本文主要是介绍100天大数据零基础入门到就业------第二天:python基础与数据类型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、python注释
1.注释的作用
让自己和别人能看懂,免得挨打
2.注释的基本语法
单行注释:以"#"(Shift + 3)号开头,只能注释一行内容
例一:
# 输出Hello World字符串 print('Hello World')例二:
print('Hello World') # 输出Hello World字符串多行注释:可以同时注释多行代码或程序,常用于代码块的注释
"""
注释内容
第一行
第二行
第三行
"""例三:
""" Hi, 大家好 从今天开始,我们将一起学习Python这门语言 """''' Hi, 大家好 从今天开始,我们将一起学习Python这门语言 ''' print('Hi, 大家好') print('从今天开始,我们将一起学习Python这门语言')
二.PyCharm常用快捷键
1.代码提示
在PyCharm中,当我们输入Python关键字中的前2~3个字符,其会自动进行代码提示。这个时候,我们只需要按回车即可以快速的输入某个内容。
2.代码保存
编写代码时,一定要养成一个好的习惯,使用
Ctrl + S快速对代码进行保存操作。个人建议,当写完一行代码时,就按一次
3.撤销与恢复
如果不小心删除了某行代码,这个时候我们可以快速按
Ctrl + Z就可以快速进行恢复。每按一次就撤销一次,如果撤销多了,怎么办?答:还可以通过
Ctrl + Y进行恢复操作
三.python中的变量
1.变量的概念
① 变量是存储数据的容器
② 变量在程序运行过程中是可以发生改变的量
③ 变量存储的数据是临时的
变量严格意义算名字标签
2.变量的定义
变量名称 = 变量的值
注:等号的两边都要保留一个空格,其实Python中建议符号的两边尽量都要保留一个空格说明:在Python程序中,这个等号和日常生活中的等号不太一样,其有一个专业名词:赋值运算符,其读法:要从右向左读,把变量的值通过 = 赋值给左边的变量。
3.变量的命名规则
① 由数字、字母、下划线(_)组成
② 不能数字开头
③ 严格区分⼤小写
④ 不能使⽤内置关键字作为变量名称
4.推荐的命名规则
① 变量命名一定要做到见名知义。
② 大驼峰:即每个单词首字母都大写,例如: MyName 。
③ 小驼峰:第二个(含)以后的单词首字母大写,例如: myName 。
④ 下划线:例如: my_name。
四.变量中的数据类型
1.七种数值类型
不可变数据类型:Number(数字) String(字符串)Tuple(元组)
可变数据类型: List(列表) Dictionary(字典) Set(集合)
布尔类型 :bool (true,false)
2.number(数字)
int(整数型) :通常被称为整型或整数,是正整数或负整数
float(浮点数) :浮点型有整数部分与小数组成
complex(复数):复数有实数部分和虚数部分构成,可以用a+bj或complex(a,b)表示,复 数的实部A和虚部B都是浮点型
数字类型转换
int(x):将x转换为一个整数
float(x):将x转换成一个浮点数
complex(x):将x转换到一个复数,实数部分为x,虚数部分为0
complex(x,y):将x y 转换到一个复数,实数部分为x,虚数部分为y
len(密码) 求密码长度
3.string(字符串)
a. python中字符串用单引号”或双引号“括起来,同时用反斜杠\转义特殊字符
str1 = 'abcdefg'
str2 = "hello world"print(type(str1)) # <class 'str'>
print(type(str2)) # <class 'str'>#三引号形式的字符串支持换行操作
name1 = '''I am Tom, Nice to meet you!'''
print(name1)
print(type(name1))print('-' * 20)name2 = """I am Jennify,Nice to meet you!"""
