本文主要是介绍365天深度学习训练营之好莱坞明星识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/xLjALoOD8HPZcH563En8bQ) 中的学习记录博客**
>- **🍦 参考文章:365天深度学习训练营-第6周:好莱坞明星识别(训练营内部成员可读)**
>- **🍖 原作者:[K同学啊|接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**
一、前期工作
环境:
● 语言环境:Python3.6.5
● 编译器:jupyter notebook
● 深度学习框架:TensorFlow2.6.2
● 显卡(GPU):NVIDIA GeForce RTX 3070
1.设置GPU
from tensorflow import keras
from tensorflow.keras import layers,models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as npgpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")gpus
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2.导入数据
data_dir = "D:\\deeplearning\\day06\\data\\"data_dir = pathlib.Path(data_dir)
3.查看数据
image_count = len(list(data_dir.glob('*/*.jpg')))print("图片总数为:",image_count)
图片总数为: 1800
roses = list(data_dir.glob('Jennifer Lawrence/*.jpg'))
PIL.Image.open(str(roses[0]))

二、数据预处理
1. 加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
测试集与验证集的关系:
- 验证集并没有参与训练过程梯度下降过程的,狭义上来讲是没有参与模型的参数训练更新的。
- 但是广义上来讲,验证集存在的意义确实参与了一个“人工调参”的过程,我们根据每一个epoch训练之后模型在valid data上的表现来决定是否需要训练进行early stop,或者根据这个过程模型的性能变化来调整模型的超参数,如学习率,batch_size等等。
- 因此,我们也可以认为,验证集也参与了训练,但是并没有使得模型去overfit验证集
batch_size = 32
img_height = 224
img_width = 224
label_mode:
- int: 标签将被编码成整数(使用的损失函数应为: sparse_categorial_crossentropyloss)
- categorical: 标签将被编码为分类向量(使用的损失函数应为:categorical_crossentropy loss)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.1,subset="training",label_mode = "categorical",seed=123,image_size=(img_height, img_width),batch_size=batch_size) # 默认值为32
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.1,subset="validation",label_mode = "categorical",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
Found 1800 files belonging to 17 classes.
Using 1620 files for training.
Found 1800 files belonging to 17 classes.
Using 180 files for validation.
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
['Angelina Jolie', 'Brad Pitt', 'Denzel Washington', 'Hugh Jackman', 'Jennifer Lawrence', 'Johnny Depp', 'Kate Winslet', 'Leonardo DiCaprio', 'Megan Fox', 'Natalie Portman', 'Nicole Kidman', 'Robert Downey Jr', 'Sandra Bullock', 'Scarlett Johansson', 'Tom Cruise', 'Tom Hanks', 'Will Smith']
2.可视化数据
plt.figure(figsize=(20, 10))for images, labels in train_ds.take(1):for i in range(20):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[np.argmax(labels[i])])plt.axis("off")

3.再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
(32, 224, 224, 3)
(32, 17)
● Image_batch是形状的张量(32,224,224,3)。这是一批形状224x224x3的32张图片(最后一维指的是彩色通道RGB)。
● Label_batch是形状(32,)的张量,这些标签对应32张图片
4. 配置数据集
● shuffle() :打乱数据,关于此函数的详细介绍可以参考:https://zhuanlan.zhihu.com/p/42417456
● prefetch() :预取数据,加速运行
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、构建CNN网络
卷积神经网络(CNN)的输入是张量 (Tensor) 形式的 (image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。不需要输入batch size。color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道(color channel)。在此示例中,我们的 CNN 输入的形状是 (224, 224, 4)即彩色图像。我们需要在声明第一层时将形状赋值给参数input_shape。
"""
关于卷积核的计算不懂的可以参考文章:https://blog.csdn.net/qq_38251616/article/details/114278995layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""model = models.Sequential([layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3 layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样layers.Dropout(0.5), layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.AveragePooling2D((2, 2)), layers.Dropout(0.5), layers.Conv2D(128, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.Dropout(0.5), layers.Flatten(), # Flatten层,连接卷积层与全连接层layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取layers.Dense(len(class_names)) # 输出层,输出预期结果
])model.summary() # 打印网络结构

