本文主要是介绍hive2、分桶、视图、高级查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
show databases ;
describe formatted student2;--查看表的类型
desc database kb23hivedb;
show create database kb23hivedb;
show create table student2;
--分桶(Bucket)***********************************************************************
(1)分桶对应于HDFS中的文件
更高的查询处理效率
使抽样(sampling)更高效
一般根据”桶列“的哈希函数将数据进行分桶
(2)分桶只有动态分桶
set hive.enforce.bucketing=true;
(3)定义分桶(分桶的列是表中已有的列,分桶数最好是2的N次方)
clustered by (emplyee_id) into 2 BUCKETS
(4)必须使用insert方式加载数据
(5)进行分桶,将一个文件分成两个文件,并且一个文件夹是奇数数据,一个文件是偶数数据
--------------------------------------------------建表--------------------------------------------------
create table emplyee_id_buckets(
name string,
emplyee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
clustered by (emplyee_id) into 2 BUCKETS --分为2个cluster,分桶为2的n次方/倍数
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
----------------------------------------------------------------------------------------------------------
select * from emplyee_id_buckets; --选择分桶所有数据
set map.reduce.tasks=2; --分桶2
set hive.enforce.bucketing=true; --分桶只有动态分桶
insert overwrite table emplyee_id_buckets select * from emplyee_id; --分桶加载数据
----------------------------------------------------------------------------------------------------------
(6)分桶随机抽样
(1)查看一兆的数据
select * from emplyee_id_buckets tablesample ( 1M )s;
(2)查看十行的数据
select * from emplyee_id_buckets tablesample ( 10 rows )s;
(3)查看10%数据
select * from emplyee_id_buckets tablesample ( 10 percent )s;
(4)查看30%数据
select * from emplyee_id_buckets tablesample ( 30 percent )s;
(5)抽取随机数据随机抽样:将2个cluster分进16个桶,2/16=八分之一,每个桶有八分之一cluster组成,抽取第3个桶中的数据即八分之三cluster数据
select * from emplyee_id_buckets tablesample ( bucket 3 out of 16 on rand())s;
(6)抽取随机数据指定emplyee_id抽样:将2个cluster分进4个桶,2/4=二分之一,每个桶有二分之一cluster组成,抽取第2个桶中的数据即1cluster数据
select * from emplyee_id_buckets tablesample ( bucket 2 out of 4 on emplyee_id)s;
--创建视图create view***********************************************************
一、视图概述
- 通过隐藏子查询、连接和函数来简化查询的逻辑结构
- 只保存定义,不存储数据
- 如果删除或更改基础表,则查询视图将失败
- 视图是只读的,不能插入或装载数据
二、应用场景
- 将特定的列提供给用户,保护数据隐私
- 用于查询语句复杂的场景
三、视图操作命令
(1)create --创建视图,支持cte\order by \limit \join 等
create view emplyee_id_view as select name,work_place from emplyee_id_buckets;
(2)show--查找视图 (在hive v2.2.0之后)
show tables ;
(3)show create --查找视图定义
show create tables emplyee_id_view;
(4)drop--删除视图
drop view emplyee_id_view;
(5)alter--修改视图属性
alter view emplyee_id_view set tblproperties (‘comment’=’this is a view’);
(6)alter--修改视图定义
alter view emplyee_id_view as select statement;
四、Hive侧视图(Lateral View)
(1)表生成函数结合使用,将函数的输入和输出连接
(2)outer关键字:即使output为空也会生成结果;explode炸裂
select * from emplyee lateral view outer explode(split(null, ’,’)) a as loc;
(3)支持多层级
查询name,skill,score,wps,其中skills_score炸裂成skill,score;work_place炸裂成wps
select name,skill,score,wps from emplyee
lateral view explode(skills_score) sks as skill,score
lateral view explode(work_place) work_place_single as wps;
(4)通常用于规范化行或解析JSON
--Hive高级查询***********************************************************
一、Hive查询-----select基础
select用于映射符合指定查询条件的行,select是数据库标准sql的子集
(1)select 用法类似于MySQL
(2)关键字和MySQL一样,不区分大小写
(3)limit子句
(4)where子句,运算符、like、rlike
(5)group by 子句
(6)having子句
SELECT 1;
SELECT * FROM table_name;
