本文主要是介绍【经验分享】PT(persistent table)表异常导致gprecoverseg全量恢复失败的探索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

了解更多Greenplum相关内容,欢迎访问Greenplum中文社区网站
背景
最近来自中兴通讯的系统架构师、敏捷教练王爱军在工作过程中,遇到gp5.20通过 gprecoverseg -F做全量恢复失败的异常。master和primary的pg_log日志中打印internal error,然后primary crash。本文分享问题的定位过程以及涉及到相关概念,供大家学习参考。
一、问题现象
1.1 集群状态查看
[gpadmin@instance-eqmn04jr pg_log]$ gpstate -s
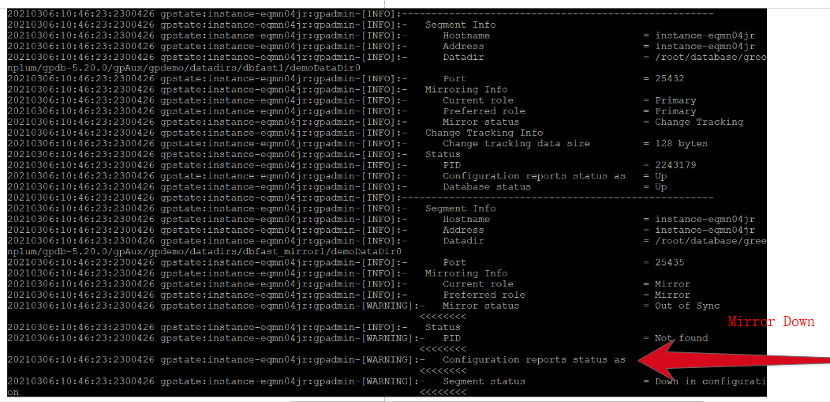
图1 Mirror Down
1.2 全量恢复
[gpadmin@instance-eqmn04jr pg_log]$ gprecoverseg -F
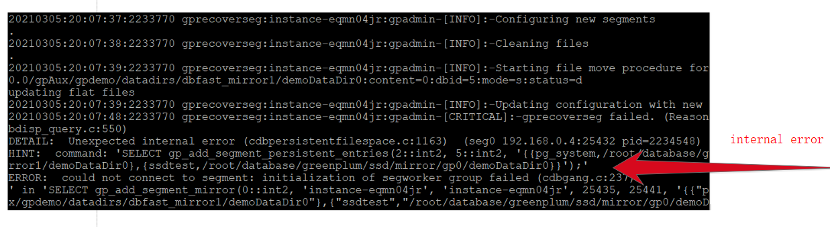
图2 gprecoverseg失败
1.3 master日志

图3 master pg_log
-
日志打印:QE执行command失败
could not execute command on QE (cdbdisp_query.c:550)","Unexpected internal error (cdbpersistentfilespace.c:1163)。
-
QE:Query Executor对应primary segment。
-
QD:Query Dispatcher对应master。
1.4 primary日志
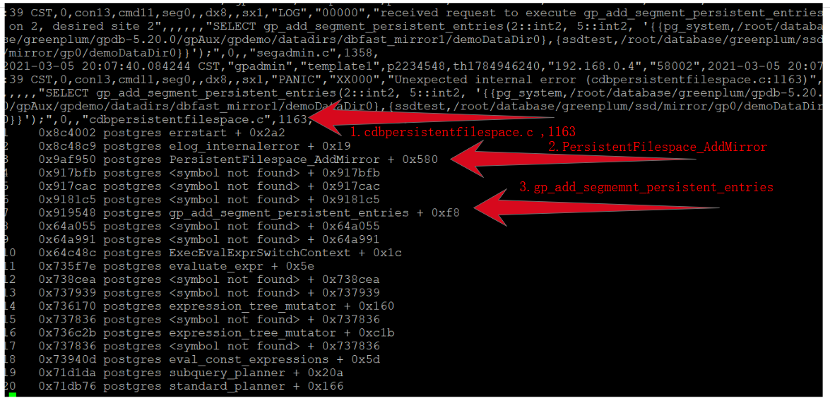
图4 master pg_log
日志中线索:
- "cdbpersistentfilespace.c",1163行代码抛异常。
- PersistentFilespace_AddMirror 被调用
- gp_add_segment_persistent_entries被调用
二、源码分析
代码位置:src/backend/cdb/ cdbpersistentfilespace.c
2.1 函数入口
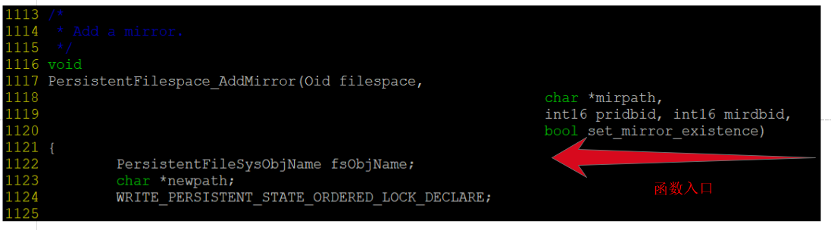
图5 函数入口
函数入参数说明:
-
filespace:文件空间oid
-
mirpath:mirror路径
-
pridbid:primary dbid
-
mirdbid:mirror dbid
2.2 抛错代码1163行
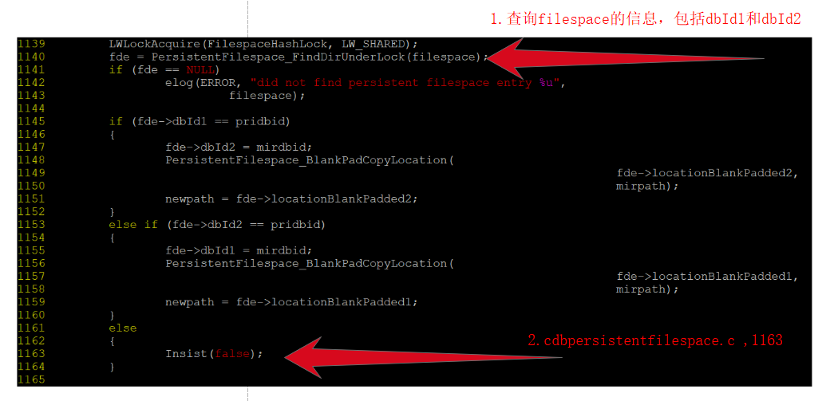
图6 抛错代码
代码分析可以得到:
-
filespace对应的dbId1和dbId2 都不等于当前的pridbid,因而抛异常。
-
PT表(gp_persistent_filespace_node )数据可能出现不一致。
2.3 gp_persistent_filespace_node数据
i. utility方式查看filespace的PT信息
[gpadmin@instance-eqmn04jr cdb]$ PGOPTIONS='-c gp_session_role=utility' psql -dpostgres -p 25432

