i])manual1_data = array_struct['manualFluid1'] # 标注1m1_count = manual1_data.shape[2] #图像个数for i in range(m1_count):manual1_img = changeImg(manual1_data[:, :, i])cv2.imwrite(m1dst + first_name[-2:] + '/img' + first_name[-2:] + 'index' + str(i) + '.jpg', manual1_img)manual2_data = array_struct['manualFluid2'] # 标注2m2_count = manual2_data.shape[2] #图像个数for i in range(m2_count):manual2_img = changeImg(manual2_data[:, :, i])cv2.imwrite(m2dst + first_name[-2:] + '/img' + first_name[-2:] + 'index' + str(i) + '.jpg', manual2_img)# break
更新
2022-6-2
鉴于大家由于代码执行失败造成分割不成功的情况,留言给我要数据集。
我把数据集上传了,在这个链接https://download.csdn.net/download/baidu_37336262/85524491,积分设置5积分,没有积分下载的再留言找我要吧,看到就回。
PS:同学们点点关注,点点赞,我的博客收藏比关注多,emo…
这篇关于DUKE大学BOE数据集 OCT图像积液分割数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




