本文主要是介绍Win11基于python,利用Spleeter实现人声音频分离(详细教程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
初衷:
由于前段时间在工作过程中急需实现人声音乐分离的功能,上网搜索一番,也是无意中接触到这个工具,于是搜索了安装和使用教程,奈何系统版本或者其他未知原因,导致这个过程异常的艰辛,不过好在最后还是成功了,以此记录一下,来帮助一些初学者,希望能让你们少走一些弯路。
版本说明:
- win11系统
- python环境3.9
- spleeter版本2.3.2
简单的安装流程:
- 安装python,配置环境,安装pip
- 安装库spleeter
- ffmpeg
- 下载预测模型
- 使用spleeter进行人声分离
详细的安装流程:
第一:安装python环境,这个比较简单,大家自己上网搜索一下教程,这边就不重复累述了。
第二:安装spleeter
- pip install spleeter 安装spleeter
第三:安装FFmpeg
- 去官网下在一下FFmpeg(Download FFmpeg),下面的截图是下载的页面的详细操作步骤
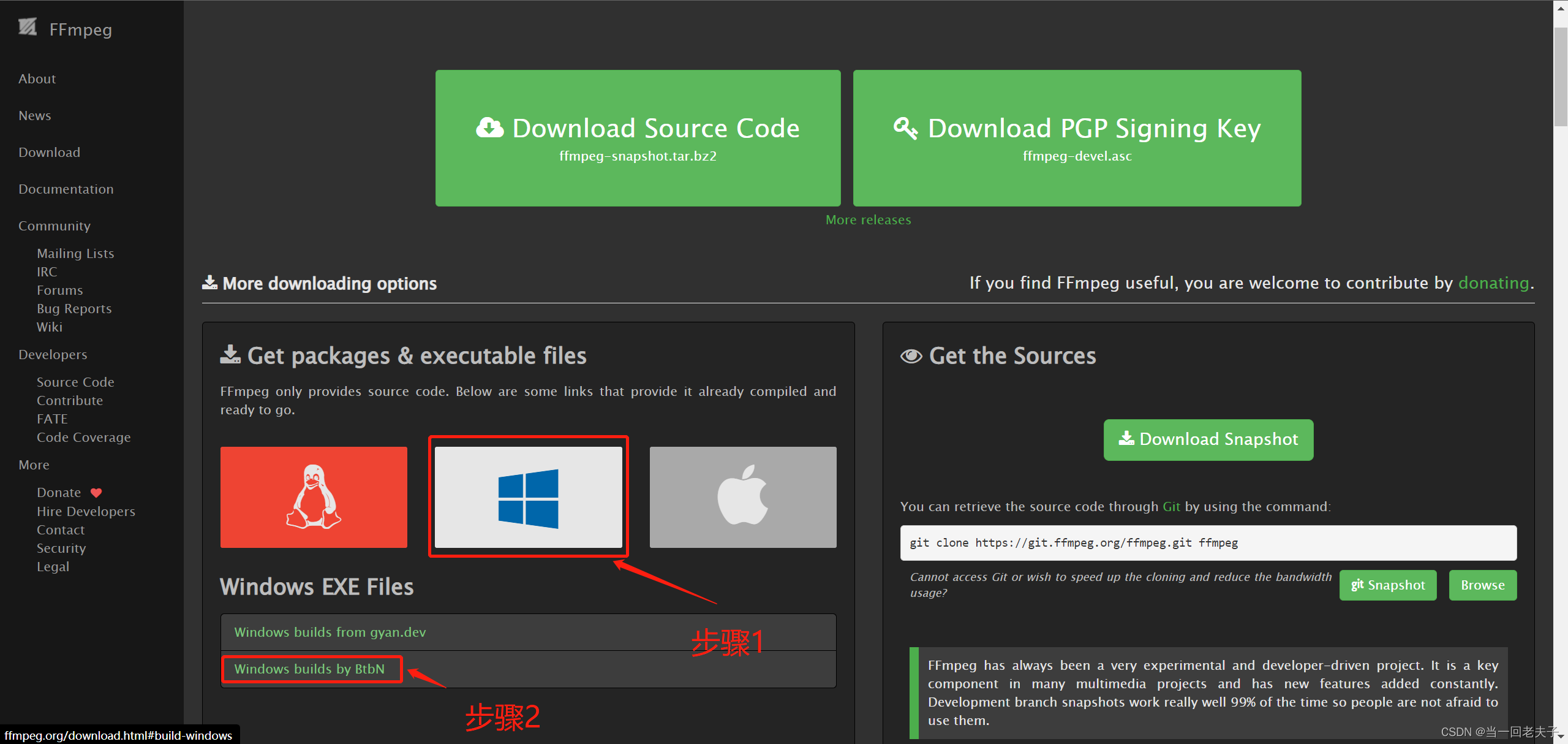
