本文主要是介绍阅读论文:Label-Free Liver Tumor Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:Label-Free Liver Tumor Segmentation
翻译:无标记的肝肿瘤分割
摘要
论文的目的:肿瘤合成,通过使用合成数据来改进医学图像分析和AI在肝脏肿瘤检测方面的性能
我们的主要贡献是合成了一种肿瘤生成器,它提供了以下五个优点:
1. 合成策略将医学知识嵌入可执行程序中,通过放射科医生和计算机科学家的协作,实现了逼真肿瘤的生成,无需手动标注成本。2. 整个训练阶段不需要标注成本,并且生成的模型在无监督异常分割方法和肿瘤合成策略方面明显优于先前的方法。3. 在合成肿瘤上训练的AI模型在真实肿瘤分割方面可以达到与使用真实肿瘤和逐像素标注训练的AI模型类似的性能,并且可以推广到具有健康肝脏的CT扫描和其他医院的扫描。4. 合成策略可以生成多种规模的肿瘤用于模型训练,包括小、中、大规模的肿瘤,因此具有检测小肿瘤和促进早期发现肝癌的潜力。5. 合成策略允许直接操纵参数,如肿瘤位置、大小、纹理、形状和密度,提供了全面的测试平台,用于评估AI模型的性能。

方法
为了定位肝脏,我们首先将预先训练好的nnUNet1应用于CT扫描。有了肝脏的大致位置,然后我们开发了一系列形态图像处理操作来合成肝脏内的真实肿瘤。
肿瘤生成包括四个步骤:(1)位置选择 (2)纹理生成 (3)形状生成 (4)后处理。
位置选择
肿瘤位置非常关键,因为肝肿瘤通常不允许任何血管(如肝静脉、门静脉和下腔静脉)通过它们。为了避免血管,首先通过阈值法对图像进行血管分割。血管分割得到血管掩膜。有了血管掩膜,人们可以检测到选定的位置是否有使肿瘤与血管相撞的风险。在提出随机位置(X,Y,Z)∈{x,y,z|L(x,y,z)=1}后,通过判断肿瘤半径r范围内是否有血管进行碰撞检测,如果∃v(x,y,z)=1,∀x∈[X−r,X+r],y∈[Y−r,Y+r],z∈[Z−r,Z+r],则存在碰撞风险,因此需要重新选择位置。该过程反复进行,直到找到没有冲突的肿瘤位置(xt,yt,zt)。
分段的血管掩膜公式如下:
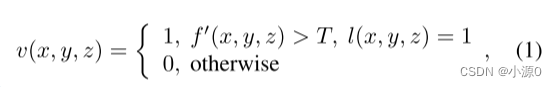
其中f’(x, y, z) 是平滑后的CT扫描,F’(x,y,z)=f(x,y,z)⊗g(x,y,z;σa),通过将具有标准差σa的高斯滤波器g(x,y,z;σa)应用于原始CT扫描f(x,y,z);⊗是标准的图像过滤操作符。平滑可以有效地消除CT重建带来的噪声。阈值T被设置为略大于肝脏的平均Hounsfield单位(HU)的值。
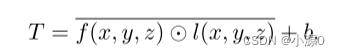
其中L(x,y,z)是肝脏掩码(background=0,liver=1),中间那个圆圈里边一点是逐点乘法,b是超参数。
有了理想的肿瘤位置,我们就能够生成肿瘤的纹理和形状。
纹理生成
纹理生成:肝脏和肿瘤纹理的HU值(Hounsfield单位)遵循高斯分布。
-
生成高斯噪声(Gaussian Noise):首先,你生成了一个具有特定均值(µt)和与肝实质相同标准差(σp)的3D高斯噪声。这个高斯噪声模拟了肿瘤的基本密度。
-
三次样条插值:为了减少高斯噪声的锐利性,你在x、y、z方向上使用了三次样条插值,将高斯噪声进行缩放。缩放后的纹理表示为T’(x, y, z),这有助于使纹理更加平滑和逼真。
-
缩放因子η:缩放因子η决定了生成的纹理的粗糙程度。η = 1 表示无缩放,较大的η值会导致更大的颗粒感,使生成的纹理更接近真实肿瘤的外观。
-
