本文主要是介绍【论文阅读】AUDITOR: A System Designed for Automatic Discovery of Complex Integrity Constraints in Relatio,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AUDITOR: A System Designed for Automatic Discovery of Complex Integrity Constraints in Relational Databases
摘要
在这个演示中,我们提出了一个新的完整性约束的定义,它对异常数据发现更强大。在我们的定义中,约束作用于关系表中的类别属性和数值属性,以及它们的派生属性,从而导致巨大的搜索空间。此外,我们是第一个将属性值分布作为约束的一部分考虑进去的。基于提出的完整性约束,我们在医疗保健审计行业的关系表上构建了AUDITOR,并演示了其有效性和易用性,以便领域专家发现异常数据。
一、介绍
对于关系数据库,复杂的完整性约束是对数据库中部分元组实施的约束。复杂完整性约束与标准约束有两个不同之处:
1.复杂的完整性约束适用于大多数元组,而不是所有元组,而标准的完整性约束通常适用于所有元组
2.对于复杂的完整性约束这些违规行为将提交一名审计员,以核实它们是否属于异常行为。另一方面,违反标准完整性约束的情况会被数据库拒绝,而无需人工检查。
我们对复杂完整性约束的自动发现的研究是基于这样一个事实:复杂约束发现在医疗保健审计行业中非常有用。例如,假设有一个医疗保险报销数据库,其中大多数报销元组是正常的,很少有报销是异常的(即故意为通过标准数据库约束而产生的偿付,但实质上是非法的),我们的研究可以帮助财务审计师发现一个有效的范围复杂完整性约束,指定了一个报销率范围,大多数报销元遵循。因此,审核员可以验证违反这种有效范围约束的报销元组。此外,如果这些报销元组恰好是异常的,审核员将执行进一步的措施(例如,数据更正或拒绝)。
尽管从数据库中发现约束已经付出了大量的努力,但它们都不能直接用于发现复杂的完整性约束,因为现有的工作要么集中在分类属性[2,4,5],要么集中在数字属性[1]。也有许多作品通过有趣的聚合模式来处理数据探索[3,8]。
本文演示了我们为自动发现复杂完整性约束而构建的系统AUDITOR。我们的系统发现的复杂的完整性约束展示了以下来自以前工作的特性 [1,2,4,5, 7]:
- 属性类型: 同时对分类属性和数字属性使用AUDITOR函数,以便捕获同一表中所有属性之间的复杂关系。
- 属性推导: AUDITOR允许探索从原始表中的现有属性派生的新属性。具体来说,数值属性可以通过{+、−、×、/}等代数运算符生成新的属性。该特性显著扩展了搜索空间,以查找隐藏在派生属性中的约束.
- 属性值分布: AUDITOR是第一个利用属性值分布作为约束的一部分的。这是因为,年龄、身高、分数、价格等真实属性普遍存在正态分布。违反正态分布可能是异常数据发现的线索。
在下文中,我们使用表1作为示例,并解释AUDITOR将发现的复杂ic。该表包含患者的性别、婚姻状况、家庭关系、科室等信息。此外,我们有每个病人的总费用和支付数据。这些属性名称的缩写也显示在表中,并将在我们的约束表示中使用。最后一列中的Pay/TC(医疗保险报销比率)是原始表中不存在的派生属性。
下面是前面方法发现的分类属性的IC示例[4,6,9]:
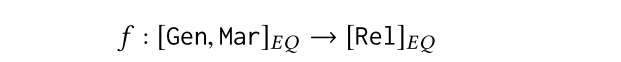
这意味着两个具有相同性别和婚姻状况(即[Gen,Mar]EQ)的患者元组应该具有相同的家庭关系(即[Rel]EQ)。例如,病人1和病人3都是已婚女性。他们的家庭关系应该是夫妻关系。违反此约束的元组被认为是异常的。相反,我们定义的约束更复杂,它能够捕获分类属性和数字属性之间的关系。例如,对特定类型的部门有一个合理的健康索赔比例范围。索赔比率在表1中不显式存在,但是可以从属性Pay和TC派生出来。这样,我们的约束作用于Dep属性和pay /TC。这些约束的例子如下所示:
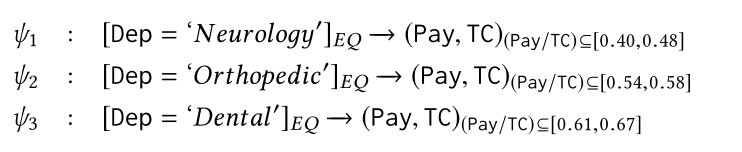
如图1所示,我们的算法对不同部门的pay / tc的正常范围进行了初始化,然后可以由领域专家进行重定义。通过以上审计发现的约束条件,我们可以将患者t10检测为异常元组,因为她的pay / tc值不在合理范围内。
二、系统概述
在本节中,我们将介绍AUDITOR的工作流程,如图2所示,并明确解释复杂约束发现和异常数据检测的过程。AUDITOR需要两个输入参数领域专家提出的ϵ和β,来区分正常数据和异常元组。