图7 PT filespace信息
ii. 查看segment信息
[gpadmin@instance-eqmn04jr cdb]$ psql -dpostgres

图8 segment信息
很明显gp_persistent_filespace_node中的db_id_1=21是一个不存在的dbid,在进行filespace状态同步匹配不到,从而抛错。正确的db_id_1应该为port=25432对应的dbid=2。
2.4 问题解决
i.更新PT(gp_persistent_filespace_node表)为正确值。
示例:
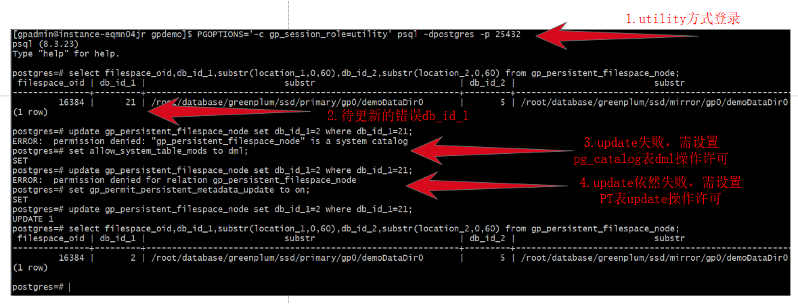
图9 更新PT表
(注:i.catalog表修改非常危险不要随意操作)
ii.重启集群,然后再次全量同步恢复mirror。
iii.PT表的修复需要在原厂专业人员指导下操作,否则可能会导致整个集群启动失败。
2.5 问题回顾
PT表的信息错误,遇到的非常偶然,该故障的定位和修复过程非常曲折,如不修复对整个集群有很大风险。
该故障应该是gp5.20的版本bug,已反馈给原厂研发人员,但由于故障难以复现,修复可能需要一些时间。很可能是数据库负荷过重,在做gprecoverseg增量恢复的时候primary segment crash,进而导致的状态同步信息没有正确的更新到对应的PT表中。
图10 release notes
三、概念说明
3.1 PT 表
PT(persistent table)的包含如下四张表,使用场景为通过gprecoverseg进行segment恢复,跟踪对象恢复的状态。

表1 PT表
3.2 实体对应的层次关系
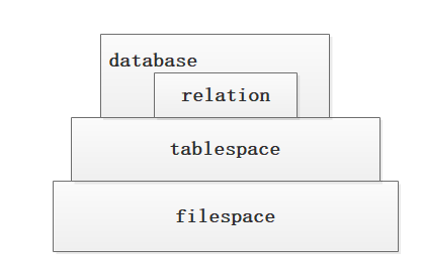
图11 实体层次关系
为了提升IO能力,文件空间filespace可以指向高速存储,如ssd。表空间建立在对应的filespace,表建立在相应的tablespace上。创建文件空间的命令可以参考gpfilespace用法。PT表和filespace概念适用于gp5.x版本,gp6.x 取消了filespace以及PT表。
四、总结
本文总结了通过pg_log日志和源代码相结合,进行全量恢复失败的问题定位和解决过程。通过该方式可以洞悉问题的本源,对更好的运维Greenplum数据库提供帮助。
五、参考信息
https://github.com/greenplum-db/gpdb
https://docs.greenplum.org
https://cn.greenplum.org
作者简介
王爱军,中兴通讯系统架构师&敏捷教练
20年来一直工作在一线的老码农,目前就职于中兴通讯。主要工作方向为5G网络管理系统架构,近期在使用和研究Greenplum。

这篇关于【经验分享】PT(persistent table)表异常导致gprecoverseg全量恢复失败的探索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





