本文主要是介绍[2020ECCV]Contrastive Learning for Unpaired Image-to-Image Translation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[2020ECCV]Contrastive Learning for Unpaired Image-to-Image Translation
对比学习用于无配对图像转换
文章链接:https://arxiv.org/pdf/2007.15651.pdf
代码:GitHub - taesungp/contrastive-unpaired-translation: Contrastive unpaired image-to-image translation, faster and lighter training than cyclegan (ECCV 2020, in PyTorch)
简介:
在图像到图像的转换中,输出中的每个patch都应该反映输入中相应patch的内容,而不受域的限制。为此,我们提出了一种简单的方法——使用基于对比学习的框架,最大化两者之间的相互信息。
该方法鼓励两个元素(对应的patch)映射到可学习特征空间的一个相似点,相对于数据集中的其他元素(其他patch),称为negatives。 我们探索了几个关键的设计选择,以使对比学习在图像合成设置中有效。 值得注意的是,我们使用多层、基于patch的方法,而不是对整个图像进行操作。 此外,我们从输入图像本身中提取negatives,而不是从数据集的其余部分中提取。
如图1所示;我们希望输出具有目标域(斑马)的外观,同时保留特定输入马的结构或内容。从根本上说,这是一个解纠缠问题:将需要跨域保存的内容与必须更改的外观分开。
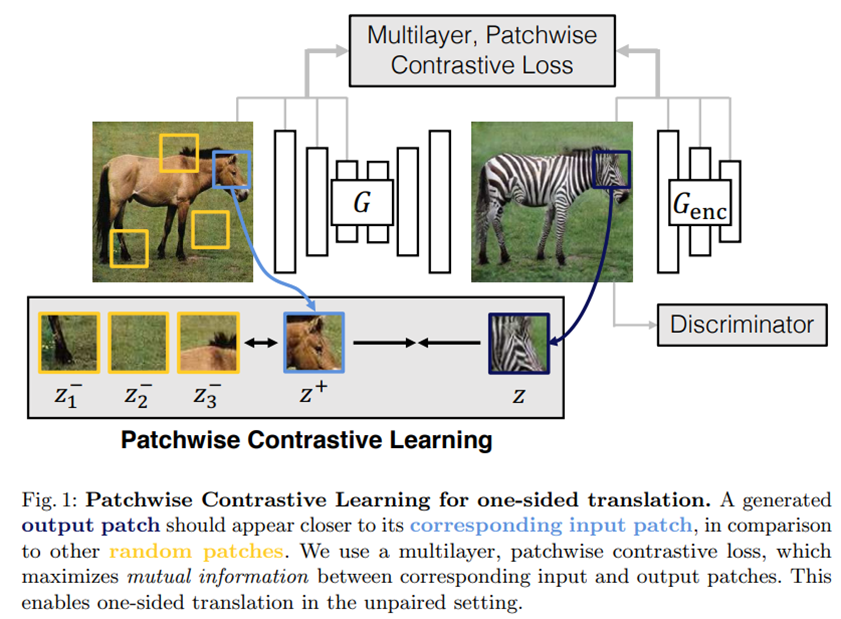
图1:patch层级的对比学习用于单边翻译。与其他随机patch相比,生成的输出patch应该更接近其相应的输入补丁。我们使用多层,patch层级的对比损失,最大限度地提高了相应的输入和输出patch之间的相互信息。这使得在未配对的图像中可以进行单方面的翻译。
通常,目标外观(班马的条纹)是使用对抗损失来进行的,而内容是使用循环一致性来保留的。然而,循环一致性假设两个域之间的关系是双射,这通常是限制性的。在一个成功的结果中,给定输出上的一个特定补丁,例如,生成的斑马额头用深蓝色突出显示,人们应该很清楚它来自马的前额,而不是来源于图中其他部分。
我们通过使用一种对比损失函数InfoNCE loss来实现这一点,它的目的是学习一个嵌入或编码器,将相应的patch相互关联,同时将它们与其他patch分离。
为此,编码器学会注意两个领域之间的共性,如物体的结构和形状,同时对差异保持不变,如动物的纹理。
生成器和编码器这两个网络共同生成图像,这样patch就可以很容易地追踪到输入。
此外,从输入图像内部直接提取nagetives,而不是从数据集中的其他图像外部取nagetives,使得patches更好地保存输入的内容。我们的方法既不需要memory bank,也不需要专门的架构。
对比学习(自监督学习一种方法):
一些方法利用噪声对比估计,学习一种将相关信号聚集在一起的嵌入,与数据集中的其他样本形成对比。相关信号可以是带有自身的图像,带有其下游表示的图像,图像内的相邻patches,或输入图像的多个视图,最成功的是带有一组自身转换版本的图像。
方法:
输入一些图像x,将生成器分为编码器Genc和解码器Gdec,生成y^= G(z) = Gdec (Genc (x))。