print(name2)
print(type(name2))b.常见字符串运算符
| 操作符 | 描述 | 实例 |
| + | 字符串连接 | a+b输出结果:ab |
| * | 重复输出字符串 | a*2输出结果:aa |
| [] | 通过索引获取字符串中字符 | a='hello',,a[1]输出结果:e |
| [:] | 截取字符段 | a[1:4]输出结果:ell |
| in | 成员运算符包含给定字符返回true | |
| not in | 成员运算符不包含给定字符返回true |
c.字符串输入输出
#在python中我们可以用input()方法来接收用户信息
name = input('请输入您的姓名:')
age = input('请输入您的年龄:')
address = input('请输入您的住址:')
#普通输出
print(name, age, address)
#格式化输出
print(f'我的名字是{name},今年{age}岁了,家里住在{address}...')d.字符串的索引下标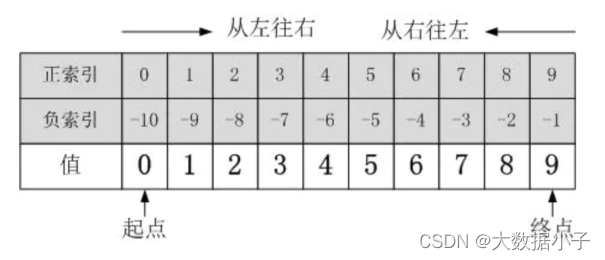
口诀: 正索引从左往右查,负索引从右往左查
numstr = '0123456789'
# 1、从2到5开始切片,步长为1
print(numstr[2:5:1])
print(numstr[2:5])
# 2、只有结尾的字符串切片:代表从索引为0开始,截取到索引为5的位置(不包含索引为5的数据)
print(numstr[:5])
# 3、只有开头的字符串切片:代表从起始位置开始,已知截取到字符串的结尾
print(numstr[1:])
# 4、获取或拷贝整个字符串
print(numstr[:])
# 5、调整步阶:类似求偶数
print(numstr[::2])
# 6、把步阶设置为负整数:类似字符串翻转
print(numstr[::-1])
# 7、起始位置与结束位置都是负数
print(numstr[-4:-1])
# 8、结束字符为负数,如截取012345678
print(numstr[:-1])e.字符串的查操作
| 函数 | ||
| find() | 检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则返回-1。 | |
| index() | 检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则报异常 | |
| rfind() | 和find()功能相同,但查找方向为右侧开始。 | |
| rindex() | 和index()功能相同,但查找方向为右侧开始 | |
| count() | 返回某个子串在字符串中出现的次数 |
str1 = 'hello world . hello linux hello python'# 查找linux子串是否出现在字符串中
print(str1.find('linux')) #20# 在str1中查找不存在的子串
print(str1.find('and')) #-1# 获取点号的索引下标
print(str1.find('.')) #12print(str1.index('linux')) #20#字符串.count('子串', 开始位置下标, 结束位置下标)
print(str1.count('hello')) #3
print(str1.count('hello',0,15)) #1#不存在会报错
print(str1.index('pineapple'))filename = '20210310axvu.avatar.png'
# 求出点号在字符串中最后一次出现的位置
print(filename.rfind('.'))
print(filename.rindex('.'))#r = right,代表从右开始查找
#字符串序列.rfind(子串)
#字符串序列.rindex(子串)
#rfind()方法和rindex()方法语法上完全一致,唯一的区别就是对子串没有出现在字符串的中的情况,#rfind()返回-1,rindex()返回错误。
f.字符串的改操作
| 函数 | 作用 |
| replace() | 字符串.replace(要替换的内容, 替换后的内容, 替换的次数-可以省略) |
| split() | 返回切割后的列表序列 |
| capitalize() | 首字母大写 |
| title() | 所有单词首字母大写 |
| upper()与lower() | 返回全部大写或小写的字符串 |
| lstrip()、rstrip()与strip() | 去除左边、右边以及两边的空白字符 |
| ljust()、rjust()与center() | 返回原字符串左对齐、右对齐以及居中对齐 |
str1 = 'hello linux and hello linux'
# 把字符串中所有linux字符替换为python
print(str1.replace('linux', 'python'))
# 把字符串中的第一个linux进行替换为python
print(str1.replace('linux', 'python', 1))
# 把and字符串替换为&&
print(str1.replace('and', '&&'))# split()方法
str2 = 'apple-banana-orange'
print(str1.split('-'))#join()方法
list1 = ['apple', 'banana', 'orange']
print('-'.join(list1))#capitalize() 方法
str3 = 'myName'
# 把str1变成首字母大写字符串
print(str1.capitalize())# title()方法
str4 = 'student_manager'
# 把str2变成大驼峰
print(str2.title().replace('_', ''))#lstrip()、rstrip()与strip()
# 用户名验证案例
username = input('请输入您的账号:')
# 去除username两边的空白字符
print(len(username))
print(username.strip())
print(len(username.strip()))#ljust()、rjust()、center()
#字符串序列.ljust(长度, 填充字符)
str1 = 'python'
# 左对齐
print(str1.ljust(10, '.'))
