本文主要是介绍论文阅读--Cell-free massive MIMO versus small cells,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
无蜂窝大规模MIMO与小蜂窝网络
论文信息
Ngo H Q, Ashikhmin A, Yang H, et al. Cell-free massive MIMO versus small cells[J]. IEEE Transactions on Wireless Communications, 2017, 16(3): 1834-1850.
无蜂窝大规模MIMO中没有小区或者小区边界的界定,所有接入点通过回程网络进行相位相干协作,并通过时分双工(TDD)操作为同一时频资源中的所有用户提供服务。分布式MIMO系统的替代方案是部署由不合作的接入点组成的小型小区。
在现有文献中,没有考虑不完善的CSI、导频分配和功率控制的影响的小蜂窝和分布式大规模MIMO系统之间的全面性能比较。
分布式MIMO与集中式MIMO的对比
cellfree-massive MIMO无蜂窝MIMO,与传统的蜂窝式网络不同的是,无蜂窝网络本质是分布式MIMO,其特点是天线数目多,AP与用户都是单天线,网络覆盖范围广,边缘用户通信质量好;集中式MIMO收发都是多天线,受终端尺寸限制,天线的扩展是有限的,因此分集增益也是有限的,此外,由于接收端天线距离比较近,增大了接收信号的相关性,分集增益也被减小,因此分布式MIMO在可靠性方面优与集中式MIMO,但是他也存在缺点,天线部署比较分散,因此增大了信号传输的时间,以增加回程为代价,提高接收性能。基于上述分析,论文选用分布式MIMO模型。
创新点:
- 考虑一种下行链路具有共轭波束形成、上行链路具有匹配滤波的无蜂窝大规模MIMO。实验表明,与集中系统的情况一样,当接入点的数量趋于无穷大时,非相干干扰、小尺度衰落和噪声的影响消失。
- 推导了具有有限数量接入点和用户的无蜂窝大规模MIMO下行链路和上行链路的严格闭式容量下界。分析考虑了信道估计误差、功率控制和导频序列的非正交性的影响。
- 比较了两种导频分配方案:随机分配和贪婪分配。
- 设计了最大化所有用户速率—最小公平功率控制算法。全局最优解可以通过求解下行链路的二阶锥规划序列和上行链路的线性规划序列来计算。
- 在不相关和相关阴影衰落模型下,定量比较了无蜂窝大规模MIMO和小蜂窝系统的性能。
II. CELL-FREE MASSIVE MIMO SYSTEM MODEL
该部分是对本文中无蜂窝大规模MIMO模型进行基本说明
考虑一个具有M个AP和K个用户的无小区大规模MIMO系统。所有接入点(AP)和用户都配备了单个天线,并且随机分布在很大的区域。此外,所有接入点都通过回程网络连接到中央处理器,见图1。
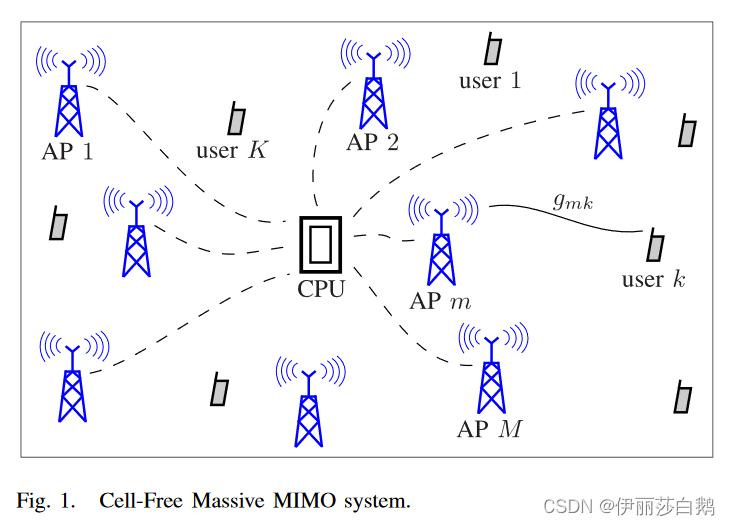
我们假设所有M个AP同时服务于相同时频资源中的所有K个用户。从AP到用户的传输(下行链路传输)和从用户到AP的传输(上行链路传输)通过TDD操作进行。每个相干间隔分为三个阶段:上行链路训练、下行链路有效载荷数据传输和上行链路有效载荷数据传输。在上行链路训练阶段,用户向AP发送导频序列,每个AP向所有用户估计信道。如此获得的信道估计用于对下行链路中的发射信号进行预编码,并检测从上行链路中的用户发射的信号。 在这项工作中,为了避免接入点之间共享信道状态信息,我们考虑下行链路中的共轭波束形成和上行链路中的匹配滤波。