高斯滤波器:最后,为了模拟CT扫描的成像质量,你使用了高斯滤波器g(x, y, z; σb)对纹理进行模糊处理。这一步可以模拟图像在采集和重建过程中的模糊效应。
形状生成
大多数肿瘤从中心生长并逐渐肿胀,使小肿瘤(即20毫米)接近球形。所以我们用椭球体产生类似肿瘤的形状。
我们从均匀分布U(0.75r,1.25r)中随机抽取椭球体x,y,z方向的半轴长度,并将生成的椭球体掩模放置在(xt,yt,zt)的中心。对于生成的椭球体肿瘤掩模t(x,y,z)(background=0,liver=1) ,并且具有与扫描体积f(x,y,z)相同的形状,应用由σe控制的弹性变形[45,48]来丰富其多样性。变形的肿瘤面膜在外观上更接近自然生长的肿瘤,而不是简单的椭球体。此外,它还可以通过学习形状语义不变性来提高模型的稳健性。变形的肿瘤掩膜表示为t’(x,y,z)。为了使生成的肿瘤和周围肝实质之间的过渡更自然,我们最后通过应用高斯过滤器g(x,y,z;σc)来模糊掩模,更具体地说,我们得到模糊形状T’‘(x,y,z)=t’(x,y,z)⊗g(x,y,z;σc)。
后处理
后处理的第一步是将肿瘤放置在扫描体积 f(x, y, z) 和相应的肝脏掩膜 l(x, y, z) 上。假设肿瘤掩膜数组 t’‘(x, y, z) 和纹理数组 T’'(x, y, z) 与 f(x, y, z) 和 l(x, y, z) 具有相同的形状。通过以下方程,我们可以获得带有肿瘤的新扫描体积:
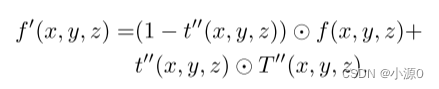
在新的带有肿瘤的掩膜中(background=0,liver=1,tumor=2),它可以通过以下方式合成:
l’(x, y, z) = l(x, y, z) + t’'(x, y, z)
放置了肿瘤后,我们采取另外两个步骤,以使生成的肿瘤对医学专业人员更加逼真。这两个步骤旨在模拟肿瘤的质量效应和包膜外观。
质量效应意味着扩张的肿瘤会将周围的组织分开。如果肿瘤足够大,它将压缩周围的血管,使它们弯曲,甚至可能导致附近肝脏的边缘凸起。在这项工作中,采用局部缩放变形来实现质量效应。它将圆形内的像素重新映射到离圆周更近的位置。对于距离γ到圆心的像素,重新映射后的像素距离γ’为:
γ’ = (1 - (1 - γ/γ max) ^ 2 · I/100 ) · γ
其中γmax是扩展圆形区域的半径,I ∈ [0, 100] 是控制扩展强度的超参数。较大的I会导致更强烈的变形。请注意,当I = 0时,重新映射将减小为恒等函数γ’ = γ。重新映射过程应用于扫描和掩膜体积。变形后的体积被命名为 f’‘(x, y, z) 和 l’'(x, y, z)。后者(肝脏/肿瘤分割标签)现在已准备好进行后续训练。
最后,我们通过提亮肿瘤边缘来模拟包膜的外观。边缘区域可以通过以下方式获得:

其中,其中 lb 和 ub 是用于从肿瘤掩膜中提取边缘的下限和上限。然后,我们增加模糊边缘区域的HU强度以模拟包膜:
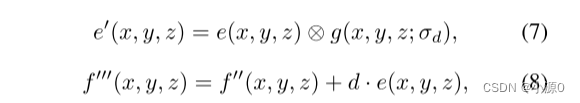
其中,d 是预定义的肿瘤和其包膜之间的HU强度差,新的扫描体积 f’‘’(x, y, z) 已准备好用于训练或图灵测试。
这个 我们使用的参数如表1所示。可视化示例 样本可以在附录图8-10中找到
肝脏肿瘤的临床知识
这项工作专注于生成肝细胞癌(一种由肝细胞生长的肿瘤)。
在注射对比剂后,肝脏的临床检查过程通常分为三个阶段,包括肝动脉期(注射后30秒)、门静脉期(注射后60-70秒)和延迟期(注射后3分钟)。
通常,只有前两个阶段用于检测肝细胞癌,不同阶段肿瘤的HU(Hounsfield单位,用于测量CT图像中组织的密度)强度值分布不同。
肝动脉期平均密度为111HU(32 - 207HU),门静脉期平均为106HU(36 - 162HU)。
