本文主要是介绍PFC(1)—ball generate与ball distribute的区别、导出颗粒参数(位置及半径)、对导出的txt文件数据进行分列操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.ball generate与ball distribute的区别
(1)ball generate生成圆柱形试样
ball generate radius [keli_rdmin] [keli_rdmax] number 100 ...range cylinder end1 0 0 [sample_hight*0.5-keli_rdmin] ...end2 0 0 [-sample_hight*0.5+keli_rdmin] radius [sample_rad-keli_rdmin]
ball generate生成的颗粒无接触,对生产散体有优势
(2)ball distribute生成圆柱形试样
ball distribute radius [keli_rdmin] [keli_rdmax] porosity 0.2 ...range cylinder end1 0 0 [sample_hight*0.5-keli_rdmin] ...end2 0 0 [-sample_hight*0.5+keli_rdmin] radius [sample_rad-keli_rdmin]

ball distribute生成的颗粒会有重叠,能够控制孔隙率
2.生成一个圆柱试样不能够导出颗粒参数(位置及半径)
new
def chicun_par sample_rad=0.4sample_hight=sample_rad*2keli_rdmin=0.04keli_rdmax=0.08
end
@chicun_pardomain extent [-sample_rad*1.5] [sample_rad*1.5] [-sample_rad*1.5] [sample_rad*1.5] ...[-sample_hight*0.5*1.5] [sample_hight*0.5*1.5][n=1.4]
wall generate cylinder base 0 0 [-sample_hight*0.5*n] axis 0 0 1 ...height [sample_hight*n] radius [sample_rad] cap false falsewall generate plane position 0 0 [sample_hight*0.5] dip 0 ddir 0
wall generate plane position 0 0 [-sample_hight*0.5] dip 0 ddir 0ball generate radius [keli_rdmin] [keli_rdmax] number 100 ...range cylinder end1 0 0 [sample_hight*0.5-keli_rdmin] ...end2 0 0 [-sample_hight*0.5+keli_rdmin] radius [sample_rad-keli_rdmin]cmat default model linear method deform emod 10e8 kratio 1.5 property fric 0.5ball attribute density 2.7e3 damp 0.7
cycle 2000 calm 50solveball delete range cylinder end1 0 0 [sample_hight*0.5] ...end2 0 0 [-sample_hight*0.5] radius [sample_rad] notdef output_balls_infoball_num=ball.numfile_infp=array.create(ball_num+1)count=1file_infp(count)="pos_x pos_y pos_z radius"count+=1loop foreach local bp ball.listfile_infp(count) = string.build("%1 %2 %3 %4",ball.pos.x(bp),ball.pos.y(bp),ball.pos.z(bp),ball.radius(bp)) count+=1end_loop outflag=file.open("CubeWall.txt", 1, 1)file.write(file_infp,ball_num+1)file.close()
end
@output_balls_infosave sample
注意最后数据会导出在CubeWall.txt中,如果找不到数据可以在此电脑中进行搜索

3.对导出的txt文件数据进行分列操作
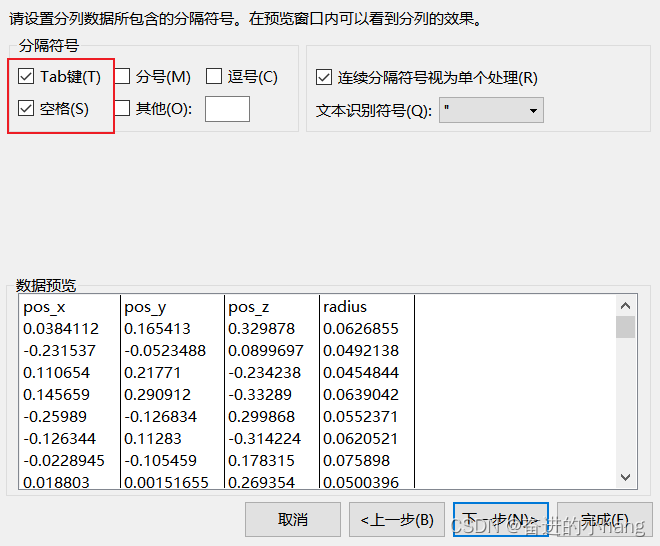
进行后处理,将数据导入到excel中进行分列,在导入数据的分隔符号中选择空格,分列的具体操作过程如下:

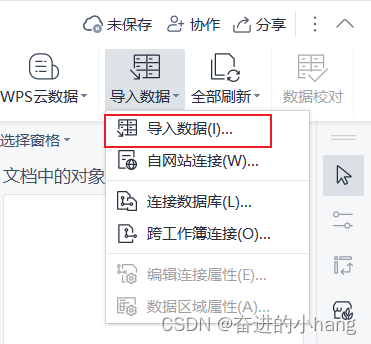
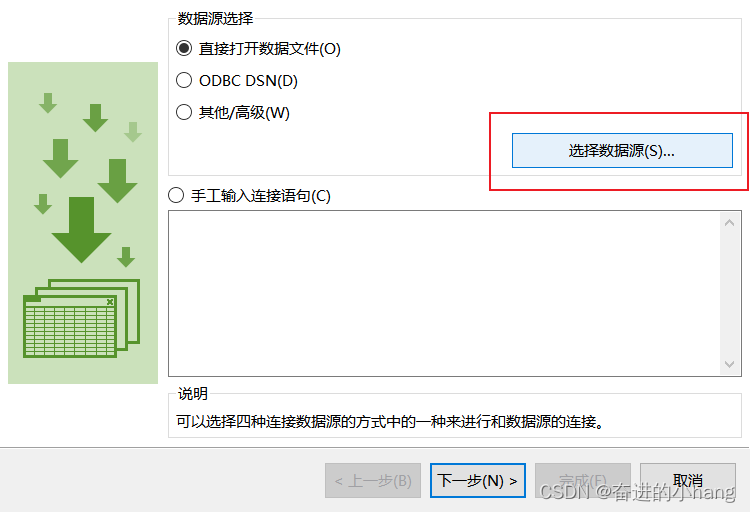
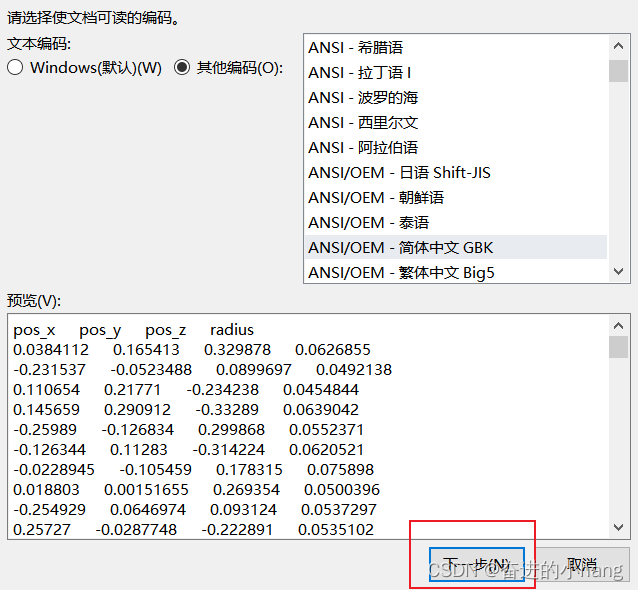
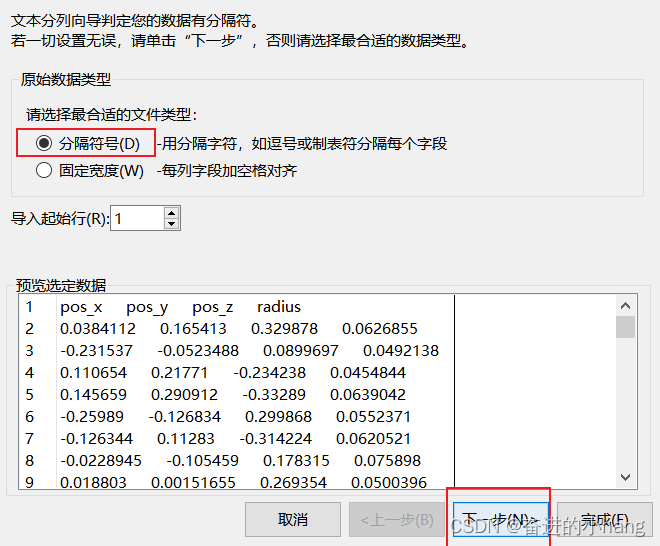
这篇关于PFC(1)—ball generate与ball distribute的区别、导出颗粒参数(位置及半径)、对导出的txt文件数据进行分列操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