使用一个噪声对比估计框架来最大化输入和输出之间的相互信息。
对比学习的思想是关联两个信号,一个“query”和它的“positive”例子,与数据集中的其他点(称为“negetive”)形成对比。
query, positive,和N个 negatives分别被映射到K维向量v,v+∈ RK 和 v - ∈ RN×K ,其中v-n第n个negative。
我们的目标是关联输入和输出数据。在我们的背景中,query指的是输出。positive和nagetive的是对应的和不对应的输入。例如在图1中,输出斑马图像深蓝色的方框z指的就是query,输入马的图像中蓝色的框z+指的就是对应的positive,黄色的框z-指的就是nagetives。
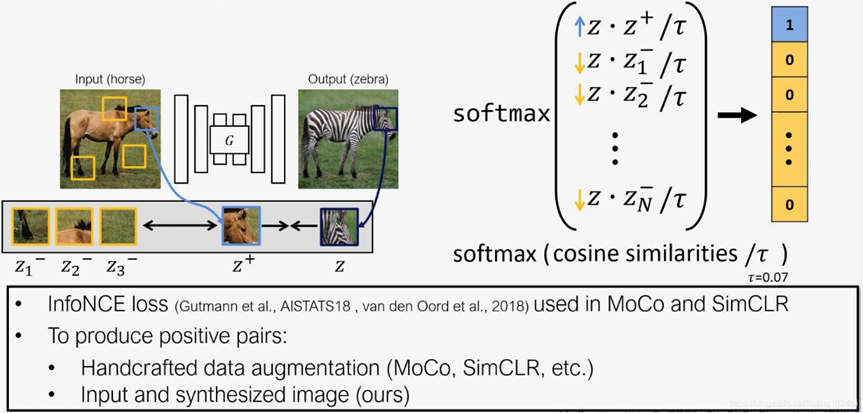
我们将向量归一化到一个单位球面上,以防止空间坍缩或膨胀。一个(N + 1)方向分类问题被建立,其中query与其他样例之间的距离按温度系数τ = 0.07进行缩放,并传递为logits。
交叉熵损失被计算,代表positive例被选择的概率超过nagetives例。
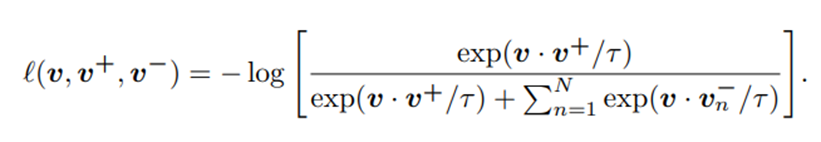
由于编码器Genc被计算来产生图像翻译,它的feature stack是容易获得的,我们可以利用它。该feature stack中的每一层和空间位置都代表输入图像的一个patch,更深的层对应更大的patch。选择感兴趣的第L层,并通过一个小的两层MLP网络Hl传递特征映射。生成一个特征堆栈 {zl}L= {Hl(Glenc(x))}L,其中Glenc表示所选的第L层的输出。我们索引到层l∈{1,2,…, L},表示s∈{1,…, Sl},其中Sl为每层空间位置的个数。


我们的目标是在特定位置匹配相应的输入-输出patch。我们可以利用输入中的其他patch作为nagetives。并命名为PatchNCE损失,如图二。

其中l为上面的(可以当成softmax的一种形式):

相比于对比学习需要使用internal loss+external loss,CUT仅仅使用internal loss。
external NCE loss:利用来自数据集其余部分的图像patch。我们从数据集中encode一张nagetive图像x˜为{z˜l}L,也就是接下来的externalNCE loss:
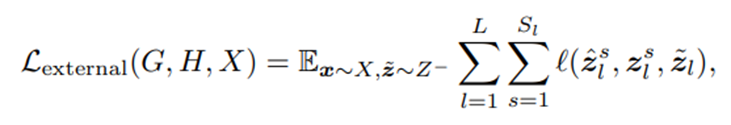
在这个变体中,我们使用一个辅助的moving-averaged encoder来维持一个大的、一致的nagetives字典。z˜l是从外部字典Z−从源域采样的,其中的数据都要使用该编码器Hˆl和MLP层Hˆ。(external NCE来自于MoCo)。
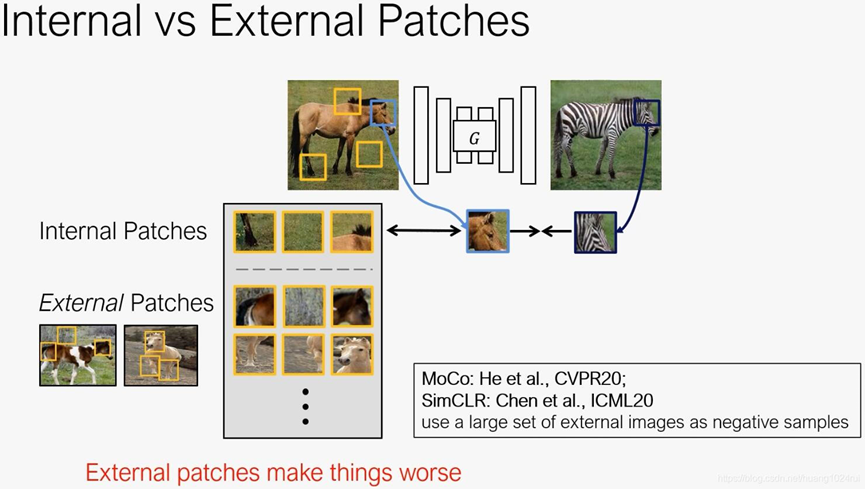
我们的编码器Genc学会了捕捉了领域不变性,比如马→斑马的动物身体、背景中的草和天空,而我们的解码器Gdec学会了合成领域特定的特征,比如斑马条纹。我们的编码器不需要建模大的类内变化,如白马vs.棕马,这对于生成输出斑马是不必要的。
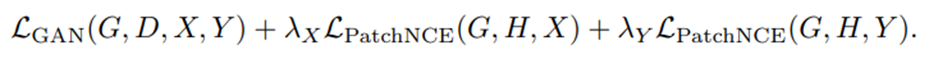
最终的目标函数,和CycleGAN一样也添加一致损失(identity loss)LPatchNCE(G, H, Y),对来自域Y的图像使用PatchNCE损失LPatchNCE(G, H, Y),(即生成图像y自身输入生成器生成的图像y~,y和y~再做一个PatchNCE损失),以防止生成器进行不必要的更改。