动脉期病变与肝脏的平均差值为26HU(范围-44~146HU)。
平均而言,肝细胞癌在门静脉期比邻近肝实质少11HU(范围从-98到61HU)。
相对较轻的肝细胞癌通常导致较小、较少的球形病变。在大多数情况下,只有一个小的肿瘤出现。而多灶病变,也就是分散的小肿瘤,只在少数情况下出现。
较严重的肝细胞癌通常呈现卫星病变,即一个大的病变被一群小病变包围。大中央病变的形状也比小病变更加不规则。
较大的肿瘤通常显示出明显的肿块效应,伴随着包膜出现,将肿瘤与肝实质分开。
总体的流程示意图如下:
在随机选择一个避开血管的位置后,我们为肿瘤生成高斯纹理和变形的椭球体形状。然后,纹理和形状被组合并放置在所选位置。此外,我们还采取了另外两个后处理步骤来使生成的肿瘤更加逼真:(1)通过局部缩放扭曲来扩大肿瘤边缘;(2)通过亮化肿瘤边缘来生成包膜。四个步骤,淡绿色,仅用于视觉图灵测试(不用于培训)。

实验
1. 数据集
使用LiTS数据集,该数据集提供了肝脏肿瘤的详细的每体素注释。肝脏肿瘤的体积范围从38mm³到349cm³,肿瘤的半径在[2, 44]mm的范围内。研究采用了5折交叉验证,遵循了Tang等人的相同数据划分方法。AI模型(例如U-Net)在包含了101个CT扫描的训练数据上进行训练,这些CT扫描具有标注的肝脏和肝脏肿瘤。
为了进行比较,还从CHAOS (20个CT扫描)、BTCV (47个CT扫描)、Pancreas-CT (38个CT扫描)以及LiTS中的健康受试者(11个CT扫描)中组装了一个包含健康肝脏的数据集,总共116个CT扫描。然后,研究在这些扫描中生成了肿瘤图像,从而产生了大量的合成肿瘤图像-标签对,用于训练AI模型。
为了训练模型,生成了五个不同大小的肿瘤级别,参数和示例可以在附录表6和图11中找到。
2. 评估指标
在这项研究中,肿瘤分割性能是通过以下指标进行评估的:
-
Dice相似系数(Dice Similarity Coefficient,DSC):用于度量生成的肿瘤分割与真实分割之间的相似度。DSC值越高,表示分割结果越接近真实情况。
-
标准化表面Dice(Normalized Surface Dice,NSD):这是一种用于评估分割结果在表面上的一致性的指标。它考虑了分割结果在肿瘤表面的匹配程度,并且具有2mm的容忍度。
此外,肿瘤检测性能是通过以下指标进行评估的:
-
敏感性(Sensitivity):用于度量模型正确检测出真实肿瘤的能力。它计算了模型正确检测到的肿瘤数量与实际存在的肿瘤数量之间的比例。
-
特异性(Specificity):用于度量模型正确排除没有肿瘤的区域的能力。它计算了模型正确排除的没有肿瘤的区域数量与实际没有肿瘤的区域数量之间的比例。
对于所有上述指标,研究团队计算了95%的置信区间(95% CIs)以进行统计分析,并使用小于0.05的p值作为定义统计显著性的截止值。这些指标和统计分析有助于评估模型的性能和结果的可信度。
3. 实施
使用了MONAI2框架来实现U-Net和Swin UN-ETR模型的代码。输入图像首先被裁剪到窗口范围[-21, 189],然后进行归一化,使其具有零均值和单位标准差。在训练过程中,从3D图像体积中随机裁剪了96×96×96大小的图像块。所有模型都进行了4,000个时期的训练,基本学习率为0.0002。每个GPU上的批次大小为两个。他们采用了线性预热策略和余弦退火学习率调度。在推断阶段,他们使用滑动窗口策略,并将重叠区域比例设置为0.75。
零均值 (Zero Mean): 这意味着对图像的每个像素值减去图像所有像素值的平均值。
单位标准差 (Unit Standard Deviation): 这意味着对图像的每个像素值除以图像所有像素值的标准差。
结果与讨论
