本文主要是介绍Hyperion 创建使用其他维度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于自学epm的同学应该很难创建dimension,更难理解维度的属性。下面我将自己亲身实践创建维度的方法交给大家。
目录
1、导出应用程序维度。
2、导入维度到应用程序。
3、使用eas创建维度。
3.1使用文件和规则文件创建维度。
3.2使用sql和规则文件创建维度。
4、如何根据维度添加数据
5、如何使用自动脚本备份维度。
1、导出应用程序维度。
1.1首先你得有访问其他plan的应用,在工具栏中,单击导航->应用程序->刷新。现在,您应该在Planning下看到新创建的应用程序,点击对应的程序。
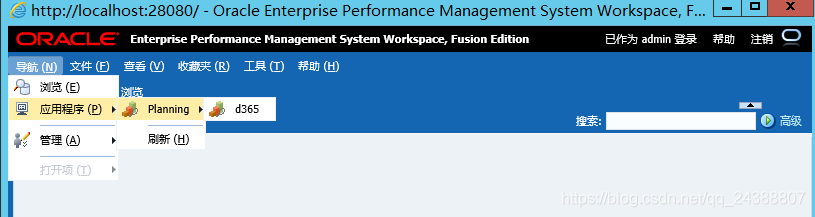
1.2、在打开plan的面板,在工具栏中,点击管理->导入和导出->将元数据导出到文件。
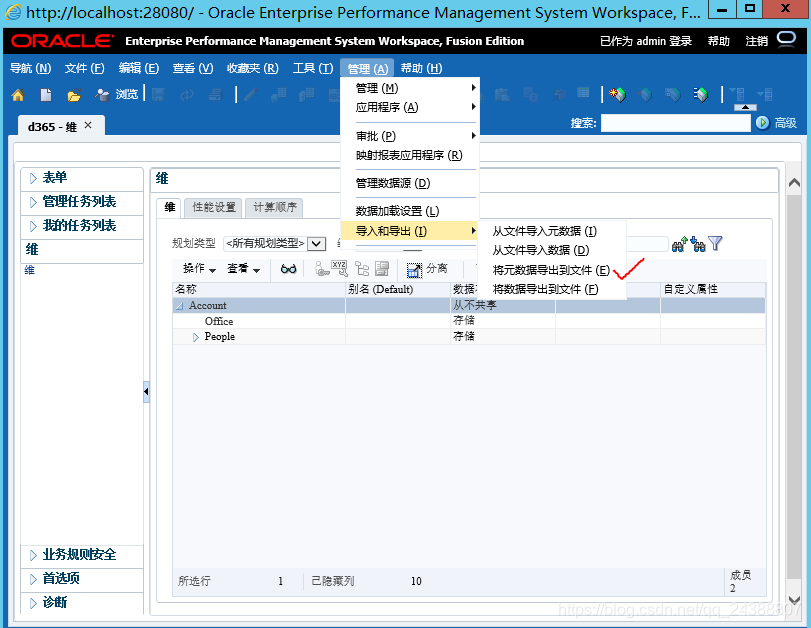
1.3、在“维度”下拉菜单中,选择第一个Account维度,然后单击“运行”。现在将开始导出。将这些CSV保存在本地计算机上,然后打开导出文件,以确保所有内容均正确导出。依次重复上面步骤导出各个维度。
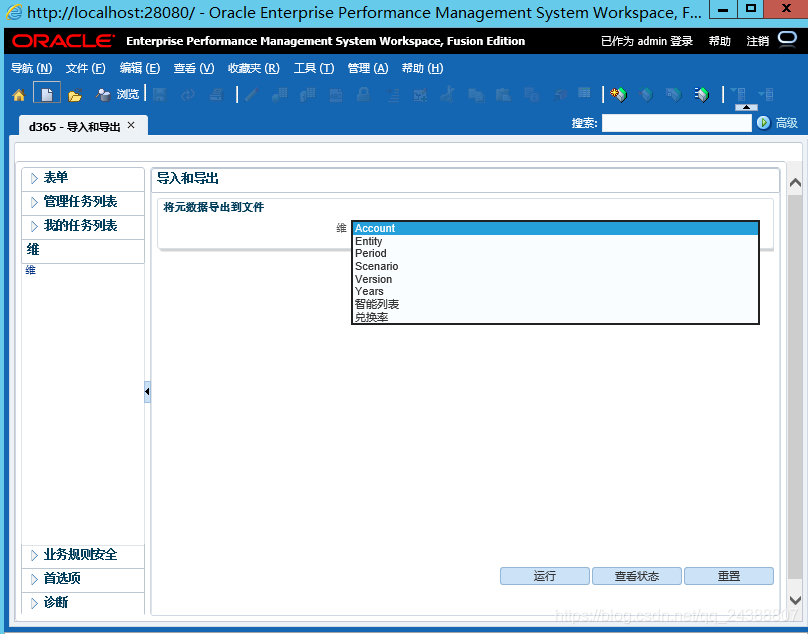
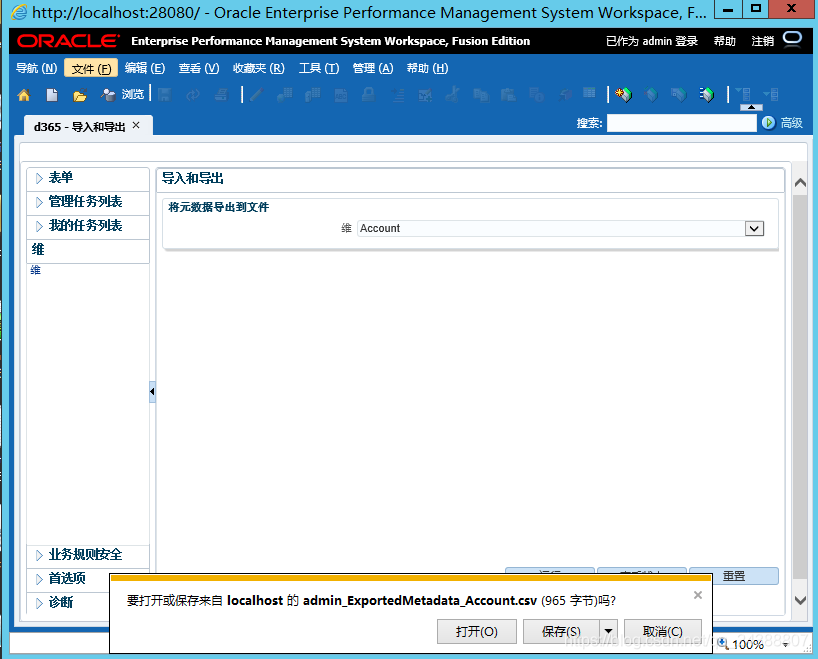
此时我们拿到自己的维度框架。打开如下


对于第一行标题自己个人的见解,
A列一般是维度名称。
C,D列一般是别名表的名称。(如果有多个别名表会继续增加)