SELECT id,name,age FROM people WHERE age>20;
SELECT * FROM employee WHERE name!='Lucy' LIMIT 5;
select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
二、Hive查询----CTE和嵌套查询
(1)CTE(Common Table Expression)
CTE语法:with t1 as (select......) select * from t1;
CTE演示:
with tab1 as (select id,name,age from people) select * from tab1;
(2)嵌套查询
示例:select * from (select * from employee) a;
三、Hive查询----关联查询
指对多表进行联合查询
JOIN用于将两个或多个表中的行组合在一起查询
类似于sql join,但是Hive仅支持等值连接
| (1)内连接 :inner join | 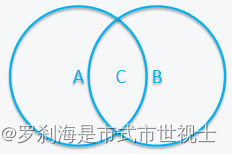 |
| area c=circlea1 join circle2 | |
| (2)外连接 :outer join (right join、left join、full outer join) | |
| area A=circlea1 left join circle2 --左外连接 area B=circlea1 right join circle2 --右外连接 ABC=circlea1 full outher join circle2 --完全外连接 | |
| (3)交叉连接 :cross join | |
| (4)隐式连接 :implicit join | |
| 示例: Select a.name from employee a left jion employee_hr b on a.name=b.name where b.name is null; Select a.name from employee a jion employee_hr b on a.name=b.name; | |
四、Hive JOIN-MAPJOIN
1、MapJoin操作在Map端完成:小表关联达标,可进行不等值连接。
2、开启mapjion操作:
Set hive.auto.convert.jion=true(默认值),运行时自动将连接转换为MAPJOIN。
3、MAPJION操作不支持:
在union all,lateral view,group by,jion,sort by,cluster by,distribute by等操作后面,在union,jion以及其他mapjion之前。
五、Hive集合操作(UNION)
(1)所有子集数据必须具有相同的名称和类型
Union all:合并后保留重复项
Union:合并后删除重复项(v.13.0之后)
(2)可以在顶层查询中使用(0.13.0之后)
(3)order by,sort by,cluster by,distribute by 和limit适用于合并后的整个结果
(4)集合其他操作可以使用JOIN/OUTER JOIN来实现:交集、差集
(5)示例
Select key from (select key from src1 order by key limit 10)sub
union all select key from src2 order by key limit 10;
六、装载数据:insert表插入数据
(1)使用insert语句将数据插入表/分区
(2)语法
Insert支持overwrite(覆盖)和into(追加)
insert overwrite/into table tablename1[partition (partcol1=val1,partcol2=val2,...)]select fileds,... from tb_other;
Hive 支持从同一个表进行多次插入,insert into中table关键字是可选的,insert into 可以指定插入到那些字段中,insert into table_name Values,支持插入值列表,数据插入必须与指定列数相同。
(3)使用insert语句将数据插入/导出到文件
文件插入只支持overwrite,支持来自同一个数据源/表的多次插入,local:写入本地文件系统,默认数据以TEXT格式写入,列由^A分割,支持自定义分隔符导出文件为不同格式,CSV,JSON等。
(4)示例
①从同一数据源插入本地文件,hdfs文件,表
From 表1
insert overwrite local directory ‘/tmp/out/’select*
insert overwrite directory ‘/tmp/out/’select*
insert overwrite table 表2 select* ;
②以指定格式插入数据
insert overwrite directory ‘/tmp/out/’select*
row format delimited fields terminated by ‘,’
select * from 表1;
③其他方式从表获取文件
hdfs dfs -getmerge <table_file_path>
七、Hive数据交换----import/export
import 导入
export 导出
(1)import和export用于数据导入和导出
常用于数据迁移场景,除数据库,可导入导出所有数据和元数据
(2)使用export导出数据
export table emplyee to '/employee.txt';--将数据导出到根目录
(3)使用import导入数据
import table emplyee from '/employee.txt';--将数据导入到emplyee表中
八、Hive排序----order by \ sort by
(1)order by(全局排序)
全局排序,只有一个Reducer,(desc降/倒序,asc升/正序,默认是升序),必须配合使用limit,支持按位置编号排序,支持使用case when或表达式,性能差,速度慢。
set hive.groupby.orderby.position.alias=true;
例:select * from offers order by 1/(case when offerid=1 then 1 else 0 end)/(......);
(2)sort by (分区内排序)
根据某个字段分区并内部排序,当reduce数量设置为1时,等于order by,必须出现在select column列表中。
(3)disteribute by(分区)
根据某个字段分区,类似于MapReduce中的分区Partationer对数据进行分区,默认采用Hash算法+取余数的方式,经常和sort by 配合使用,disteribute by写在sort by语句之前
例:select id,name,score from employee distribute by id sort by score desc;
(4)cluster by(分区排序)
cluster by=disteribute by+sort by
根据某个字段分区且根据这个字段排序,即具有disteribute by和sort by的功能,只能升序