# 右对齐
print(str1.rjust(10, '#'))
# 居中对齐
print(str1.center(10, '@'))g.字符串的判断方法
| 函数 | 作用 |
| startswith() | 检查字符串是否是以指定子串开头,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查 |
| endswith() | 检查字符串是否是以指定子串结尾,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查 |
| isalpha() | 如果字符串所有字符(至少有一个字符)都是字母则返回 True, 否则返回 False。 |
| isdigit() | 如果字符串只包含数字则返回 True 否则返回 False。 |
| isalnum() | Python isalnum() 方法检测字符串是否由字母和数字组成。如果字符串所有字符(至少有一个字符)都是字母或数字则返 回 True,否则返回 False。 |
| isspace() | 如果字符串中只包含空白,则返回 True,否则返回 False |
#startswith()方法
str1 = 'python program'
print(str1.startswith('python'))# endswith()方法
str2 = 'avatar.png'
print(str2.endswith('.png'))#isalpha()方法
str1 = 'admin'
str2 = 'admin123'
print(str1.isalpha()) # True
print(str2.isalpha()) # False#isdigit()方法
password = input('请输入您的银行卡密码:')if len(password) == 6 and password.isdigit():print('输入密码成功,正在验证...')
else:print('密码输入错误,请重新输入')#isalnum()方法
username = input('请输入的您的用户名(只能为字母+数字形式):')if username.isalnum():print('合理的用户名,正在录入系统...')
else:print('输入的用户名有误,请重新输入...')#isspace()方法
str1 = ' ' # 最少要包含一个空白字符
print(str1.isspace())username = input('请输入的您的用户名:')
if len(username) == 0 or username.isspace():print('您没有输入任何字符...')
else:print(f'您的输入的字符{username}') 4.元组的定义与使用
a.什么时候需要元组
答:存储多个数据且数据是不能修改的
b.元组的定义
元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
tuple1 = (10, 20, 30)
tuple2 = (10,)#单个数据,数据后面要添加逗号
c.元组的查操作
| 函数 | 作用 |
| 元组[索引] | 根据==索引下标==查找元素 |
| index() | 查找某个数据,如果数据存在返回对应的下标,否则报错,语法和列表、字符串的index方法相同 |
| count() | 统计某个数据在当前元组出现的次数 |
| len() | 统计元组中数据的个数 |
nums = (10, 20, 30, 50, 30)print(nums[2])print(nums.index(20))print(nums.count(30))print(len(nums))5. 列表(list)
a.列表的定义
列表序列名称 = [列表中的元素1, 列表中的元素2, 列表中的元素3, ...]