V列是源列的类型,这里类型就是你创建plan时候的类型。plan1,plan2,plan3名字自定义的。
WXYZ,plan type(plan1),aggregation (plan1),data storage (plan1), formula (Plan1) 对应的第一个类型的名称以及属性。对一个类型列就到Z。但是如果维度是对于三个那么AA,AB,AC,AD这四个对应WXYZ这四列,除了规划类型名称得改变。
所以在自己创建的维度基础上知道这些,就可以使用别的plan的维度进行调整,然后导入到自己的维度中。导入前使用txt格式查看一下维度分隔符是什么有的是,有的是分隔符。
2、导入维度到应用程序。
2.1、在打开plan的面板,在工具栏中,点击管理->导入和导出->将元数据导出到文件。
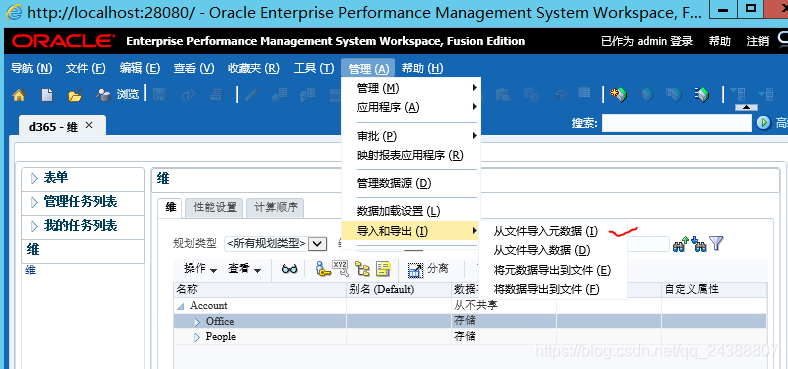
2.2、选择对应的维度和维度文件。

2.3、先点击验证,如果驳回为0,点击运行即可。
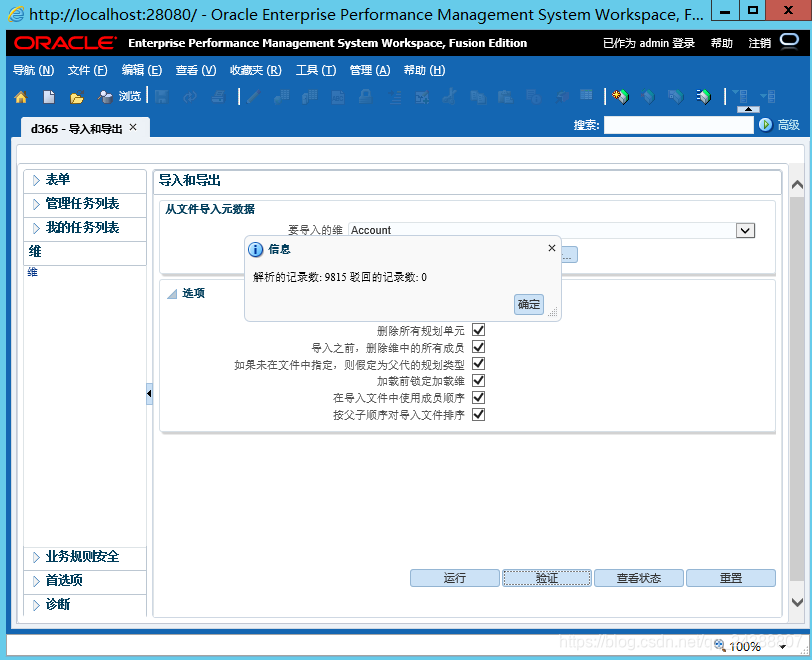
 运行之后数据都被驳回,错误消息如下
运行之后数据都被驳回,错误消息如下
The loading of members into a Hyperion Planning application using Outline Load Utility results in error:
java.lang.RuntimeException: Fetch of saved member "<MEMBER NAME>" failed.
