本文主要是介绍对抗样本(论文解读五):Perceptual-Sensitive GAN for Generating Adversarial Patches,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
准备写一个论文学习专栏,先以对抗样本相关为主,后期可能会涉及到目标检测相关领域。
内容不是纯翻译,包括自己的一些注解和总结,论文的结构、组织及相关描述,以及一些英语句子和相关工作的摘抄(可以用于相关领域论文的写作及扩展)。
平时只是阅读论文,有很多知识意识不到,当你真正去着手写的时候,发现写完之后可能只有自己明白做了个啥。包括从组织、结构、描述上等等很多方面都具有很多问题。另一个是对于专业术语、修饰、语言等相关的使用,也有很多需要注意和借鉴的地方。
本专栏希望在学习总结论文核心方法、思想的同时,期望也可以学习和掌握到更多论文本身上的内容,不论是为自己还有大家,尽可能提供更多可以学习的东西。
当然,对于只是关心论文核心思想、方法的,可以只关注摘要、方法及加粗部分内容,或者留言共同学习。
————————————————
Perceptual-Sensitive GAN for Generating Adversarial Patches
AishanLiu§,XianglongLiu§∗,JiaxinFan§,YuqingMa§,AnlanZhang§, HuiyuanXie † and DachengTao‡ §State Key Laboratory of Software Development Environment, Beihang University, China {liuaishan, xlliu, jxfan, mayuqing, zal1506}@buaa.edu.cn† Department of Computer Science and Technology, University of Cambridge, UK hx255@cam.ac.uk ‡UBTECH Sydney AI Centre, SIT, FEIT, University of Sydney, Australia dacheng.tao@sydney.edu.au
发表于AAAI 2019
源码:https://github.com/liuaishan (需要好好研究学习一下)
感知敏感的GAN生成对抗块
Abstract
现有攻击策略还远远不能生成具有强大攻击能力且视觉自然的对抗块,因为它们往往忽略了被攻击网络对对抗块的感知敏感性,包括与图像上下文的相关性和视觉注意力。
提出了感知敏感的GAN(PS-GAN)同时增强视觉保真度与攻击性能来生成对抗块。
将块生成视为通过对抗过程的块到块的变换,输入任意类型的块输出与攻击图像感知高相关的对抗块。
为了进一步提高攻击能力,提出了一种结合对抗生成的注意机制来预测关键的攻击区域,从而生成更真实、更具攻击性的对抗块。
semi-white box and black-box ; GTSRB and ImageNet。
Introduction
On one side, adversarial examples pose potential security threats by attacking or misleading the practical deep learning applications like auto driving and face recognition system. On the other side, adversarial examples are also valuable and beneficial to the deep learning models, as they are able to provide insights into their strengths, weaknesses, and blind-spots.
In the past years, various typical techniques have been developed to produce adversarial examples. such as gradient-based algorithms, optimization-based methods and network-based techniques. the generative adversarial networks (GANs) technique is capable to approximate the true data distribution.
Compared to the traditional perturbation based adversarial examples, the adversarial patch enjoys the advantages of being input-independent and scene independent,and can be easily placed on any input data with general attack ability.

Prior studies in perception and psychophysics indicate that the perceptual sensitivity plays a quite important role in helping accomplish the robust visual recognition.找到一种能够生成的对抗块可以欺骗被攻击网络的视觉感知度的攻击方法。
对抗块在视觉上应该是自然的,与图像内容具有很强的感知相关性,同时在空间上定位于感知敏感的位置。
To address the problem,our paper proposes a novel attack framework named perceptual-sensitive GAN (PS-GAN) to generate adversarial patches. 利用被攻击网络的视觉感知,增强视觉保真以及攻击性能,使用补丁到补丁的翻译过程,以追求视觉上的自然和上下文相关的对抗性补丁。同时引入视觉注意去捕获空间分布感知,引导攻击位置。
Perceptual-Sensitive GAN
In this section,we will first introduce the problem definition, and then elaborate the framework, .
对抗样本x`生成:m为mask=0/1,δ为对抗块,x为原图像
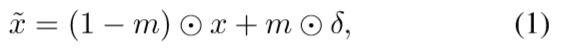
深度卷积神经网络(CNNs)对输入图像中目标的视觉保真度和空间定位具有很强的感知敏感性.

