本文主要是介绍用Python分析苹果公司股价数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
要点抢先看
1.csv数据的读取
2.利用常用函数获取均值、中位数、方差、标准差等统计量
3.利用常用函数分析价格的加权均值、收益率、年化波动率等常用指标 4.处理数据中的日期
我们最后会介绍一下NumPy库中的一些非常实用和常用的函数方法。
要知道,NumPy的常用数学和统计分析的函数非常多,如果我们一个一个的分散来讲,一来非常枯燥,二来呢也记不住,就仿佛又回到了昏昏欲睡的课堂,今天我们用一个背景例子来串联一下这些零散的知识点。
我们通过分析苹果公司的股票价格,来串讲NumPy的常用函数用法
我们在我们python文件的同级目录下放置数据文件AAPL.csv,用excel文件可以打开看看里面是什么样的:
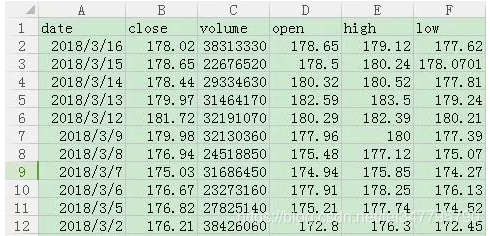
依次是日期,收盘价、成交量、开盘价、最高价和最低价 在CSV文件中,每一列数据数据是被“,”隔开的,为了突出重点简化程序,我们把第一行去掉,就像下面这样
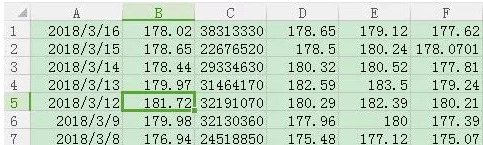
首先,我们读取“收盘价”和“成交量”这两列,即第1列和第2列(csv也是从第0列开始的)
import numpy as np
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
c, v = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1, 2), unpack=True)
print(c)
print(v)
[ 178.02 178.65 178.44 179.97 181.72 179.98 176.94 175.03 176.67 176.82 176.21 175. 178.12 178.39 178.97 175.5 172.5 171.07 171.85 172.43 172.99 167.37 164.34 162.71 156.41 155.15 159.54 163.03 156.49 160.5 167.78 167.43 166.97 167.96 171.51 171.11 174.22 177.04 177. 178.46 179.26 179.1 176.19 177.09 175.28 174.29 174.33 174.35 175. 173.03 172.23 172.26 169.23 171.08 170.6 170.57 175.01 175.01 174.35 174.54 176.42]
[ 38313330. 22676520. 29334630. 31464170. 32191070. 32130360. 24518850. 31686450
这样,我们就完成了第一个任务,将csv数据文件中存储的数据,读取到我们两个ndarray数组c和v中了。
接下来,我们小试牛刀,对收盘价进行最简单的数据处理,求取他的平均值。
第一种,非常简单,就是我们最常见到的算数平均值
import numpy as np
c, v = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1, 2), unpack=True)
mean_c = np.mean(c) print(mean_c)
172.614918033
第二种,是加权平均值,我们用成交量来加权平均价格
即,用成交量的值来作为权重,某个价格的成交量越高,该价格所占的权重就越大。
import numpy as np
c, v = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1, 2), unpack=True)
vwap = np.average(c, weights=v)
print(vwap)
170.950010035
再来说说取值范围,找找最大值和最小值
我们找找收盘价的最大值和最小值,以及最大值和最小值之间的差异
import numpy as np c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True) print(np.max(c)) print(np.min(c)) print(np.ptp(c)) 181.72 155.15 26.57接下来我们进行简单的统计分析
我们先来求取收盘价的中位数
import numpy as np c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True) print(np.max(c)) print(np.min(c)) print(np.median(c)) 181.72 155.15 174.35求取方差
另外一个我们关心的统计量就是方差,方差能够体现变量变化的程度。在我们的例子中,方差还可以告诉我们投资风险的大小。那些股价变动过于剧烈的股票一定会给持有者带来麻烦
import numpy as np c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True) print(np.var(c)) 37.5985528621
我们回顾一下方差的定义,方差指的是各个数据与所有数据算数平均数的离差平方和的均值
import numpy as np c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True) print(np.mean((c - c.mean())**2))
37.5985528621
上下对比一下,看看,结果是一模一样的。
现在我们来看看每天的收益率,这个计算式子很简单:
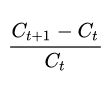