四、训练模型
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
● 损失函数(loss):用于衡量模型在训练期间的准确率。
● 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
● 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
1.设置动态学习率
# 设置初始学习率
initial_learning_rate = 1e-4lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate, decay_steps=60, # 敲黑板!!!这里是指 steps,不是指epochsdecay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lrstaircase=True)# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)model.compile(optimizer=optimizer,loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
2.早停与保存最佳模型参数
关于ModelCheckpoint的详细介绍可参考文章 https://blog.csdn.net/qq_38251616/article/details/122318957
EarlyStopping()参数说明:
● monitor: 被监测的数据。
● min_delta: 在被监测的数据中被认为是提升的最小变化, 例如,小于 min_delta 的绝对变化会被认为没有提升。
● patience: 没有进步的训练轮数,在这之后训练就会被停止。
● verbose: 详细信息模式。
● mode: {auto, min, max} 其中之一。 在 min 模式中, 当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
● baseline: 要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。
● estore_best_weights: 是否从具有监测数量的最佳值的时期恢复模型权重。 如果为 False,则使用在训练的最后一步获得的模型权重。
关于EarlyStopping()的详细介绍可参考文章 https://blog.csdn.net/qq_38251616/article/details/122319538
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStoppingepochs = 100# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',monitor='val_accuracy',verbose=1,save_best_only=True,save_weights_only=True)# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy', min_delta=0.001,patience=20, verbose=1)
3.模型训练
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[checkpointer, earlystopper])
Epoch 00079: val_accuracy did not improve from 0.41111
Epoch 80/100
51/51 [==============================] - 1s 17ms/step - loss: 0.0616 - accuracy: 0.9840 - val_loss: 4.2230 - val_accuracy: 0.3833Epoch 00080: val_accuracy did not improve from 0.41111
Epoch 81/100
51/51 [==============================] - 1s 17ms/step - loss: 0.0672 - accuracy: 0.9852 - val_loss: 4.1273 - val_accuracy: 0.3722Epoch 00081: val_accuracy did not improve from 0.41111
Epoch 82/100
51/51 [==============================] - 1s 17ms/step - loss: 0.0580 - accuracy: 0.9864 - val_loss: 4.1715 - val_accuracy: 0.3778Epoch 00082: val_accuracy did not improve from 0.41111
Epoch 00082: early stopping
五、模型评估
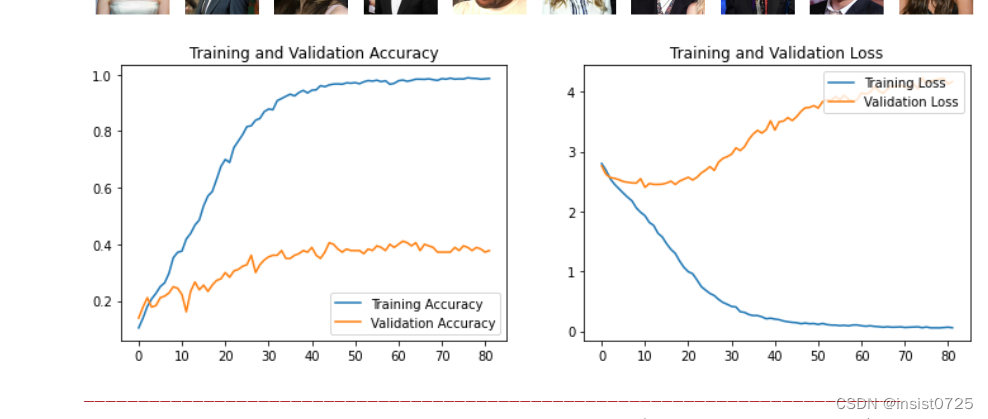
1.Loss与Accuracy图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(len(loss))plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2.指定图片预测
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
from PIL import Image
import numpy as npimg = Image.open("D:\\deeplearning\\day06\\data\\Jennifer Lawrence\\003_963a3627.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])img_array = tf.expand_dims(image, 0) predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])
预测结果为: Jennifer Lawrence
这篇关于365天深度学习训练营之好莱坞明星识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