ϵ是支持阈值,确定匹配复杂完整性约束(CICs)的关系表中元组的最小数量。β是调节合法分布范围的参数。以a为平均值和σ为标准差,我们将范围[a−β×σ,a+β×σ]之外的值定义为异常值。通过切比雪夫不等式,证明了无论该值遵循哪种分布,至少有1 - 1/(β)2比例的值落在这个范围内。例如,β= 3意味着任何分布的至少89%的值都在选定的值范围内。在参数初始化中,我们设置β=3,并逐渐降低支持阈值,直到CICs出现。这两个参数可以通过领域专家获得。给定两个初始化的参数和一个输入关系表,AUDITOR从构造搜索空间开始,包括属性派生和属性组合。前者使用代数运算符{+,−,×,/},以便发现隐藏属性(例如,Pay/TC)这可以作为复杂约束的条件。后者考虑分类属性和数字属性之间的所有可能组合,从而为AUDITOR提供了巨大的搜索空间。对于传统的ic,找到有用的模式[4]是np难的。由于我们进一步允许属性派生,可能的属性的数量是从m + n到 2n2−n + m,其中m和n分别为原始关系表中类别属性和数字属性的数量。
为了解决效率问题,我们提出了一种冗余剪枝和支持剪枝的剪枝框架。
首先,我们利用统计上重要的CICs必须超过给定的阈值δ和设计最小支持的要求,来修剪小于δ的属性组合的超集。其次,如果两个CICs包含相同的元组,那么它们检测到的异常数据的结果也是相同的,所以我们只需要计算其中一个CICs就可以解决异常数据检测问题。这两种剪枝技术的细节将在第2.1节中介绍。
对于每个未被修剪的候选属性集,我们的最后一步是确定数值属性中正态数据分布的范围。例如,当属性集为{Dep,Pay/TC}时,我们需要为Department的每个类别确定Pay/TC的法定间隔。如果β设置为3,它意味着正常的数据将位于[a-3×σ, a+3×σ]对于Dep等于‘Neurology”,‘Orthopedic’和‘Dental’合法范围是[0.40, 0.48], [0.54, 0.58], [0.61, 0.67]。
最后,我们扫描数据库以识别违反生成的复杂约束的元组。这些元组在图形用户界面(GUI)中显示,供领域专家进一步验证。接下来,我们将提供更多关于搜索空间剪枝和异常数据检测的细节。
2.1搜索空间修剪
搜索空间由所有可能的属性组合组成,对于CIC构造来说,枚举这些属性组合是不可行的。在这一部分中,我们提出了冗余剪枝和支持剪枝两种剪枝策略,以大大减少搜索空间。
2.2异常数据检测
CIC发现的最终目标是识别异常元组并将它们传递给领域专家进行可视化。
3. 示范概述
在本节中,我们将演示如图4所示的AUDITOR用户界面,并介绍自动发现CICs和异常数据检测的过程。AUDITOR是为审计领域的专家设计的,但缺乏数据库管理方面的知识。用于演示的数据集包含来自真实世界数据集的几个示例,包括来自UCI机器学习存储库的威斯康星州乳腺癌(WBC),以及来自商业公司的匿名私有数据集。
要使用AUDITOR,第一步是从提供的表列表中指定一个关系表,并在data Selection面板中选择感兴趣的属性。如果用户没有选择任何属性,我们将使用表的所有属性来进行CIC发现。支持阈值δ和分布参数β可通过滑动杆进行调节。δ值越高,满足CICs的元组越多,CICs的泛化能力越强,β值越大,越有可能违反异常数据。通过单击提交按钮,后端算法开始生成违反所发现约束的CICs和元组。
输出显示在输出面板中。每条记录代表一个中投公司及其特点。用户可以通过快速点击绿色箭头来对约束进行排序识别数据库中大多数元组所违反的CICs。此外,他们可以单击这个数字来查找违规元组的更多细节。在违规的细节中,它显示了所有违反至少一个已发现CIC的元组。每个元组中违反约束的属性也用红色突出显示。在InCheckcolumn中,专家确认异常数据并单击标记按钮收集这些异常元组进行后处理。
最后,我们报告审计员发现CICs和识别违反约束的元组的运行时间。结果汇总于表2。我们可以看到,在757,818元组的医疗账单中,最坏情况运行时间为465.17 (s)。同时,随着数值属性数量的增加,会发现更多隐藏的CICs,运行时间也会相应增加。
这篇关于【论文阅读】AUDITOR: A System Designed for Automatic Discovery of Complex Integrity Constraints in Relatio的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