即用今天的收盘价减去昨天的收盘价,再除以昨天的收盘价格。同时我们发挥NumPy的优势,利用向量运算,可以一次性算出所有交易日的收益率
diff函数时用数组的第N项减第N-1项,得到一个n-1项的一维数组。本例中我们注意到数组中日期越近的收盘价,数组索引越小,因此得取一个相反数,综上代码:
import numpy as np c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True) returns = -np.diff(c)/c[1:] print(returns) [-0.00352645 0.00117687 -0.00850142 -0.0096302 0.00966774 0.01718097 0.0109124
然后观察一下每日收益的标准差,就可以看看收益的波动大不大了:
import numpy as np c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True) returns = -np.diff(c)/c[1:] print(np.std(returns)) 0.0150780328454如果我们想看看哪些天的收益率是正的,很简单,还记得where语句吗,拿来使用吧
import numpy as np c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True) returns = -np.diff(c)/c[1:] print(np.where(returns>0)) (array([ 1, 4, 5, 6, 9, 10, 14, 15, 16, 20, 21, 22, 23, 24, 27, 30, 31, 34, 37, 40, 专业上我们对价格变动可以用一个叫做“波动率”的指标进行度量。计算历史波动率时需要用到对数收益率,对数收益率很简单,就是
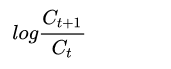
依照对数的性质,他等于
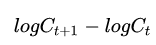
在计算年化波动率时,要用样本中所有的对数收益率的标准差除以其均值,再除以交易日倒数的平方根,一年交易日取252天。
我们简单的看一下下面的代码
import numpy as np c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True) logreturns = -np.diff(np.log(c)) volatility = np.std(logreturns) / np.mean(logreturns) annual_volatility = volatility / np.sqrt(1./252.) print(volatility) print(annual_volatility) 100.096757388 1588.98676256这里我们再强调一点就是:sqrt方法中应用了除法计算,这里必须使用浮点数进行运算。月度波动率也是同理用1./12.即可
我们可以常常会发现,在数据分析的过程中,对于日期的处理和分析也是一个很重要的内容。
我们先试图用老办法来从csv文件中把日期数据读出来
import numpy as np dates,c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(0,1), unpack=True)Traceback (most recent call last):File "E:/12homework/12homework.py", line 2, in <module>dates,c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(0,1), unpack=True) File "C:\Python34\lib\site-packages\numpy\lib\npyio.py", line 930, in loadtxtitems = [conv(val) for (conv, val) in zip(converters, vals)]File "C:\Python34\lib\site-packages\numpy\lib\npyio.py", line 930, in <listcomp>items = [conv(val) for (conv, val) in zip(converters, vals)]File "C:\Python34\lib\site-packages\numpy\lib\npyio.py", line 659, in floatconvreturn float(x)ValueError: could not convert string to float: b'2018/3/16'我们发现他报错了,错误信息是不能将一个字节类型的对象转换为浮点类型对象。原因是因为NumPy是面向浮点数运算的,那么我们对症下药,对日期字符串进行一些转换处理。
我们先假定日期是一个字符串类型(下载的网络数据中往往是将字符串通过utf-8编码成字节码,这个可以见第一季中字符编码相关内容的介绍)
import numpy as np import datetime strdate = '2017/3/16' d = datetime.datetime.strptime(strdate,'%Y/%m/%d') print(type(d)) print(d) <class 'datetime.datetime'> 2017-03-16 00:00:00
通过python标准库中的datetime函数包,我们通过指定匹配的格式%Y/%m/%d
将日期字符串转换为了datetime类型对象,Y大写匹配完整的四位数记年,y小写就是两位数,例如17。