所以我们查了sr
具体处理如下,点击管理/应用程序/属性,
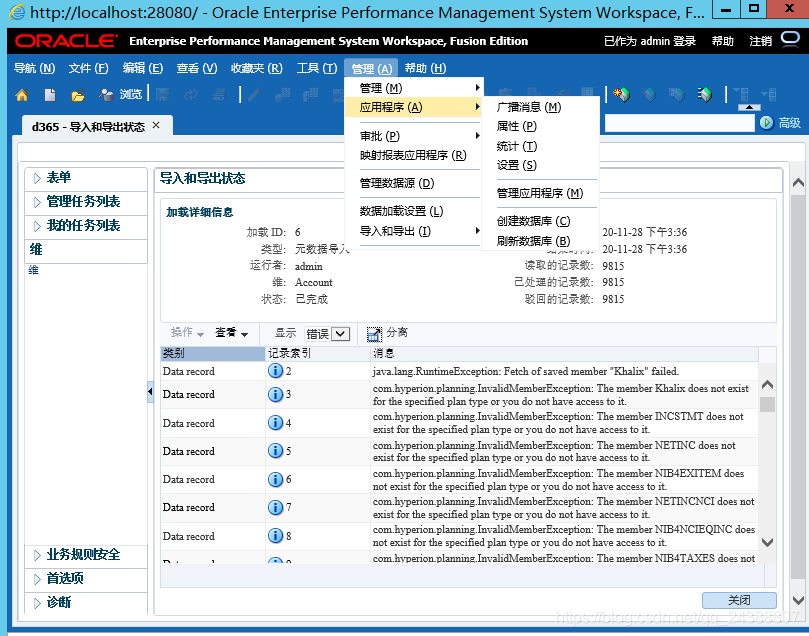
把EDIT_DIM_ENABLED属性由false改为true。保存。
然后重启服务,执行导入。出现如下界面说明执行成功。
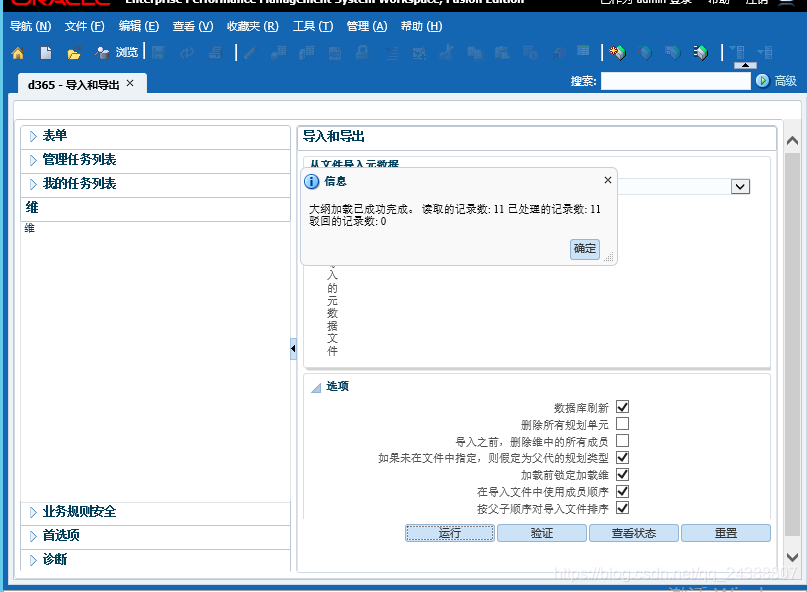
3、导入数据。
Essbase建维与数据导入实例 - 百度文库
3.1使用文件和规则文件创建维度。
3.2使用sql和规则文件创建维度。
3.3使用ODI导入数据。
4、如何根据维度添加数据
5、如何使用自动脚本备份维度。
--obiee
角色
公司_主题_各个数据控制。--控制数据的角色 gf_d365_data_control_sales. gf_d365_data_control_region.
公司_主题_各个主题角色。--继承对应的数据控制角色。gf_d365_delivery. gf_d365_delivery_sa. gf_d365_sales. gf_d365_sales_sa.
FOL_主题_各个主题角色。--对应的文件夹 fol_主题区域_admin ,可以查看所有的和编辑所有的,
使用角色交叉,可以让用户编辑报表,但是因为没有文件夹权限,只能保存在自己的文件。在前台管理界面对对应的主题区域分配对应的角色即可。
这篇关于Hyperion 创建使用其他维度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