- 下载完,解压一下,把bin路径复制一下,添加到系统环境变量中(系统环境在控制面板中,找不到的网上搜索一下),下面是添加环境变量的教程

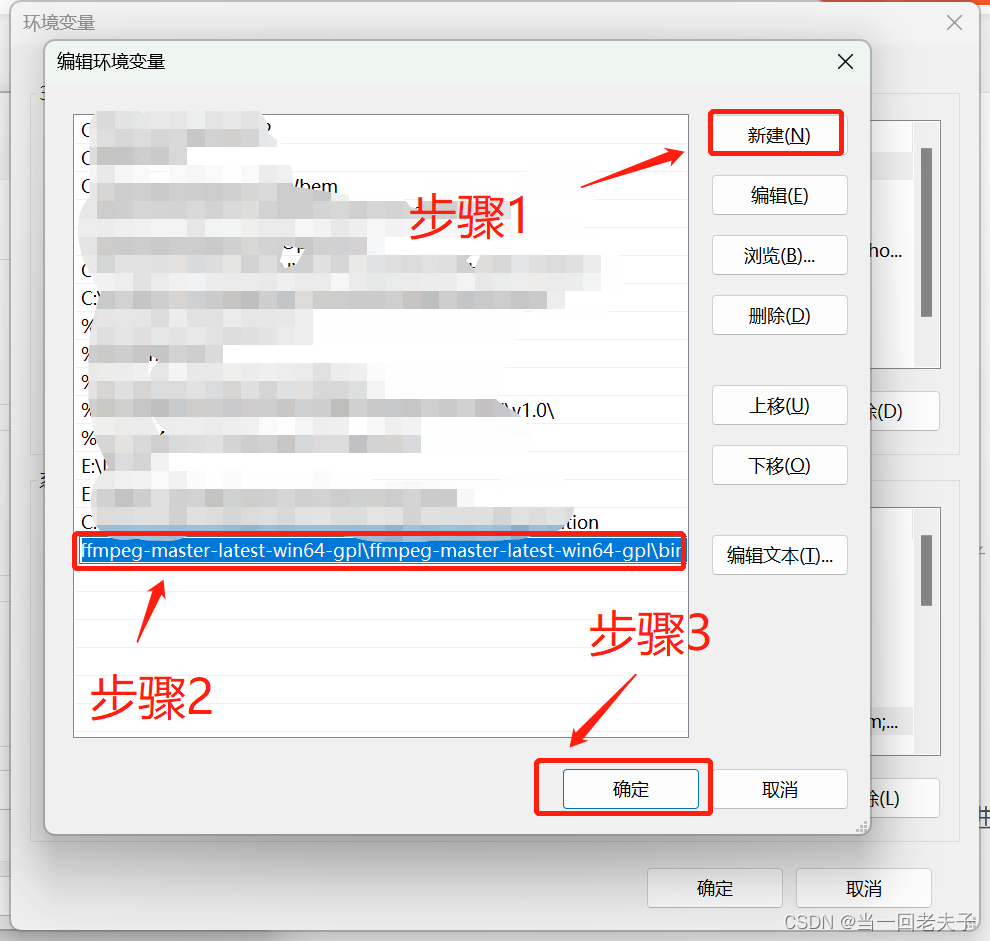
- 添加完环境变量后,再pip install FFmpeg
上面步骤搞定了,再打开cmd 命令,输入ffmpeg, 如果出现下面这个界面,表示安装成功,可以进行下面一个步骤,如果没有成功,请检查前面的步骤是否正确。

第四:下载预测模型
- 点击Release Spleeter public release · deezer/spleeter · GitHub下载预测模型,git上是国外网站,下载速度比较慢,请耐心等待,下面图片展示的是我下载的模型,大家按照自己的需求下载
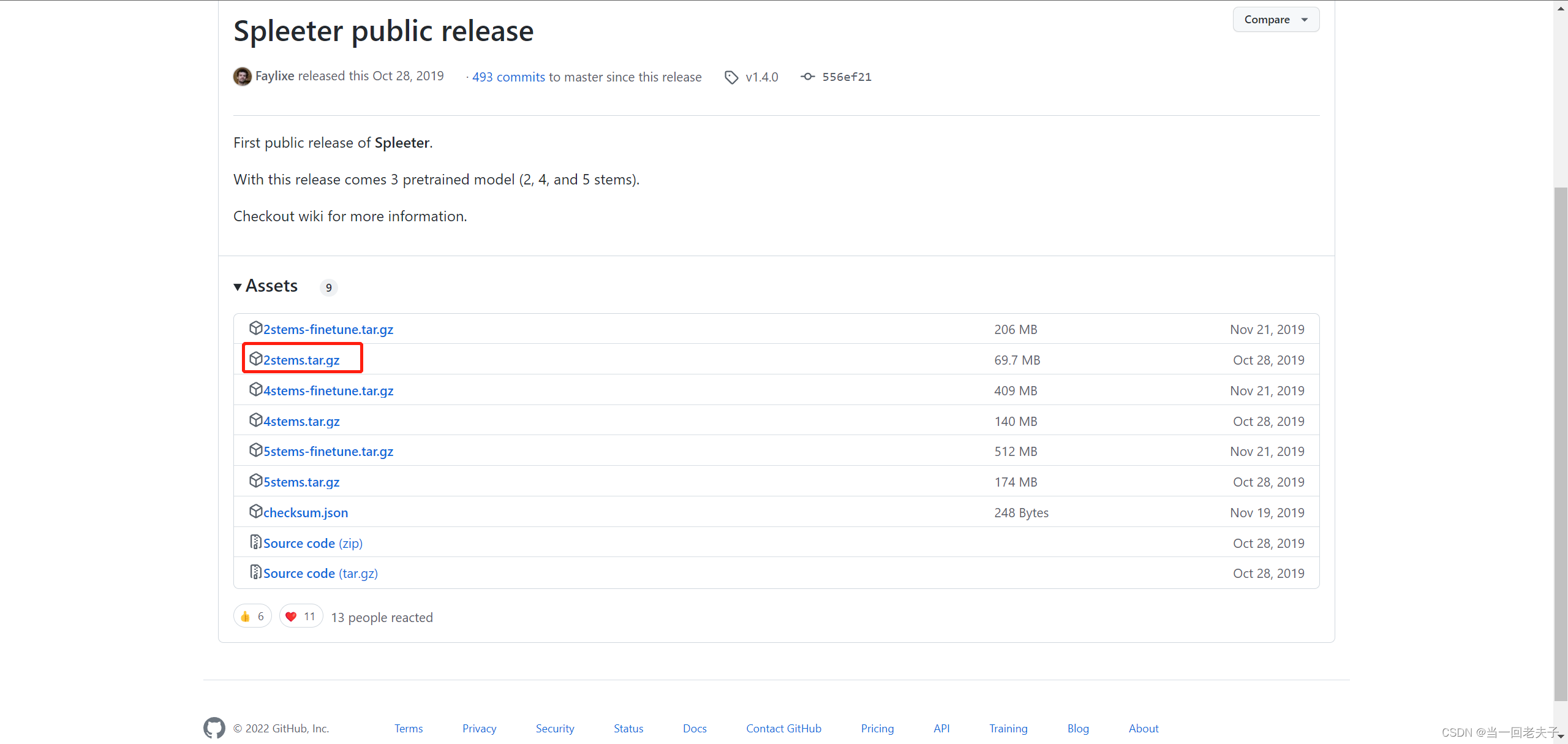
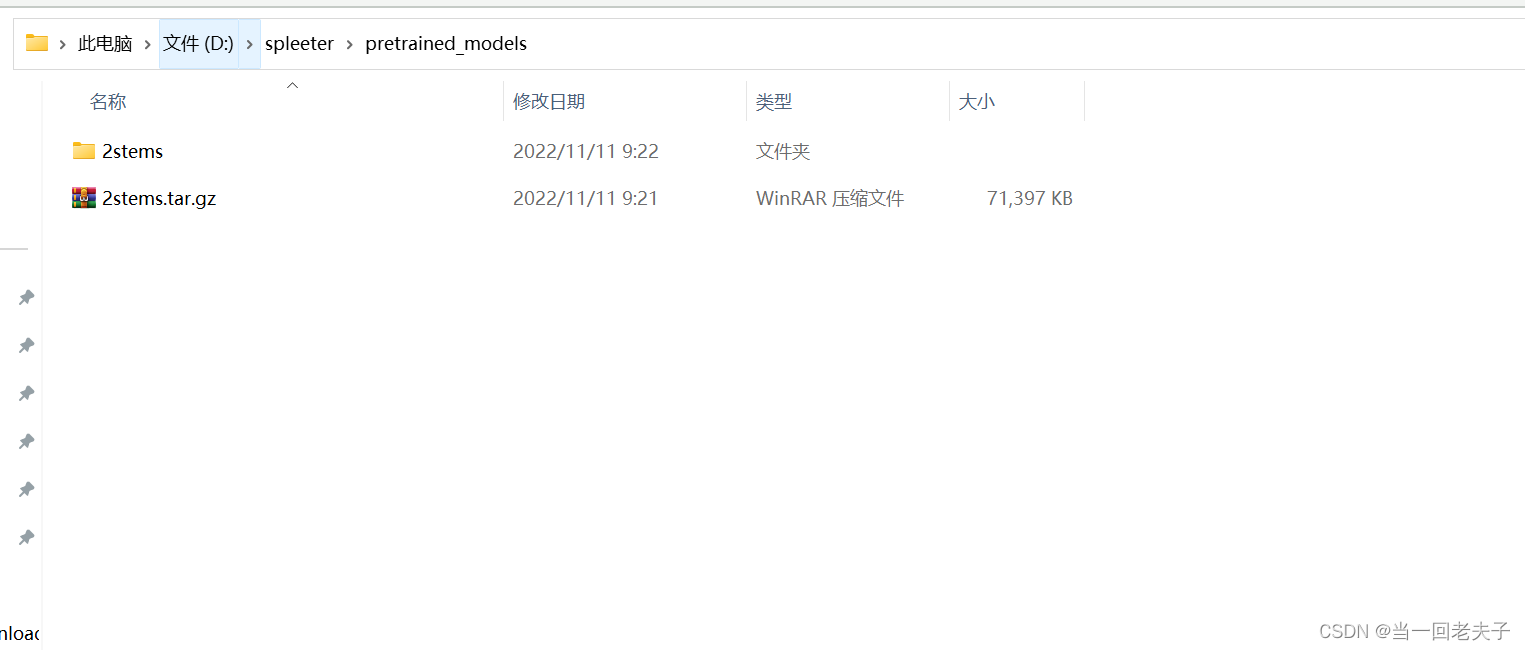
- 下载完,在电脑上创建一个名叫spleeter的文件夹,把在spleeter文件夹中再创建一个pretrained_models文件夹,然后把你下载好的预测模型解压到这个pretrained_models文件夹中,预测模型所在的文件夹结构是这样的