1)引入块到块的翻译过程:输入为特定的块种子及被攻击的图像,输出为与输入块视觉相似及与输入图像相符的对抗块。分别使用GAN网络的生成器与判别器进行相关任务完成。
2)目标模型F负责引导生成块的对抗攻击能力。
3)为了建模空间位置的敏感度,引入注意模型M来捕获被攻击网络的注意力分布,从而决定攻击能力强的补丁的位置。
我们的对抗样本生成:M(x)表示通过注意模型获取的位置,G为GAN
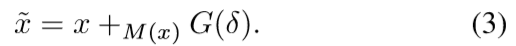
1. Visual Fidelity & Perceptual Correlation
对抗生成损失:z表示噪声,
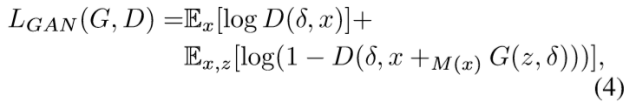
不同于条件GAN(cGAN),即使我们也可以将输入块作为条件。在PS-GAN中,生成器不需要噪声z也可以学习一个映射。实践中,我们仅以dropout的形式来提供噪声,应用于我们G的一些层。此外,我们同时结合了鉴别器和目标模型来指导对好发生器的追求,从而区分了原始图像和攻击,而不是同cGAN把干扰作为条件输入。
同时引入块损失来进一步增强与种子块和攻击图像的感知相关性,与图像的视觉融合包括像素级与视觉级。
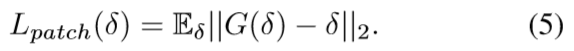
2.Attention Sensitivity & Attacking Ability
对抗损失:
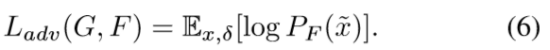
On the other hand,the attacking performance highly relies on the visual attention sensitivity of the attacked networks, which tries to explain which part of the image contributes more to the model decisions (Zeiler and Fergus 2014; Cao et al. 2015).
borrow the visual attention technique to predict the critical attacking area.
注意这里的注意力机制,他利用的是Grad-CAM,也就是利用网络回传梯度的大小,作为注意权重来判别安放位置。(并非原注意力模型。。。)
最终的块生成式:
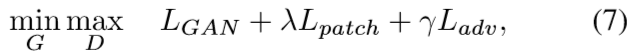
Network Architecture
GAN为基本的编解码器


具体的原理上面已经讲过,具体的细节还需要根据代码进一步理解。

块训练集表示最后生成对抗块的一个风格(涂鸦、黑白等等)
首先通过最大化生成器的损失来k步优化判别器W_D;
然后通过最小化总体损失来优化生成器W_G。
(他这里算法描述是相当于多次通过Grad-CAM来获取图像的注意权重,但是对于一张图象来说,梯度权重应该是固定的,不知道代码里面是如何利用的,待研究。)
论文指出对于G和D分别使用了Adam和SGD优化函数,,有待了解GAN。
实验
在数据集GTSRB和 ImageNet上通过三个方面比较我们的方法与 the state-of-the-art adversarial patch methods: GoogleAp 和 LaVAN :攻击成功率、视觉保真性及时间消耗。
然后探索了其在灰盒和黑盒下的可转移性和泛化性。
Datasets and Models
We choose QuickDraw (J.Jongejanand Fox-Gieg. 2016) as the corresponding patch dataset. QuickDraw is a collection of 50 million drawings and scrawls across 345 categories.
为了 generate scrawl-like adversarial patches 。
自己从数据集中选择了一些类别,包括 GTSRB 和ImageNet,块集的类别也是从ImageNet从自选的几个。
攻击模型:VGG16、ResNet-34,VY。
Implementation Details:Tensorflow and Keras、NVIDIA Tesla K80 GPU cluster、250 epochs with a batch size of 64, with the learning rate of 0.0002, decreased by 10% every 900 steps. As for the hyperparameters in loss function, we set λ range from 0.002 to 0.005 and γ to 1.0 and δ to 0.0001, respectively. (也没说为什么,就是直接取)
Comparative Experiments
Firstly, we compare the attacking performance of our method with GoogleAp and LaVAN on GTSRB and ImageNet.
Attacking Ability :这里对比了不同epoch下不同攻击的攻击效果,及块的更新结果。


表1展示了不同攻击方法的攻击效果,因为GoogleAp与LaVAN在生成块的过程当中是没有限制的,所以我们引入了弱限制版本即PS-GAN*,也即对应对应图3(e)-(f),表示扰动比较大的情况。扰动大、攻击效果好,但是牺牲了视觉保真度如Figure3(b)-(f)。
Visual Fidelity & Perceptual Correlation:

如图4所示,我们方法生成的对抗块相比于其他攻击方法生成的更加自然和和谐。
我们的模型使用受限的、感知相关度高的噪声来修改这些patch,因此对图像的扰动对人类来说是不可见的,但对深度学习模型却是致命的,会导致错误的分类。
Time Consumption
We also investigate ,
GoogleAp and LaVAN respectively spend 61.2s and 65.4s on producing one patch on GTSRB datasets, and similarly 72.3s and 81.5s on ImageNet. PS-GAN only takes 0.106s and 0.111s per patch for GTSRB and ImageNet, which means that PS-GAN enjoys both the fast computation and the ease for use in practice.
Semi-white box and Black box Attack
Semi-whitebox Setting

灰盒攻击下的攻击效果如上表。(灰盒攻击待理解,,)
Generalization Ability

测试在训练阶段没有见过的类别的图像和块输入模型,看其输出后图像的攻击效果如上。
(这里发现了之前存在的一个问题:可转移性指的是攻击模型产生的对抗样本对于不同模型的攻击效果;而泛化性指的是防御方法或者是攻击模型,对于未见过的攻击方法或样本,其原有的防御及攻击效果的能力是否仍有效) 。可转移可泛化不知道这样理解对不对?!
Transferability & Blackbox Attack

如上表3所示,对角线上的结果对应“白盒”或“半白盒”的攻击设置,而其他的结果对应“黑盒”的攻击。即训练阶段的目标模型与测试阶段的目标模型的异同。训练阶段产生的对抗块是否对其他不同分类模型有攻击效果。
Visual Attention

这个(b)图是怎么得出来的,,不太明白??
Physical World Attack
In this section, a physical world attack experiment is conducted to validate the practical effectiveness. 真实世界图像采集及作如下变换之后用于训练产生对抗块并贴附测试。

这篇关于对抗样本(论文解读五):Perceptual-Sensitive GAN for Generating Adversarial Patches的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