b.列表的查操作
| 函数 | 作用 |
| index() | 指定数据所在位置的下标 |
| count() | 统计指定数据在当前列表中出现的次数 |
| in() | 判断指定数据在某个列表序列,如果在返回True,否则返回False |
| not in() | 判断指定数据不在某个列表序列,如果不在返回True,否则返回False |
# 1、查找某个元素在列表中出现的位置(索引下标)
list1 = ['apple', 'banana', 'pineapple']
print(list1.index('apple')) # 0
# print(list1.index('peach')) # 报错# 2、count()方法:统计元素在列表中出现的次数
list2 = ['刘备', '关羽', '张飞', '关羽', '赵云']
# 统计一下关羽这个元素在列表中出现的次数
print(list2.count('关羽'))# 3、in方法和not in方法(黑名单系统)
list3 = ['192.168.1.15', '10.1.1.100', '172.35.46.128']
if '10.1.1.100' in list3:print('黑名单IP,禁止访问')
else:print('正常IP,访问站点信息')c.列表的增操作
| 函数 | 作用 |
| append() | 增加指定数据到列表中 |
| exend() | 列表结尾追加数据,如果数据是一个序列,则将这个序列的数据逐一添加到列表 |
| insert() | 指定位置新增数据 |
#append()方法
names = ['孙悟空', '唐僧', '猪八戒']
# 在列表的尾部追加一个元素"沙僧"
print(names.append('沙僧'))#extend()方法
list1 = ['Tom', 'Rose', 'Jack']
list2 = ['Hack', 'Jennify']
print(list1.extend(list2))#insert()方法
names = ['薛宝钗', '林黛玉']
# 在薛宝钗和林黛玉之间,插入一个新元素"贾宝玉"
print(names.insert(1, '贾宝玉'))d.列表删操作
| 函数 | 作用 |
| del列表[索引] | 删除列表中的某个元素 |
| pop() | 删除指定下标的数据(默认为最后一个),并返回该数据 |
| remove() | 移除列表中某个数据的第一个匹配项。 |
| clear() | 清空列表,删除列表中的所有元素,返回空列表。 |
#del删除指定的列表元素
names = ['Tom', 'Rose', 'Jack', 'Jennify']
# 删除Rose
del names[1]
# 打印列表
print(names)#pop()方法 默认删除最后一个
names = ['貂蝉', '吕布', '董卓']
del_name = names.pop()#remove()方法
fruit = ['apple', 'banana', 'pineapple']
fruit.remove('banana')
print(fruit)# clear()方法
names = ['貂蝉', '吕布', '董卓']
# 随着故事的发展,人物都game over
names.clear()
# 打印列表
print(names)e.列表的改操作
| 函数 | 作用 |
| 列表[索引]=修改后的值 | 修改列表某个元素 |
| reverse() | 将数据序列进行倒叙排列 |
| sort() | 对列表序列进行排序 |
| copy() | 对列表序列进行拷贝 |
list1 = ['貂蝉', '大乔', '小乔', '八戒']
# 修改列表中的元素
list1[3] = '周瑜'
print(list1)list2 = [1, 2, 3, 4, 5, 6]
list2.reverse()
print(list2)list3 = [10, 50, 20, 30, 1]
list3.sort() # 升序(从小到大)
# 或
# list3.sort(reverse=True) # 降序(从大到小)
print(list3)list4 = list3.copy()
print(list4)5.字典(dictionary)
a.什么时候使用字典
在日常生活中,姓名、年龄以及性别同属于一个人的基本特征。但是如果使用列表对其进行存储,则分散为3个元素,这显然不合逻辑。我们有没有办法,将其保存在同一个元素中,姓名、年龄以及性别都作为这个元素的3个属性,这时只能使用字典。
b.字典的定义
有数据字典:dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}
空字典: dict2 = {}
c.字典的增操作
#字典名称[key] = value
# 1、定义一个空字典
person = {}
# 2、向字典中添加数据
person['name'] = '刘备'
person['age'] = 40
person['address'] = '蜀中'
# 3、使用print方法打印person字典
print(person)d.字典的删操作
| 函数 | 作用 |
| del 字典名称[key] | 删除指定元素 |
| clear() | 清空字典中的所有key |
# 1、定义一个有数据的字典
person = {'name':'王大锤', 'age':28, 'gender':'male', 'address':'北京市海淀区'}
# 2、删除字典中的某个元素(如gender)
del person['gender']
# 3、打印字典
print(person)# 1、定义一个有数据的字典
person = {'name':'王大锤', 'age':28, 'gender':'male', 'address':'北京市海淀区'}
