本文主要是介绍基于pytorch的CREStereo立体匹配算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、CREStereo是什么?
- 1.自适应群相关层
- 局部特征注意力
- 2D-1D转换局部搜索
- 可变形的搜索窗口
- Group-wise相关性
- 2.级联的网络
- 3.叠加级联推理
- 4.叠加级联推理损失函数
- 二、基于pytorch的CREStereo立体匹配算法
前言
CREStereo目前在middlebury上的排名第三(前两名是cvpr2023的文章),非常值得学习和借鉴。

CREStereo还提出了新的数据集,作者利用Blender生成我们的合成训练数据。每个场景由左右图像对和对应像素精确的密集视差图组成,由双虚拟相机和习惯位置的物体捕获。
新的数据集大约400个g,奈何电脑不行,就没下载了,作者开源代码megvii-research/CREStereo提供了两种方式:
(1)Download using shell scripts dataset_download.sh
sh dataset_download.sh
(2)百度网盘crestereo_dataset
密码为:aa3g
一、CREStereo是什么?
CREStereo(Cascaded Recurrent Network Stereo),即级联立体匹配网络。
CREStereo旨在通过使用上下文推理来更好地理解场景中不同物体和表面之间的关系,从而提高立体匹配的准确性和效率。这使得网络能够更加确切地决定每个像素的深度,从而产生更准确的深度图和3D重建。
1.自适应群相关层
作者观察到,很难为现实世界的立体相机实现完美的校准。例如,两个相机可能不会严格放置在水平外极线上,导致在三维空间中轻微旋转;或者相机镜头的图像即使经过修正后也会有残余失真。因此,对于立体图像对,对应的点可能不位于同一扫描线上。因此,作者提出了一种自适应群相关层(AGCL)来减少这种情况下的匹配模糊性,在只计算局部相关的情况下,比全对匹配获得更好的性能。
局部特征注意力
作者不计算每对像素的全局相关性,而是只匹配一个局部窗口中的点,以避免大量的内存消耗和计算成本。针对稀疏特征匹配的LoFTR特征匹配,在级联第一阶段的相关计算之前添加了一个注意模块,以便将全局上下文信息聚合到单个或交叉特征图中。在之后,在主干输出中添加了位置编码,这增强了特征映射的位置依赖性。交替计算自注意和交叉注意,其中使用线性注意层来降低计算复杂度。
2D-1D转换局部搜索
不同于流量估计网络RAFT及其立体版本,其中全对相关性由两个C×H×W特征图的矩阵乘法计算,输出4DH×W×W×W或3DH×W×W成本量,只在一个局部搜索窗口中计算相关性,该窗口输出更小体积的H×W×D,以节省内存和计算成本。H和W表示特征图的高度和宽度,D是相关对的数量远小于W。作者的相关计算也不同于基于成本体积立体网络搜索范围与前景对象的最大位移。这个固定的范围比作者使用的局部相关对的数量要大得多,这导致了更多的噪声干扰。此外,当模型推广到具有不同基线的立体声对时,不需要预设范围。
给定两个重新采样和参与的特征图F1和F2,在位置(x,y)上的局部相关性可记为:

传统上,在立体匹配中,两个校正图像之间的搜索方向只位于外极线上。为了处理非理想的立体整流情况,我们采用了2D-1D替代局部搜索策略来提高匹配精度。在一维搜索模式下,我们设置g(d)=0和f(d)∈[−r,r],其中r=4。保留f(d)的正位移值,以便在每次迭代采样后调整不准确的结果。由等式计算的结果1被堆叠并连接在通道维度上,以获得最终的相关V。在二维搜索模式中,使用与扩张卷积相似的k×k网格进行相关计算。设置了k=√2r+1来确保特征具有相同数量的通道,因此它们可以被输入到一个共享权重的更新块中。与迭代重采样合作,交替局部搜索也作为循环细化的传播模块,其中网络学习用其更准确的邻居替换对当前位置的有偏预测。
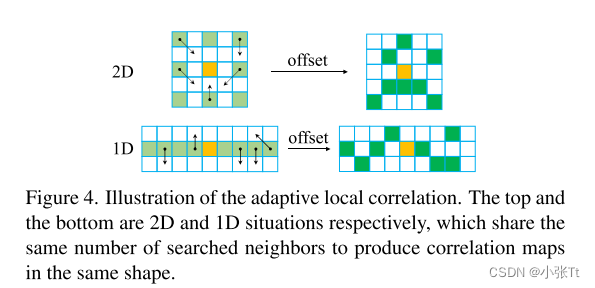
可变形的搜索窗口
立体匹配经常存在遮挡或无文本区域。在一个固定形状的局部搜索窗口中计算的相关性往往容易受到这些情况的影响。将可变形卷积扩展到相关计算中,使用内容自适应搜索窗口来生成相关对,这与AANet不同,后者仅在成本聚合中采用类似的策略。利用学习到的附加偏移量dx和dy,新的相关性可以计算为
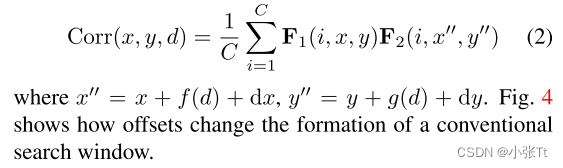
Group-wise相关性
受引入组级4D代价体积的启发,我们将特征图分成G组,分别计算局部相关性。最后,我们将G相关体积串联起来。在通道维度上的D × H × W,得到GD × H × W的输出量。过程如图。
2.级联的网络
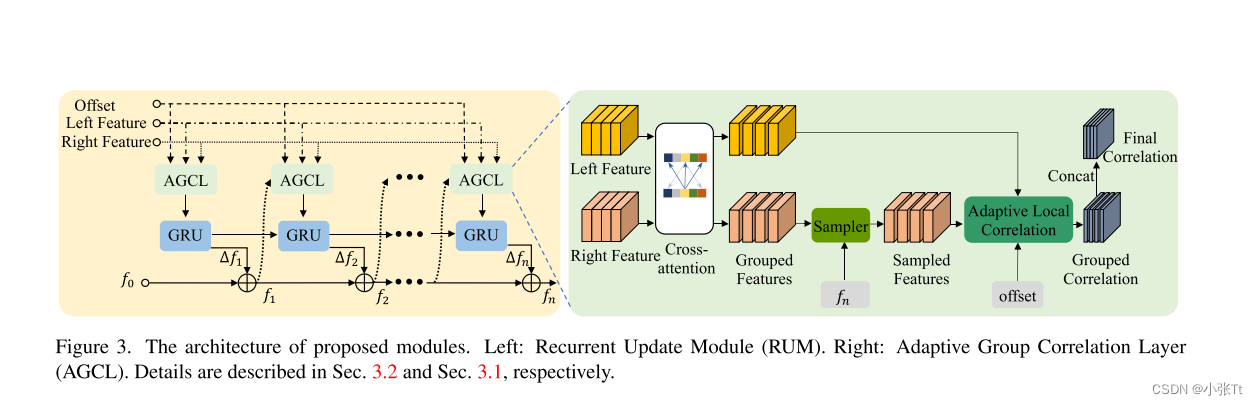
对于非纹理或重复纹理区域,由于接受域大、语义信息充足,使用低分辨率和高级特征映射进行匹配更加鲁棒。 然而,在这种特征图中,精细结构的细节可能会丢失。为了保持鲁棒性,同时保留高分辨率输入中的细节,作者提出了级联迭代精化的相关计算和视差更新。 循环更新模块:我们基于GRU块和自适应组相关层(AGCL)构建了循环更新模块(RUM)。与PAFT不同的是,特征金字塔构建在单个相关层中,输出合并为一个卷,我们分别计算每个特征映射在不同级联级别的相关性,并单独细化几个迭代的视差。“sampler”以fn导出的坐标网格为输入,对分组特征的位置进行采样。{f1,…, fn}为初始化f0的n次迭代的中间预测。电流相关体积由学习到的偏移量o∈R2×(2r+1)×h×w构造。GRU块更新当前预测并在下一次迭代时反馈给AGCL。 级联改进:除了级联的第一级(从输入分辨率的1/16开始,视差初始化为所有0),其他级别将从前一级的预测的上采样版本作为初始化。虽然处理不同层次的细化,所有RUMs的重量相同。在最后一级细化后,进行凸上采样,得到输入分辨率下的最终预测结果。
3.叠加级联推理