III. PERFORMANCE ANALYSIS
无蜂窝大规模MIMO性能分析
M为AP数量
1、M–>∞
在本节中,将提供一些关于M非常大时无小区大规模MIMO系统性能的见解。收敛性分析是以一组确定的大尺度衰落系数{β mk}为条件进行的。我们表明,与集中式大规模MIMO的情况一样,当M→∞时,用户和接入点之间的信道变成正交的。因此,采用共轭波束形成分别进行匹配滤波,消除了非相干干扰、小尺度衰落和噪声。唯一剩下的损害是导频污染,它包括在训练阶段使用与感兴趣的用户相同的导频序列的用户的干扰。
2、Achievable Rate for Finite M
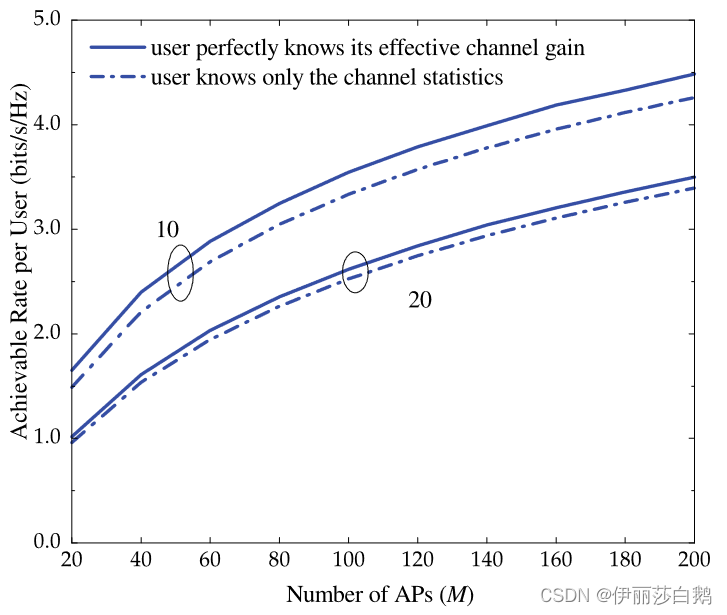
有限M的可达速率,本节给出了对任意数量AP和用户计算单个用户吞吐量的下限表达式。
前者假设用户只知道信道统计数据,后者假设知道实现。如图所示,差距很小,说明不需要下行训练。
IV. PILOT ASSIGNMENT AND POWER CONTROL
导频分配算法
当不同用户有正交的导频序列时,信道估计模型会变的很简单。由于导频序列的长度为 τ c f τ^{cf} τcf,最多只能存在 τ c f τ^{cf} τcf个正交的导频。因此需要讨论存 τ c f τ^{cf} τcf与K个用户的分配问题。
如果 τ c f τ^{cf} τcf≥K,我们只需将K个正交导频序列分配给K个用户。
导频分配算法解决的重点:
如果 τ c f τ^{cf} τcf<K,我们则需要考虑如何分配正交导频序列给K个用户。
Random Pilot Assignment 随机分配导频
随机导频分配是一个有用的方法,但偶尔两个彼此靠近的用户会使用相同的导频序列,这会导致严重的导频污染。
Greedy Pilot Assignment 贪婪分配导频
贪婪分配导频通过简单的贪婪算法,迭代细化导频分配。首先随机分配K个用户K个导频序列。然后,具有最低下行链路速率的用户,更新其导频序列,导频的选择通过计算导频污染效应最小化时的导频分配。
全局最优功率控制算法
将上下行链路功率分配问题转化为最优化问题。计算出最优解时各用户获得相同的速率。
V. S MALL-CELL SYSTEM
小蜂窝模型介绍,目的是为第六章与无蜂窝大规模MIMO系统进行性能对比。
VI. NUMERICAL RESULTS AND DISCUSSIONS
在不相关和相关阴影衰落下,还进行了无蜂窝大规模MIMO系统和小小区系统之间的比较。结果表明,无蜂窝大规模MIMO系统在吞吐量方面明显优于小蜂窝系统。特别是,无蜂窝系统比小蜂窝系统对阴影衰落相关性更鲁棒。具有阴影相关性的无蜂窝大规模MIMO的的每用户吞吐量比小蜂窝系统高一个数量级。然而,就实现复杂性而言,小蜂窝系统比无蜂窝大规模MIMO需要更少的回程。
这篇关于论文阅读--Cell-free massive MIMO versus small cells的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)