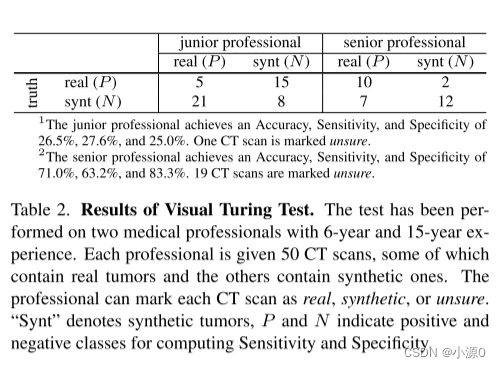
在临床验证中使用了视觉图灵测试
这项测试使用了50份CT扫描数据,其中包括20份来自LiTS的真实肿瘤扫描,以及30份来自WORD的健康肝脏扫描,但在这些健康扫描中添加了合成的肿瘤。测试由两名具有不同经验水平的医学专业人员参与。他们可以在3D视图中检查每个样本,这意味着可以通过滚动鼠标观察连续的切片序列。
测试结果如表所示:
与最先进的方法进行比较
作者使用无标签肿瘤合成方法与其他无监督肿瘤分割方法进行比较的结果。
研究发现,作者的方法明显优于其他方法,实现了更高的分割性能,这表明了从需要大量标签的肿瘤分割范式转向无标签肿瘤分割的潜力。
对不同模型和数据的概括
作者对合成肿瘤的通用性进行了验证。他们使用了Swin UNETR模型的不同变体,并发现在LiTS数据集上,模型在真实肿瘤上的表现略优于在合成肿瘤上的表现,但两者之间没有统计学差异。此外,他们还使用来自其他数据集的数据对模型的领域泛化能力进行了评估,发现使用来自3个不同数据集的健康数据进行训练的模型在外部数据集上表现更加稳健,特别是在特异性方面表现更好。这对于临床应用非常重要,因为更高的特异性可以减少需要进行侵入性诊断程序以及相关成本的患者数量。
在小肿瘤检测中的潜力
研究强调了通过合成数据生成大量肿瘤,特别是小肿瘤,对于训练AI模型以提高癌症早期检测的效能至关重要。在真实数据集中,早期小肿瘤案例很少,因此AI模型在检测这些小肿瘤方面表现较差。通过使用合成肿瘤数据,研究人员成功地解决了真实数据中大小不平衡的问题,并且证明合成小肿瘤可以显着提高模型的检测性能。这对于及时癌症诊断具有重要意义,可以帮助提高患者的生存率。
可控鲁棒性基准测试
在医学成像领域,标准的AI评估方法通常仅关注肿瘤检测的有效性,但现有测试数据集中的标注肿瘤数量不足以代表真实情况。为了更全面地评估AI在不同大小和位置的肿瘤检测中的性能,作者使用合成肿瘤作为资源,通过调整多个维度的超参数来合成不同特征的肝脏肿瘤,包括位置、大小、形状、强度和纹理。这使得他们能够创建大量合成肿瘤来测试不同情况下的AI模型,包括失败情况。作者还指出,通过将最糟糕情况的合成肿瘤加入训练集并进行微调,可以改进AI算法的性能。最后,他们使用合成肿瘤创建了一个超出分布(o.o.d.)基准测试,以评估不同模型的鲁棒性,发现这些模型在形状、位置和纹理方面表现良好,但对极端大小和强度的肿瘤比较敏感。
关于形状生成的消融研究
设计了消融研究,重点关注形状生成和合成小肿瘤。
在两个方面评估了使用不同合成策略设置的模型:所有肿瘤分割和小肿瘤检测。
在不合成小肿瘤、不进行边缘模糊或不进行弹性变形的形状生成的情况下,性能会大大下降。
原因很简单:
(1) 在形状生成时没有弹性变形和边缘模糊步骤,生成的肿瘤可能非常不真实(即边缘锐利且形状只能是椭球)。附录图12提供了一些示例。
(2) 当训练集中没有小肿瘤(半径<5mm)时,模型缺乏对小肿瘤的泛化能力。
一些词的含义:
“预定义的平均HU强度µt” 是指事先定义的用于表示肿瘤纹理的平均Hounsfield单位(HU)值。这个平均HU值µt用于确定肿瘤的整体密度或灰度级别。在医学图像中,HU值是衡量组织密度的一种方式,通常用于CT扫描中。不同类型的组织具有不同的HU值范围,它们反映了X射线在组织中的吸收程度。
“标准差σp” 表示用于描述肿瘤纹理变化或分布的统计度量。在这里,它表示肿瘤纹理的HU值的变化或分散程度。具有较小标准差的纹理具有较一致的密度,而具有较大标准差的纹理具有更大的变化。
这篇关于阅读论文:Label-Free Liver Tumor Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









