本文主要是介绍国家行政区数据获取三种方式:爬虫、调用API、私有化部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
国家行政区数据获取三种方式:爬虫、调用API、私有化部署
背景
现实情况,在信息系统开发、电子商务平台、app等等相关软件开发,都会设计到行政区数据联动,但是如何获取最新、准确的数据呢?
在这里给各位推荐三种获取方式
一、Python国家行政区数据爬取示例【源码可运行】
这里里给初学者、有需要的人提供一个数据抓取的脚本,有效、可运行,将抓取的数据写入到本地csv文件中
不废话,上代码:
- 注意:改代码可以抓取:省、市、区、乡镇街道、村社区 五级完整行政区,由于村社区数量比较大,抓取方法调用被注释了,有需要的可以取消注释
from bs4 import BeautifulSoup
import csv
import re
import requestsclass XingZhengQu(object):def __init__(self):self.session = requestsself.initCsvWriter()def initCsvWriter(self):self.csvFile = open('xingzhengqu.csv', 'w')self.csvWriter = csv.writer(self.csvFile)self.csvWriter.writerow(['行政代码','名称','层级','类型'])def csvWriteRow(self,row):self.csvWriter.writerow(row)# 省def getProvice(self):url='http://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2022/index.html'resp = self.session.get(url)resp.encoding='utf-8'soup = BeautifulSoup(resp.text, 'lxml')a = soup.select('table.provincetable > tr.provincetr > td >a')for item in a:proviceUrl = item.get('href')pid = re.findall("([0-9]+)\.html",proviceUrl)print('--',pid,proviceUrl)code = pid[0].ljust(12,'0')print('{}-{}-{}'.format(code,item.get_text(),1))row =[code,item.get_text(),1,'']self.csvWriteRow(row)cityUrl = '{}/{}'.format(url.rsplit('/',1)[0],proviceUrl)self.getCity(cityUrl)# 市def getCity(self,url):print('getCity',url)resp = self.session.get(url)resp.encoding='utf-8'soup = BeautifulSoup(resp.text, 'lxml')trs = soup.select('table.citytable > tr.citytr')for tr in trs:a = tr.select('td > a')if len(a)>0 :cityUrl = a[0].get('href')print('{}-{}-{}'.format(a[0].get_text(), a[1].get_text(), 2))row =[a[0].get_text(),a[1].get_text(),2,'']self.csvWriteRow(row)cityUrl = '{}/{}'.format(url.rsplit('/',1)[0],cityUrl)self.getCounty(cityUrl)else:td=tr.select('td')if len(td)>0 :row =[td[0].get_text(),td[1].get_text(),2,'']self.csvWriteRow(row)# 区def getCounty(self,url):print('getCounty',url)resp = self.session.get(url)resp.encoding='utf-8'soup = BeautifulSoup(resp.text, 'lxml')trs = soup.select('table.countytable > tr.countytr')for tr in trs:a = tr.select('td > a')if len(a)>0 :countryUrl = a[0].get('href')print('{}-{}-{}'.format(a[0].get_text(), a[1].get_text(), 3))row =[a[0].get_text(),a[1].get_text(),3,'']self.csvWriteRow(row)cityUrl = '{}/{}'.format(url.rsplit('/',1)[0],countryUrl)self.getTown(cityUrl)else:td=tr.select('td')if len(td)>0 :row =[td[0].get_text(),td[1].get_text(),3,'']self.csvWriteRow(row)# 县、镇、街道def getTown(self,url):resp = self.session.get(url)resp.encoding='utf-8'soup = BeautifulSoup(resp.text, 'lxml')trs = soup.select('table.towntable > tr.towntr')for tr in trs:a = tr.select('td > a')if len(a)>0 :townUrl = a[0].get('href')print('{}-{}-{}'.format(a[0].get_text(), a[1].get_text(), 4))row =[a[0].get_text(),a[1].get_text(),4,'']self.csvWriteRow(row)cityUrl = '{}/{}'.format(url.rsplit('/',1)[0],townUrl)# 取消村落抓取(太多)# self.getVillage(cityUrl)else:td=tr.select('td')if len(td)>0 :row =[td[0].get_text(),td[1].get_text(),4,'']self.csvWriteRow(row)# 居委会、村落def getVillage(self,url):resp = self.session.get(url)resp.encoding='utf-8'soup = BeautifulSoup(resp.text, 'lxml')trs = soup.select('table.villagetable > tr.villagetr')for tr in trs:a = tr.select('td')print('{}-{}-{}'.format(a[0].get_text(), a[2].get_text(), 5,a[1].get_text()))row =[a[0].get_text(), a[2].get_text(), 5,a[1].get_text()]self.csvWriteRow(row)pet = XingZhengQu()
pet.getProvice()数据样例
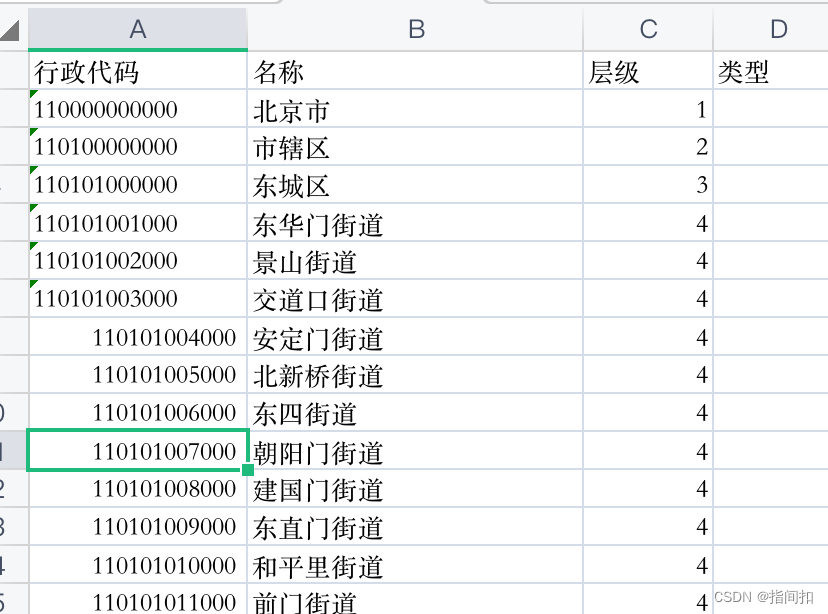
二、调用现成的接口
调用接可以省去每次数据更新后还需要同步数据,数据齐全,及时更新
接口调用简单
接口优势:
- 1、可查询全国范围内的省、市、区及县城的详细信息;
- 2、查询范围广,反馈信息内容丰富
- 3、专人技术维护,保证服务随时畅通。
免费的API接口: 全国行政区划查询appkey获取
接口调用示例:
import requests
import jsonclass XingZhengQu(object):def __init__(self):self.session = requestsdef apiGet(self):params={'key':'appkey','fid':'320000'}resp = self.session.get('http://apis.juhe.cn/xzqh/query',params)resp_json = json.loads(resp.text)print(resp_json)
pet = XingZhengQu()
pet.apiGet()
返回数据:
{"reason": "success","result": [{"id": "320100","name": "南京市","fid": "320000","level_id": "2"},{"id": "320200","name": "无锡市","fid": "320000","level_id": "2"},{"id": "320300","name": "徐州市","fid": "320000","level_id": "2"},{"id": "320400","name": "常州市","fid": "320000","level_id": "2"},{"id": "320500","name": "苏州市","fid": "320000","level_id": "2"},{"id": "320600","name": "南通市","fid": "320000","level_id": "2"},{"id": "320700","name": "连云港市","fid": "320000","level_id": "2"},{"id": "320800","name": "淮安市","fid": "320000","level_id": "2"},{"id": "320900","name": "盐城市","fid": "320000","level_id": "2"},{"id": "321000","name": "扬州市","fid": "320000","level_id": "2"},{"id": "321100","name": "镇江市","fid": "320000","level_id": "2"},{"id": "321200","name": "泰州市","fid": "320000","level_id": "2"},{"id": "321300","name": "宿迁市","fid": "320000","level_id": "2"}],"error_code": 0
}
三、数据私有化部署
除了自己抓取、接口调用,还有一种懒人是数据获取,私有化部署,定期下载更新数据源,无需其他处理
具体相见一下链接:
全国行政区划查询私有化部署文档
这篇关于国家行政区数据获取三种方式:爬虫、调用API、私有化部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





