本文主要是介绍论文阅读——INCORPORATING BERT INTO NEURAL MACHINE TRANSLATION,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://openreview.net/pdf?id=Hyl7ygStwB
将BERT引入机器翻译
代码:https://github.com/bert-nmt/bert-nmt
BERT在文本分类、阅读理解等多种NLP任务上都显示出了强大的能力。然而,如何将BERT有效应用于NMT还缺乏足够的探索。作者提出了 BERT-fused model,首先使用BERT提取输入序列的表征,然后通过注意机制将该表征与NMT模型的encoder和decoder的每一层进行融合。作者分别在有监督(句子级和文档级翻译)、半监督和非监督的机器翻译上进行实验,并在七个基准数据集上获得了目前最先进的结果。
把BERT表征注入所有层,而不是仅仅作为输入嵌入。使用注意机制自适应地控制每一层如何与表征交互,并处理BERT模块和NMT模块可能使用不同的分词规则,从而导致不同的表征序列长度。与标准的NMT相比,除了BERT之外,还有两个额外的注意力模块:BERT-encoder attention, BERT-decoder attention。输入序列首先被转换成BERT处理过的表征,然后通过BERT编码器注意模块,每个NMT编码器层与输入BERT表征进行交互,最终输出二者的融合表征。解码器的工作原理与此类似。
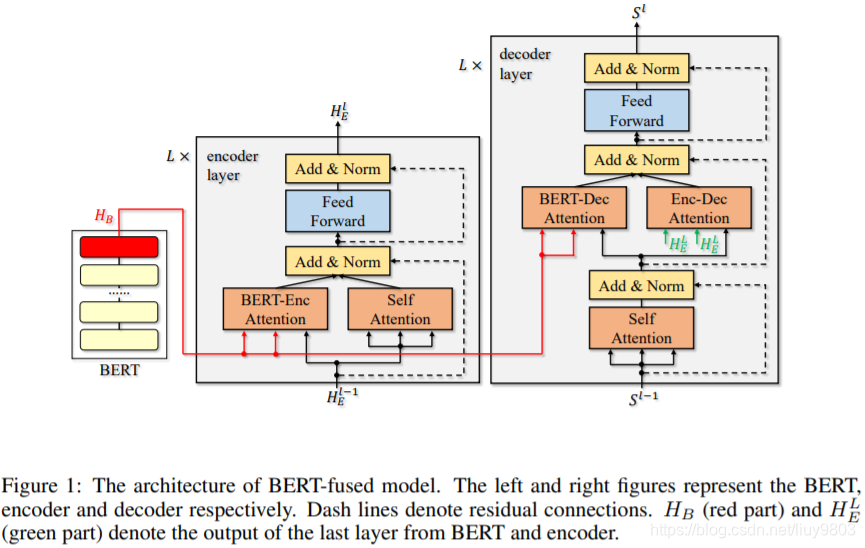
令X和Y分别表示源语言和目标语言域,对于任意句子x∈X、y∈Y,令 表示x和y中的单词个数,x / y中的第 i 个单词记为
。将编码器、解码器和BERT分别表示为Enc、Dec和BERT,并将编码器和解码器称为NMT模块,假设编码器和解码器都为L层。
1. 对于任意句子 x∈X,经过BERT编码输出得到 ,x中第 i 个wordpiece表示为
2. 令 表示encoder第 l 层的隐层表征,
表示x的词向量。对任意
,
中第 i 个元素
有:
![]()
、
和
分别表示自注意力模型、BERT-编码/解码器注意力模型和编码器-解码器注意力模型,然后经过前馈神经网络 FFN(.),得到第 l 层的输出,最终得到encoder最后一层的输出:
![]()
3. 令 表示在 t 时间步之前的decoder第 l 层隐状态:

迭代最终得到 ,通过线性映射和softmax预测第 t 个单词
。
Drop-Net Trick
使用 drop-net 技巧,以充分利用BERT和encoder的输出特征。令drop-net rate ,每次迭代训练时,对于任何层l,从[0, 1]区间统一采样随机变量
,计算所有的
:

其中, 为指示函数。对于概率为
的层,只使用
或者只使用
;对于概率为
的层,两种注意力模型均被使用。例如,在特定的迭代中,第一层可能只使用
,而第二层只使用
。解码时使用每个注意力模型的输出期望:
同样的,对于训练解码器使用drop-net trick:

实验结果
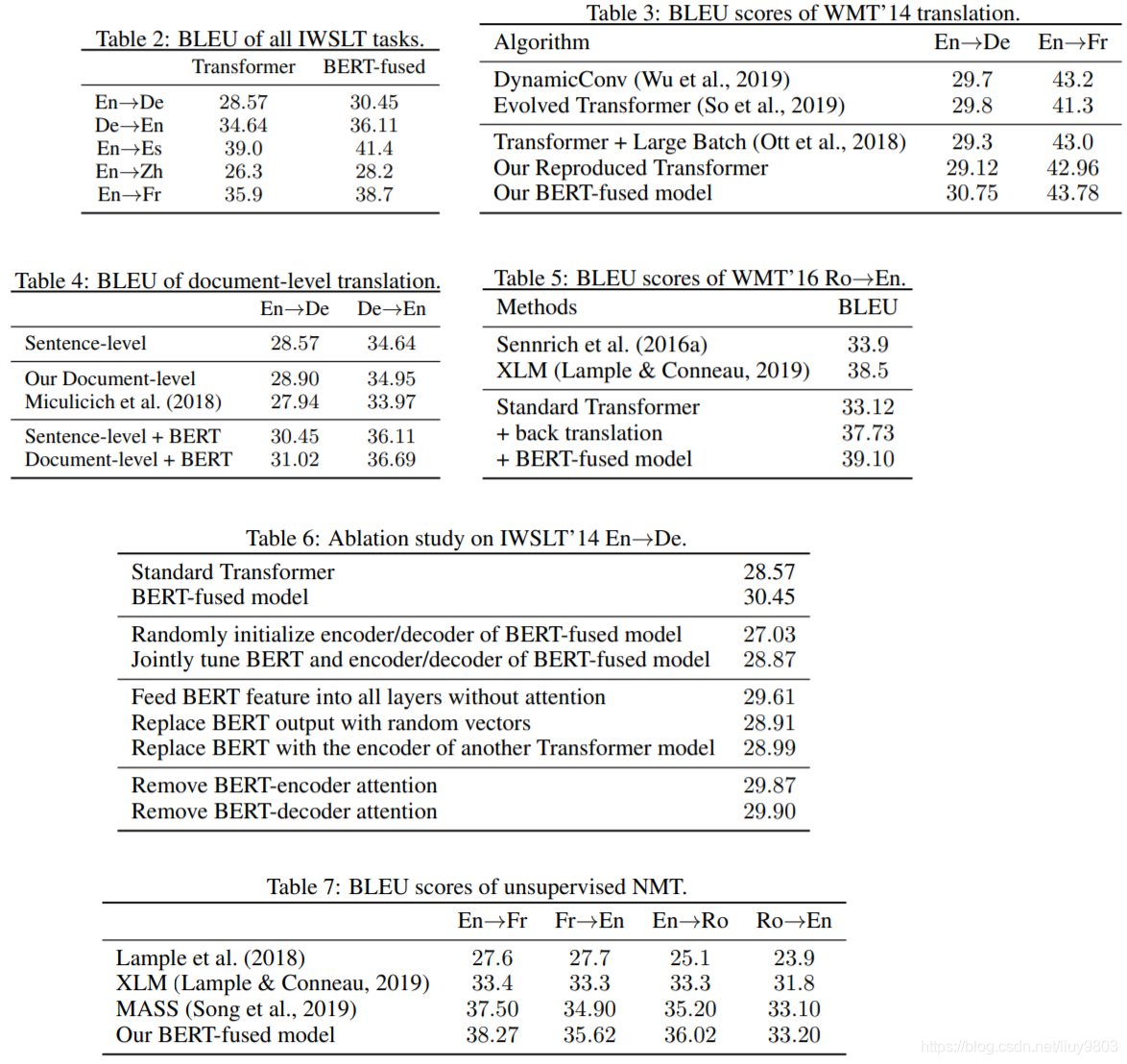
消融实验
(1)随机初始化BERT-fused 模型的NMT模块(即编码器和解码器),而不使用warm-start,只能取得27.03的BLEU分。比baseline还低。联合训练NMT模块和BERT模型。虽然可以将分数从28.57提高到28.87,但是比固定参数的BERT的分数30.45低。
(2)不使用注意力模型,将BERT的输出喂到encoder的所有层,即:
![]()
此时BERT和encoder共享同一个 vocabulary,BLEU得分为29.61,比标准Transformer略好但比使用BERT输出作为embedding的结果差。这表明BERT的输出不能直接被融合到每一层,使用注意力模型的效果更好。
(3)分别去掉encoder、decoder中的 ,BLEU 分数从30.45 下降到29.87、29.90。
(4)尝试2层encoder堆叠、集成学习模型或者更深层的NMT模型,效果都没有作者的模型好。
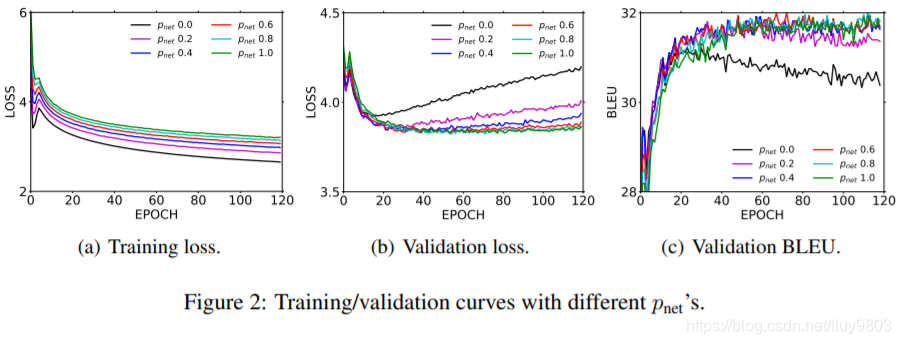
(5)尽管较大的 导致了稍大的训练损失,但会产生较小的验证损失以及更高的BLEU得分。这表明 drop-net 技巧的确可以提高模型的泛化能力,因此将
固定为1.0。
这篇关于论文阅读——INCORPORATING BERT INTO NEURAL MACHINE TRANSLATION的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)