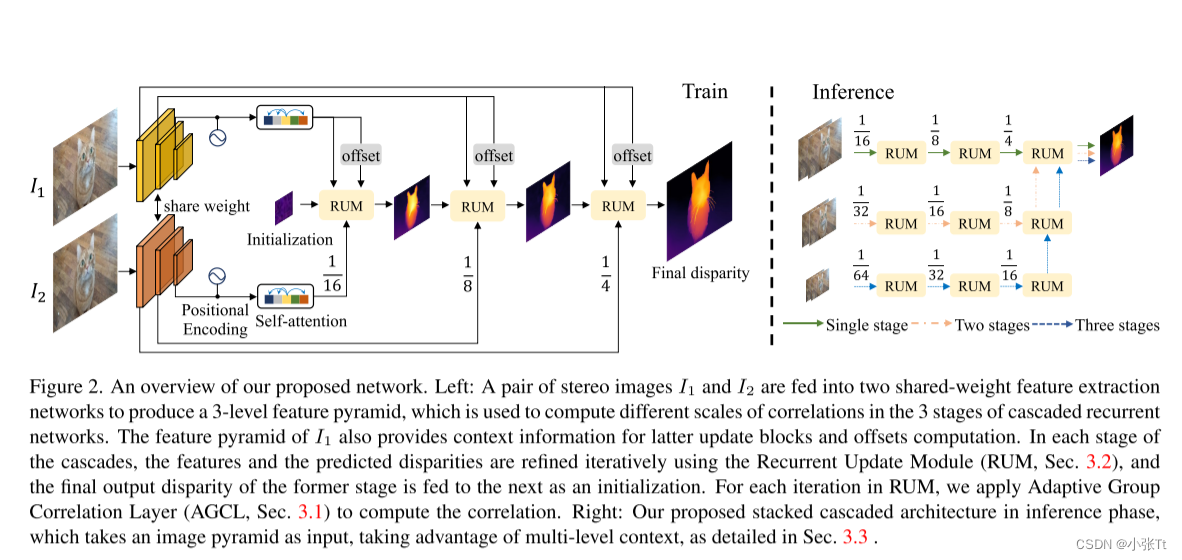
正如前几节所讨论的,在训练过程中,作者使用固定分辨率的三层特征金字塔进行层次细化。然而,对于分辨率较高的图像作为输入,需要进行更多的降采样,以扩大接收域,进行特征提取和相关计算。但对于高分辨率图像中位移较大的小目标,直接下采样可能会使这些区域的特征退化。为了解决这一问题,作者设计了一种具有推理快捷方式的堆叠级联架构。特别的,作者预先对图像对进行下采样,构建一个图像金字塔,并将它们输入到同一个训练好的特征提取网络中,以利用多层次的上下文。图下图右侧显示了堆叠级联架构的概览,为了简洁起见,没有显示同一阶段的跳跃连接。对于堆叠级联的某一特定阶段,该阶段的所有RUM将与更高分辨率阶段的最后一个RUM一起使用。叠层梯级的所有阶段在训练中都有相同的重量,所以没有精细的调整。
4.叠加级联推理损失函数
对于每个阶段s∈{116, 18, 41}的特征金字塔,作者用上采样算子µs将输出{fis,···,f sn}的序列调整到完全预测分辨率,并使用类似RAFT的指数加权l1距离为损失函数(γ设为0.9)。给定ground truth视差dgt,总损失定义为:
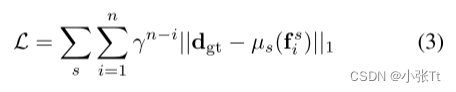
其他合成数据集和实验细节等都不介绍啦,可以直接看原文章,链接放到这里啦:CREStereo
二、基于pytorch的CREStereo立体匹配算法
原作者开源的代码使用的是MegEngine(开源深度学习框架旷视天元(MegEngine)是旷视自主研发的国产工业级深度学习框架),国产哦,有机会还是要支持一下哦!
源码链接放到这里啦:https://github.com/megvii-research/CREStereo
这里我们使用另一位大佬提供的开源代码,是基于pytorch的,源码链接:https://github.com/ibaiGorordo/CREStereo-Pytorch
作者提供了从原始模型转换出来的Pretrained modelPretrained model,因为训练集太大了,只能使用提供的训练模型啦,感兴趣的可以自己训练一下。
把下载好的权重放到models文件夹下:

在test_model中修改左右图像路径就可以啦!

运行效果如下:

参考文献:CREStereo: Practical Stereo Matching via Cascaded Recurrent Networkwith Adaptive Correlation-论文阅读
这篇关于基于pytorch的CREStereo立体匹配算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