datetime对象有一个date方法,把datetime对象中的time部分去掉,变成一个纯的日期,再调用weekday可以转换为一周中的第几天,这里是从周日开始算起的。
import numpy as np import datetime strdate = '2018/3/16' d = datetime.datetime.strptime(strdate,'%Y/%m/%d') print(d.date()) print(d.date().weekday()) 2018-03-16 4最后,我们回到这份苹果公司股价的csv文件,来做一个综合分析,来看看周几的平均收盘价最高,周几的最低:
import numpy as np import datetime def datestr2num(bytedate): return datetime.datetime.strptime(bytedate.decode('utf-8'),'%Y/%m/%d').date().weekday() dates,c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(0,1), converters={0: datestr2num}, unpack=True) averages = np.zeros(5) for i in range(5): index = np.where(dates == i) prices = np.take(c, index) avg = np.mean(prices) averages[i] = avg print("Day {} prices: {},avg={}".format(i,prices,avg)) top = np.max(averages) top_index = np.argmax(averages) bot = np.min(averages) bot_index = np.argmin(averages) print('highest:{}, top day is {}'.format(top,top_index)) print('lowest:{},bottom day is {}'.format(bot,bot_index)) Day 0 prices: [[ 181.72 176.82 178.97 162.71 156.49 167.96 177. 174.35 176.42]],avg=172.49333333333334 Day 1 prices: [[ 179.97 176.67 178.39 171.85 164.34 163.03 166.97 177.04 176.19 174.33 172.26 170.57 174.54]],avg=172.78076923076924 Day 2 prices: [[ 178.44 175.03 178.12 171.07 167.37 159.54 167.43 174.22 179.1 174.29 172.23 170.6 174.35]],avg=172.44538461538463 Day 3 prices: [[ 178.65 176.94 175. 172.5 172.99 155.15 167.78 171.11 179.26 175.28 173.03 171.08 175.01]],avg=172.59846153846152 Day 4 prices: [[ 178.02 179.98 176.21 175.5 172.43 156.41 160.5 171.51 178.46 177.09 175. 169.23 175.01]],avg=172.71923076923073 highest:172.78076923076924, top day is 1 lowest:172.44538461538463,bottom day is 2简要的再分析一下:由于从csv中读取的数据类型为bytes,所以我们写了一个转换函数,先将bytes类型的日期数据进行解码(字符串编解码详见第一季),然后再用上一段程序介绍的方法转换为一个表示周几的数字
而np.loadtxt函数中的参数converters={0: datestr2num},就是说针对第一列的数据,我们利用这个转换函数将其转化为一个数字,并将这个整形元素构成的数组赋值给dates变量。
后面的处理就很简单了,用循环依次取出每个工作日的收盘价构成的数组,对其求平均值。然后得到周一到周五,五个平均值的最大值、最小值。
最后我们再介绍两个实用函数,一个是数组的裁剪函数,即把比给定值还小的值设置为给定值,比给定值大的值设置为给定上限
import numpy as np a = np.arange(5) print(a.clip(1,3)) [1 1 2 3 3]第二个是一个筛选函数,返回一个根据给定条件筛选后得到的结果数组
import numpy as np '''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
a = np.arange(5) print(a.compress(a > 2)) [3 4]这一小节中,我们利用NumPy的一些实用函数,对苹果公司的股价进行了一些非常非常简单的分析,目的是通过这个实例来串讲一下这些实用的数据处理函数。
其实NumPy的功能非常非常多,远不止这些,但是没有必要去一个一个学。并且另一方面,NumPy的方法都过于原始和底层,虽然功能很丰富,但是使用起来也很繁杂。这里我们为大家打一个基础,后面的章节就不会再一一介绍里面的各种函数了。后面我要介绍基于NumPy之上的一些更高层的方法库,功能更强大,使用也更简单。
这篇关于用Python分析苹果公司股价数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



