本文主要是介绍Python-科学计算-pandas-19-df分组上中下旬,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系统:Windows 10
语言版本:conda 4.4.10
编辑器:JetBrains PyCharm Community Edition 2018.2.2 x64
pandas:0.22.0
- 这个系列讲讲Python的科学计算及可视化
- 今天讲讲pandas模块
- 按照时间列,得出每行属于上中下旬,进而对df进行分组
Part 1:场景描述
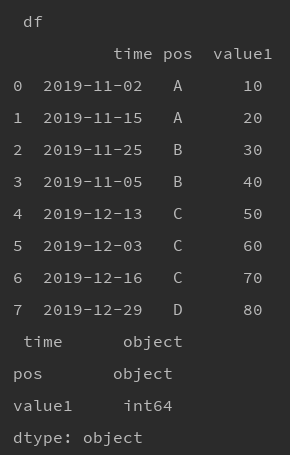
- 已知df,包括3列,
["time", "pos", "value1"] - 根据time列的结果对df进行分组,分为上旬、中旬、下旬三组
- 分组规则,设置如下(这里只是假设一种分法,官方分法请查阅相关资料):
- 每月10号之前(包括10号)为上旬,对应数学表达式为:x ≤10
- 每月10-20号为中旬,对应数学表达式为:10<x ≤20
- 每月20号之后为下旬,不包括20号,对应数学表达式为:x >20
df
Part 2:代码逻辑
- 新生成time1列,该列是time列对应的日期格式数据
- 生成一个新列flag,为time1列对应的具体几号(取值范围1-31)
- 对flag进行判断,将结果写入xun列
- 根据xun列进行过滤,获取对应数据
Part 3:代码
import pandas as pd
import numpy as np# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 设置显示长度为100
pd.set_option('max_colwidth', 100)
# 设置对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 设置打印宽度
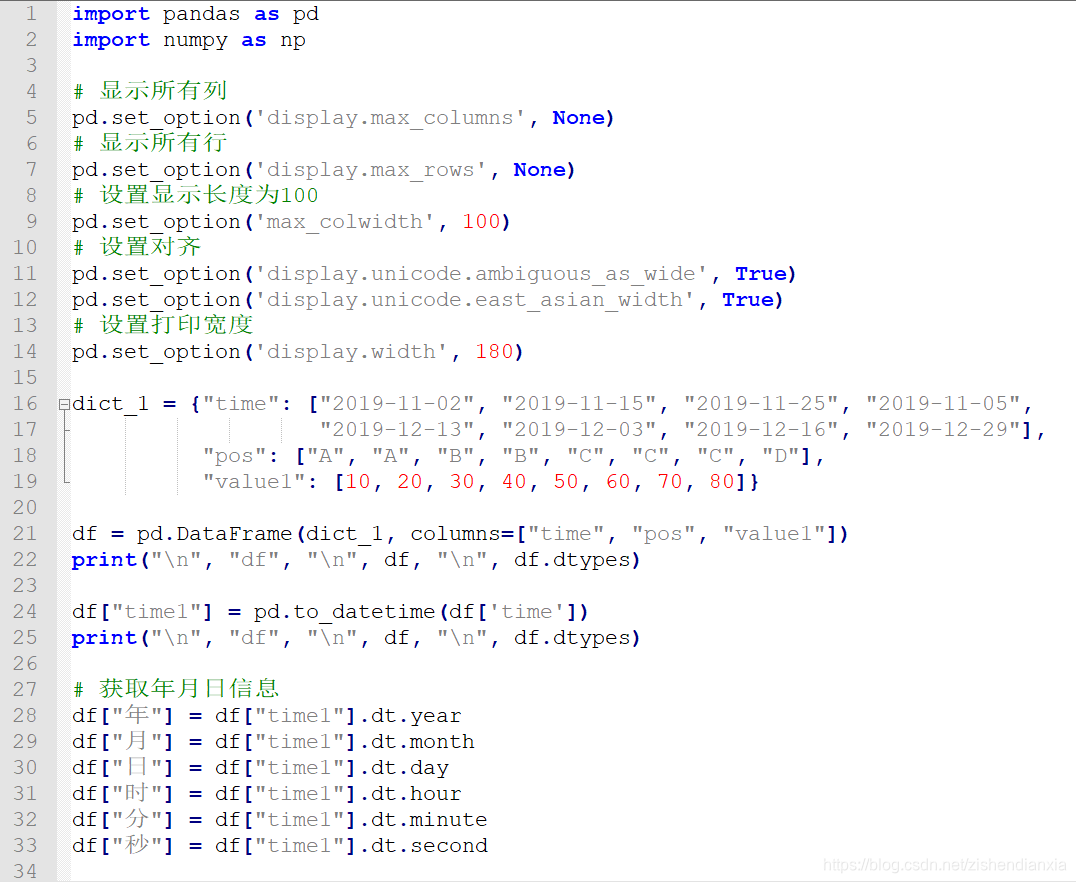
pd.set_option('display.width', 180)dict_1 = {"time": ["2019-11-02", "2019-11-15", "2019-11-25", "2019-11-05","2019-12-13", "2019-12-03", "2019-12-16", "2019-12-29"],"pos": ["A", "A", "B", "B", "C", "C", "C", "D"],"value1": [10, 20, 30, 40, 50, 60, 70, 80]}df = pd.DataFrame(dict_1, columns=["time", "pos", "value1"])