在等式损失为λY = 1的情况下,我们联合训练时选择λX = 1。在λY = 0的情况下,选择更大的值λX = 10来补偿正则化的缺失。前一种构型命名为对比未配对翻译(CUT),在性能上优于现有的方法。而后者被称为FastCUT,可以被认为是一个更快、更轻的CycleGAN版本。与最近经常使用5-10个损失和超参数的方法相比,我们的模型相对简单。
讨论:
Li et al.已经证明循环一致性损失是条件熵H(X|Y)(和H(Y |X))的上界。因此,最小化周期一致性损失鼓励输出y更依赖于输入x。这与我们最大化互信息I(x,y)的目标有关,因为I(x, y) = H(x)−H(x | y)。由于熵H(X)是一个常数,且与生成器G无关,使互信息最大化等同于使条件熵最小化。
值得注意的是,使用对比学习,我们可以在不引入反向映射网络和额外的鉴别器的情况下实现类似的目标。在我们的设置中,我们最大化了两个高维图像空间之间的互信息,其中简单的损失不再有效。我们使用对比学习来加强内容一致性,而不是改善对抗损失本身。为了测量两个分布之间的相似性,the Contextual Loss使用了从预先训练的网络中提取的特征的余弦距离上的softmax。相比之下,我们学习了带有NCE损失的编码器,以将输入和输出补丁关联在同一位置。
评估方案:
我们利用广泛使用的Fr´echet初始距离(FID)度量,该度量在深度网络空间中经验地估计真实图像和生成图像的分布,并计算它们之间的散度。直观地说,如果生成的图像是真实的,它们应该在任何特征空间中具有与真实图像相似的汇总统计信息。
在本文中,Fr´echet Inception Distance (FID[26])是通过PyTorch框架的双线性采样将图像大小调整为299 × 299来计算的,然后取预训练的最后一个平均池化层的激活Inception V3使用TensorFlow框架提供的权重。
我们使用默认设置:
https://github.com/mseitzer/pytorch-fid
所有测试集图像都用于评估。
训练细节:
为了显示所提出的基于patch的对比损失的效果,我们故意匹配CycleGAN的架构和超参数设置,但损失函数除外。这包括基于resnet的生成器,有9个剩余块,PatchGAN鉴别器,最小二乘GAN损耗,批大小为1,和Adam优化器[38],学习率0.002。
我们的完整模型CUT被训练到400个epoch,而快速变体FastCUT被训练到200个epoch,遵循CycleGAN。
此外, FastCUT使用flip-equivariance增强进行训练,其中对生成器的输入图像进行水平翻转,并在计算PatchNCE损失之前将输出特征翻转回来。
我们的编码器Genc是CycleGAN生成器的前半部分。为了计算我们的多层,基于补丁的对比损失,我们从5层中提取特征,这5层是RGB像素,第一和第二下采样卷积,以及第一和第五残差块。我们使用的层对应于大小为1×1、9×9、15×15、35×35和99×99的接受字段。对于每一层的特征,我们随机采样256个位置,并应用2层MLP来获得256维度的最终特征。对于我们使用MoCo风格的memory bank的baseline模型,我们遵循MoCo的设置,使用动量值0.999,温度0.07。每层memory bank的大小为16384个,每次迭代我们对每张图像排列256个patch。
这篇关于[2020ECCV]Contrastive Learning for Unpaired Image-to-Image Translation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!