- 在其他地方创建一个用于存放分离后音频的文件夹,我这边创建的文件夹名叫aa,大家依据自己的命名喜好创建,为避免报错,最好还是用英文名来命名
- 接下来把需要分离的音频放在spleeter文件夹下
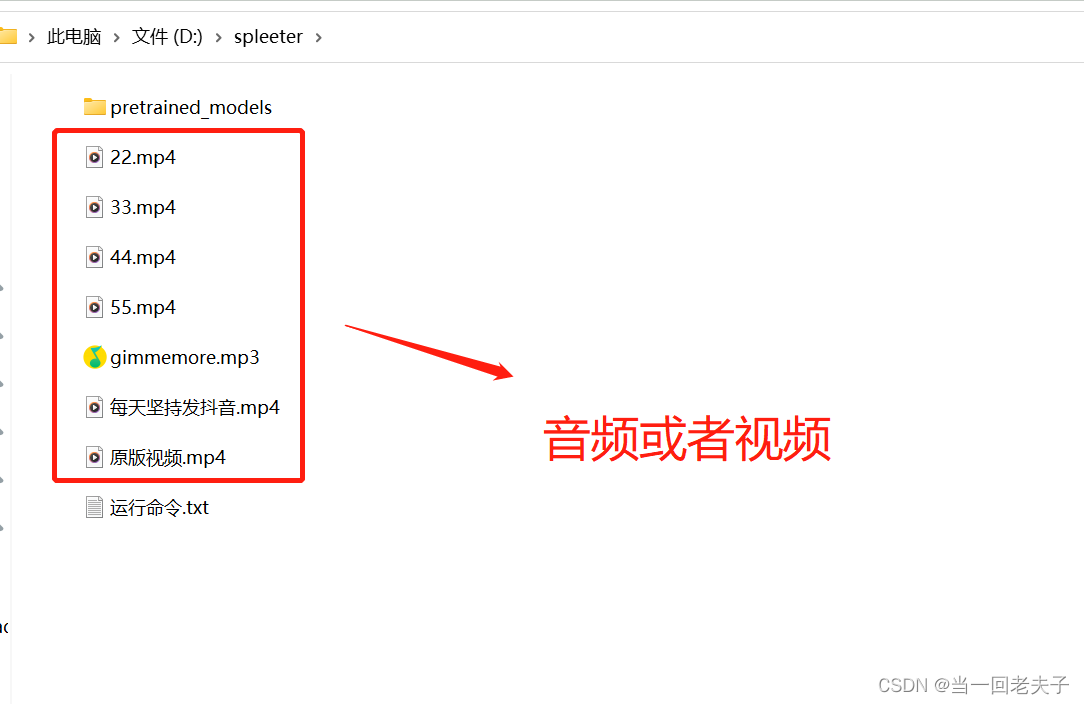
- 然后在spleeter路径上输入cmd,在cmd中执行一下命令 :
Python -m spleeter separate D:\spleeter\gimmemore.mp4 -p spleeter:2stems -o D:\aa D:\spleeter\gimmemore.mp4:是想要分离视频的视频路径
D:\aa:是存放分离后音频文件夹的路径