例:select id,name,score from employee cluster by name;
九、Hive聚合运算----group by
group by 用于分组
hive基本内置聚合函数与group by 一起使用,如果没有指定group by 子句,则默认聚合整个表,除聚合函数外,所选的其他列也必须包含在group by 中,group by支持使用case when 或表达式。
例:
with
t1 as ( select explode(split(line,' ')) as word from docs )
select word,count(1) as countNum from t1 group by word order by word;
十、Hive聚合运算----having
having对group by 聚合结果的条件过滤,可以避免在group by 之后使用子查询。
(1)having使用
select uname, age,id from userapp2 group by uname having count(*)<=1;
(2)使用在查询代替having
select a.age fron(
select count(*) as cnt,age,sex from employee group by age
)a when a.cnt<=1;
十一、hive函数----collect_set(),collect_list()
collect_set()函数:
作用是将查询结果中某一列中的重复元素去重,并将不重复的元素组成一个集合。
collect_list()函数:
对指定的表达式进行聚合,并将每个行的值收集到一个列表中。最终,它返回一个包含所有值的列表。
案例一
with
t1 as (
select name,gender,
case when gender="boy" then 1 else 0 end as man,
case when gender="girl" then 1 else 0 end as woman,
case when gender="boy" or gender="girl" then 1 else 0 end as tag
from studenttp
)
select collect_set(gender) colset, collect_list(gender) collist from t1 group by tag;
案例二
with
t1 as (
select name,gender,
case when gender="boy" then 1 else 0 end as man,
case when gender="girl" then 1 else 0 end as woman,
case when gender="boy" or gender="girl" then 1 else 0 end as tag
from studenttp
),
t2 as (
select collect_set(gender) colset, collect_list(gender) collist from t1 group by tag
)
select * from t2;
案例三
with
t1 as (
select name,gender,
case when gender="boy" then 1 else 0 end as man,
case when gender="girl" then 1 else 0 end as woman,
case when gender="boy" or gender="girl" then 1 else 0 end as tag
from studenttp
),
t2 as (
select collect_set(gender) colset, collect_list(gender) collist from t1 group by tag
)
select concat_ws(",",colset),concat_ws(",",collist) from t2;
--Hive练习题******************************************************************************************
-- app表
drop table apptest;
create table apptest(
id int,
appname string
)
row format delimited fields terminated by '|'
lines terminated by '\n';
load data local inpath '/opt/kb23/app.txt' into table apptest;-- 加载数据
--app用户表
create table userapptest(
name string,
appname string
)
row format delimited fields terminated by '|'
lines terminated by '\n';
load data local inpath '/opt/kb23/userapp.txt' into table userapptest;-- 加载数据
题目:将用户表中没有的app展示出来
--答案(1)*****************************************************************************************
with
usertb as (select name from userapptest group by name),
userapp1 as (select a.id,a.appname,u.name uname from apptest as a cross join usertb as u),
userapp2 as (select u1.appname appname,u1.uname
from userapp1 u1 left join userapptest u on u1.appname=u.appname and u1.uname=u.name
where u.name is null)
-- select * from userapp2;
select uname, concat_ws(",",collect_set(appname)) from userapp2 group by uname;
--答案(2)**************************************************************************************
with
t1 as (select name, collect_list(appname) as applist from userapptest group by name),
t2 as (select * from t1 cross join apptest where !array_contains(applist,appname))
select name,collect_set(appname) from t2 group by name;
这篇关于hive2、分桶、视图、高级查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






