本文主要是介绍oracle相同数据取第一条,oracle去除重复, 获取取最新的第一条数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近项目中的一条sql语句涉及到取一个表中相同工单编码中最新的一条数据,在网上看到一函数完美解决此问题,如下是内容要点:
问题:在项目中有一张设备检测信息表DEVICE_INFO_TBL, 每个设备每天都会产生一条检测信息,现在需要从该表中检索出每个设备的最新检测信息。也就是device_id字段不能重复,消除device_id字段重复的记录,而且device_id对应的检测信息test_result是最新的。
解决思路:用Oracle的row_number() over函数来解决该问题。
解决过程:
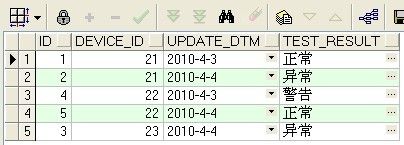
1.查看表中的重复记录
select
t.id,
t.device_id,
t.update_dtm,
t.test_result
from DEVICE_INFO_TBL t
2.标记重复的记录
select
t.id,
t.device_id,
t.update_dtm,
t.test_result,
row_number() OVER(PARTITION BY device_id ORDER BY t.update_dtm desc) as row_flg
from DEVICE_INFO_TBL t
这篇关于oracle相同数据取第一条,oracle去除重复, 获取取最新的第一条数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