我这边是拿视频做的测试,大家按照自己的路径把这两个地方的路径做一下修改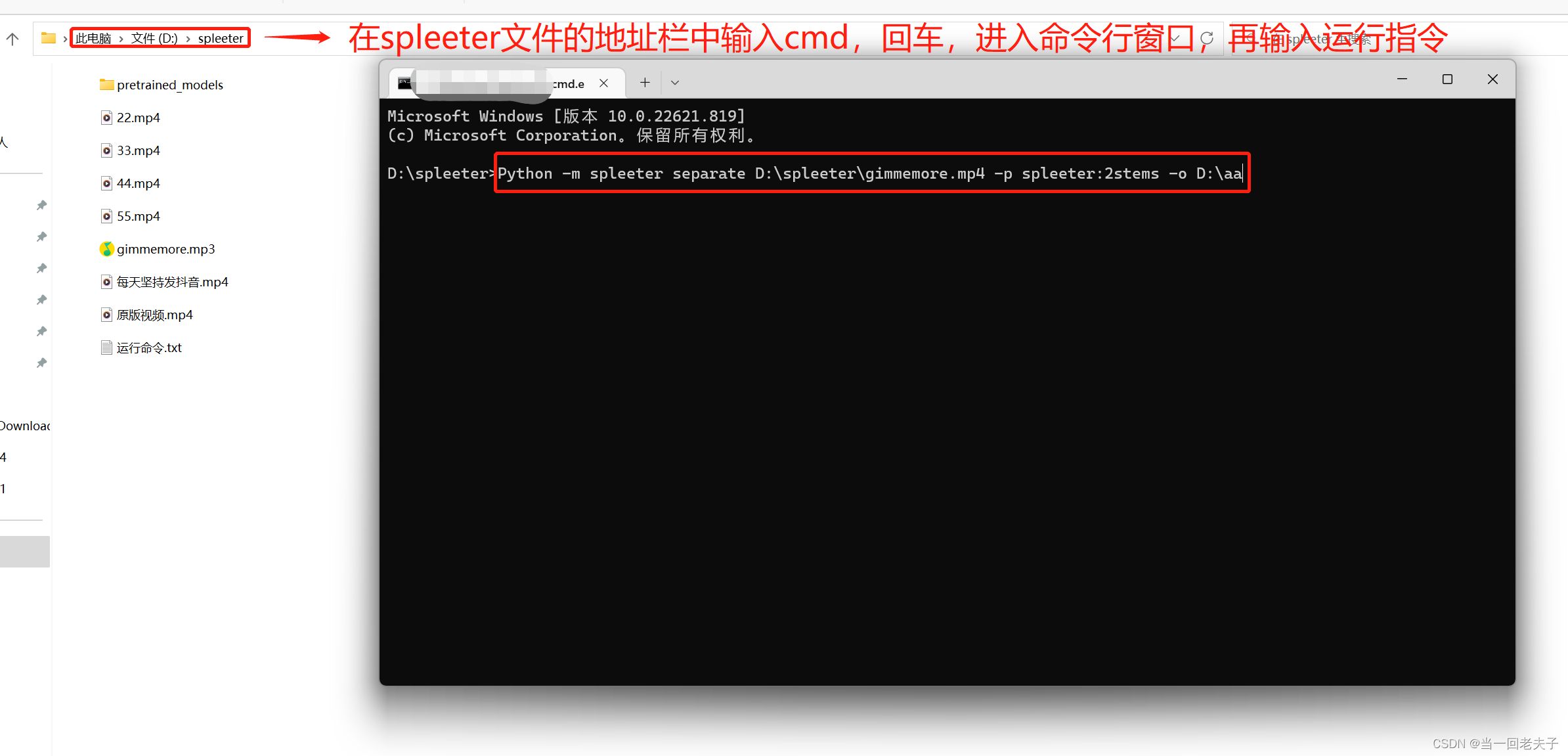
- 执行完命令后,如果没有报错,就会在aa的文件夹中生成两个音频文件,一个人声一个音乐
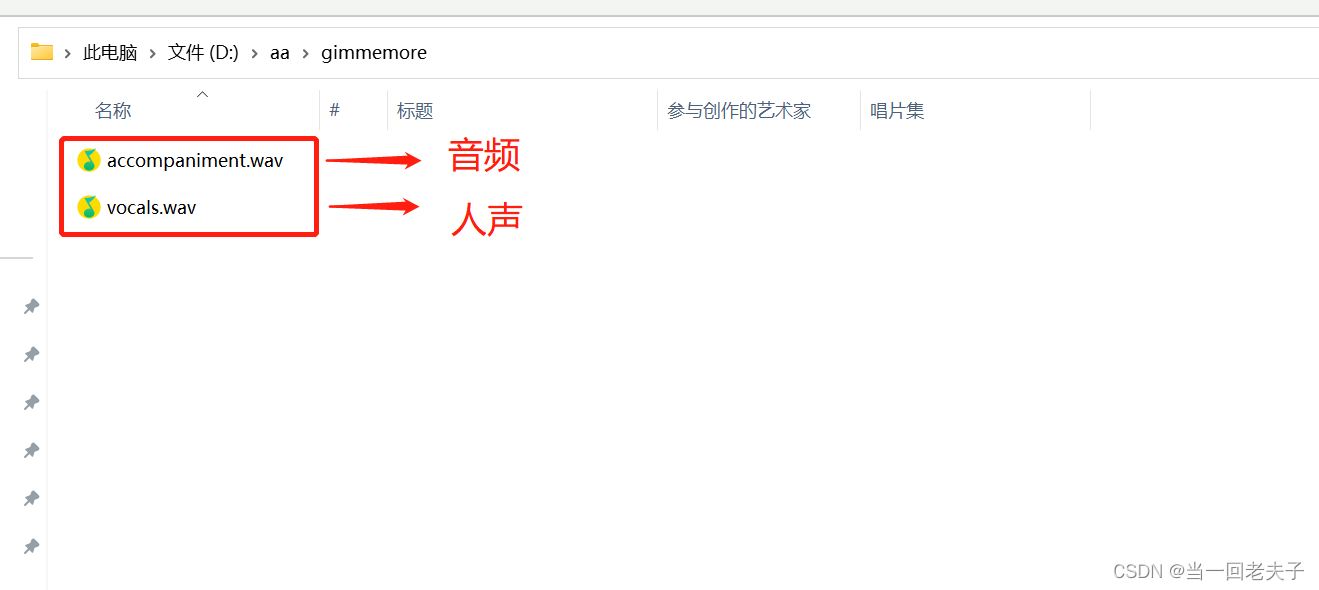
祝大家都能顺利部署成功,大家在安装过程中有什么问题也可以联系我
这篇关于Win11基于python,利用Spleeter实现人声音频分离(详细教程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