# 2、使用clear()方法清空字典
person.clear()
# 3、打印字典
print(person)e.字典的改操作
字典名称[key] = value
注:如果key存在则修改这个key对应的值;如果key不存在则新增此键值对。
# 1、定义字典
person = {'name':'孙悟空', 'age': 600, 'address':'花果山'}
# 2、修改字典中的数据(address)
person['address'] = '东土大唐'
# 3、打印字典
print(person)f.字典的查操作
查询方法:使用具体的某个key查询数据,如果未找到,则直接报错。
字典序列[key]
| 函数 | 作用 |
| get(key, 默认值) | 根据字典的key获取对应的value值,如果当前查找的key不存在则返回第二个参数(默认值),如果省略第二个参数,则返回None |
| keys() | 以列表返回一个字典的所有键 |
| values() | 以列表返回一个字典的所有值 |
| items() | 以列表返回可遍历的(键, 值) 元组数组 |
# 1、定义一个字典
cat = {'name':'Tom', 'age':5, 'address':'美国纽约'}
# 2、获取字典的相关信息
name = cat.get('name')
age = cat.get('age')
gender = cat.get('gender', 'male') # get(key, 默认值)
address = cat.get('address')
print(f'姓名:{name},年龄:{age},性别:{gender},住址:{address}')# 1、定义一个字典
person = {'name':'貂蝉', 'age':18, 'mobile':'13765022249'}
# 2、提取字典中的name、age以及mobile属性
print(person.keys())# 1、定义一个字典
person = {'name':'貂蝉', 'age':18, 'mobile':'13765022249'}
# 2、提取字典中的貂蝉、18以及13765022249号码
print(person.values())# 1、定义一个字典
person = {'name':'貂蝉', 'age':18, 'mobile':'13765022249'}
# 2、调用items方法获取数据,dict_items([('name', '貂蝉'), ('age', 18), ('mobile', '13765022249')])
# print(person.items())
# 3、结合for循环对字典中的数据进行遍历
for key, value in person.items():print(f'{key}:{value}')6.集合(set)
a.集合的定义
集合(set)是一个无序的不重复元素序列。天生去重,无序
s1 = {10, 20, 30, 40, 50}
s3 = {}
b.集合的增操作
| 函数 | 作用 |
| add() | 向集合中增加一个元素(单一) |
| update() | 向集合中增加序列类型的数据(字符串、列表、元组、字典) 添加字符串 时会散开,添加字典时只有key键 |
students = set()
students.add('李哲')
students.add('刘毅')
print(students)students = set()
list1 = ['刘备', '关羽', '赵云']
students.update(list1)
print(students)students = set()
students.add('刘德华')
students.add('黎明')
# 使用update新增元素
students.update('蔡徐坤')
print(student)
# students = {'刘德华', '黎明', '蔡', '徐', '坤'}
dict1={'key':'zhang'}
students.update(dict1)
print(students)
#{'蔡', '刘德华', '坤', 'key', '黎明', '徐'}c.集合的查操作
| 函数 | 作用 |
| in | 判断某个元素是否在集合中,如果在,则返回True,否则返回False |
| not in | 判断某个元素不在集合中,如果不在,则返回True,否则返回False |
# 定义一个set集合
s1 = {'刘帅', '英标', '高源'}
# 判断刘帅是否在s1集合中
if '刘帅' in s1:print('刘帅在s1集合中')
else:print('刘帅没有出现在s1集合中')d.集合的交集、并集与差集特性
s1 = {'刘备', '关羽', '张飞', '貂蝉'}
s2 = {'袁绍', '吕布', '曹操', '貂蝉'}使用
&来求两个集合的交集:print(s1 & s2)使用
|来求两个集合的并集:print(s1 | s2)使用
-来求两个集合的差集:print(s1 - s2)
7.各数据类型转换
| eval(str) | 把字符串转换为原数据类型 |
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将对象 x 转换为字符串 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| complex(x,y) | 将x y 转换到一个复数,实数部分为x,虚数部分为y |
这篇关于100天大数据零基础入门到就业------第二天:python基础与数据类型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