print("\n", "df", "\n", df, "\n", df.dtypes)df["time1"] = pd.to_datetime(df['time'])
print("\n", "df", "\n", df, "\n", df.dtypes)# 获取年月日信息
df["年"] = df["time1"].dt.year
df["月"] = df["time1"].dt.month
df["日"] = df["time1"].dt.day
df["时"] = df["time1"].dt.hour
df["分"] = df["time1"].dt.minute
df["秒"] = df["time1"].dt.seconddf["flag"] = df["日"]df["xun"] = np.where((df["flag"] > 10) & (df["flag"] <= 20), "中旬", np.where(df["flag"] <= 10, "上旬", "下旬"))
print("\n")
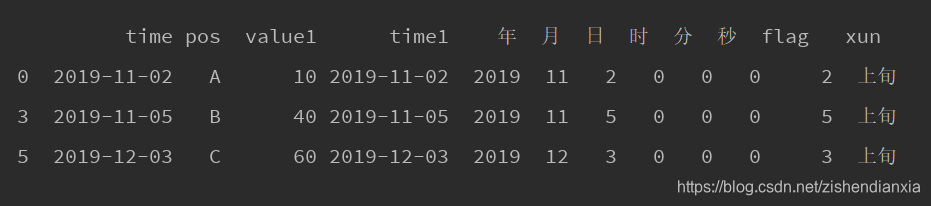
print(df)df_1 = df[df["xun"] == "上旬"]
print("\n")
print(df_1)df_1 = df[df["xun"] == "中旬"]
print("\n")
print(df_1)df_1 = df[df["xun"] == "下旬"]
print("\n")
print(df_1)代码截图

Part 4:部分代码解读
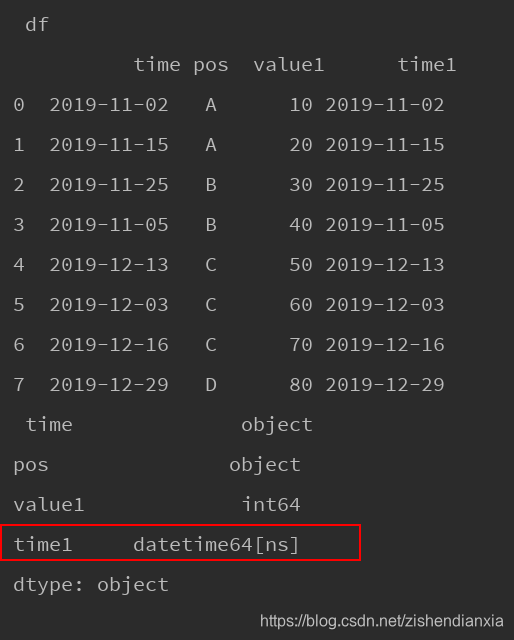
df["time1"] = pd.to_datetime(df['time'])时间格式转换,新生成的数据类型为datetime64
时间格式转换
2. df["日"] = df["time1"].dt.day获取日期对应的具体几号
3.df["xun"] = np.where((df["flag"] > 10) & (df["flag"] <= 20), "中旬", np.where(df["flag"] <= 10, "上旬", "下旬")),两重判断
- np.where(条件,满足条件结果,不满足条件结果)
- 支持嵌套,有点VBA公式的感觉
- 对flag列的每个元素进行计算,结果为xun
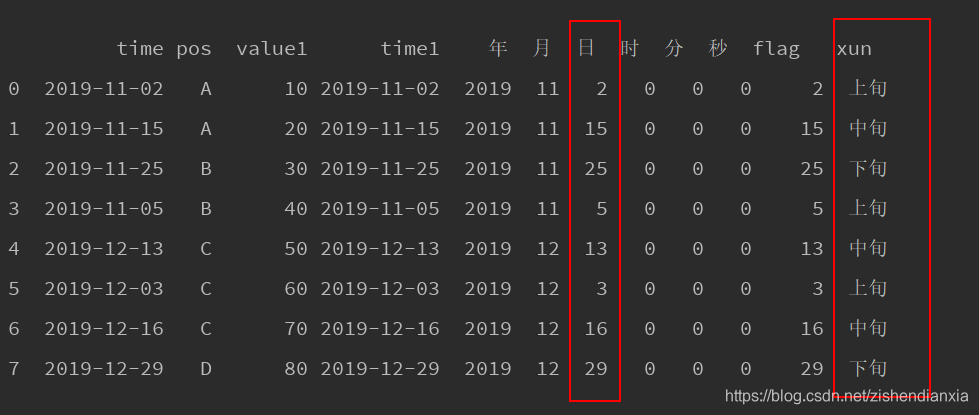
4. df_1 = df[df["xun"] == "上旬"]获取上旬数据
本文为原创作品,欢迎分享朋友圈
长按图片识别二维码,关注本公众号
Python 优雅 帅气
这篇关于Python-科学计算-pandas-19-df分组上中下旬的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







