本文主要是介绍【提前过年吧】来对对联吧,基于transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于Transformer实现对联下联自动生成
- 更新日期:2022.11.22
1.项目背景
对联又称对偶、门对、春贴、春联、对子、桃符、楹联(因古时多悬挂于楼堂宅殿的楹柱而得名)等,是一种对偶文学,一说起源于桃符。另一来源是春贴,古人在立春日多贴“宜春”二字,后渐渐发展为春联,表达了中国劳动人民一种辟邪除灾、迎祥纳福的美好愿望。对联是写在纸、布上或刻在竹子、木头、柱子上的对偶语句。言简意深,对仗工整,平仄协调,字数相同,结构相同,是中文语言的独特的艺术形式。
该项目基于transformer模型训练了一个自动对下联模型,也就是你给出上联,该模型可以对出下联。实际效果如下:
上联: <start>腾飞上铁,锐意改革谋发展,勇当千里马<end>
真实的下联: <start>和谐南供,安全送电保畅通,争做领头羊<end>
预测的下联: <start> 发 展 开 花 , 和 谐 发 展 创 和 谐 , 更 上 一 层 楼 <end>上联: <start>风弦未拨心先乱<end>
真实的下联: <start>夜幕已沉梦更闲<end>
预测的下联: <start> 月 影 犹 怜 梦 已 空 <end>
下面来看下实现该模型的全流程吧qwq
2.环境设置
我们需要的依赖主要有:
- paddle系列:组装数据集、搭建模型框架
- numpy: NumPy (Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
- functools:主要使用partial,用于数据集的构建工作
- random: 随机函数库
- matplotlib.pyplot:画图使用
- tqdm: 绘制进度条
import paddle
import paddlenlp
import tqdm
import numpy as np
import string
import random
import matplotlib.pyplot as plt
from functools import partial
3.数据集
我们使用的数据集是基于开源的对联数据集couplet-clean-dataset处理后的对联,并删掉了其中14条中文编码错误的对联,共744915条对联。我们使用的数据集地址:对联数据集
3.1 加载数据集
data_in_path="/home/aistudio/data/data110057/fixed_couplets_in.txt" # 上联路径
data_out_path="/home/aistudio/data/data110057/fixed_couplets_out.txt" # 下联路径
# 从文件中读取数据
def openfile(src):with open(src,'r',encoding="utf-8") as source:lines=source.readlines()return linesdata_in=openfile(data_in_path)
data_out=openfile(data_out_path)
all_data_lines=len(data_in) # 统计对联的总数,为划分数据集做准备
3.2 对联预处理
- 添加[start] token与 [end] token,这两个token的作用是告诉网络我们输入的对联的开始和结束。
- 对联token的划分,根据空格划分token(一个汉字、标点都是一个token)
def delete_newline_and_space(lista): newlist=[]for i in range(len(lista)):newlist.append(["<start>"]+lista[i].strip().split()+['<end>'])return newlistdata_in_nospace=delete_newline_and_space(data_in)
data_out_nospace=delete_newline_and_space(data_out)# 展示处理结果
print("上联:",data_in_nospace[0])
print("下联",data_out_nospace[0])
上联: ['<start>', '腾', '飞', '上', '铁', ',', '锐', '意', '改', '革', '谋', '发', '展', ',', '勇', '当', '千', '里', '马', '<end>']
下联 ['<start>', '和', '谐', '南', '供', ',', '安', '全', '送', '电', '保', '畅', '通', ',', '争', '做', '领', '头', '羊', '<end>']
couplet_maxlen=max([len(i) for i in data_in_nospace]) # 获取对联的最大长度,作为统一的长度标准。
couplet_maxlen
34
3.3 建立语料库
- 首先根据训练集数据建立总语料库
- 然后建立token–>id的字典、id–>token的字典。在获取字典时,我们的写法是根据token频率获取;在实际应用的时候,我们设置的频率限制为0,也就是获取所有的token,因为总的token才不到1万个,数量不大,可以全部获取。
def bulid_cropus(data_in,data_out):crpous=[]for i in data_in:crpous.extend(i)for i in data_out:crpous.extend(i)return crpous
def build_dict(corpus,frequency):# 首先统计不同词(汉字)的频率,使用字典记录word_freq_dict={}for ch in corpus:if ch not in word_freq_dict:word_freq_dict[ch]=0word_freq_dict[ch]+=1# 根据频率对字典进行排序word_freq_dict=sorted(word_freq_dict.items(),key=lambda x:x[1],reverse=True)word2id_dict={}id2word_dict={}# 按照频率,从高到低,开始遍历每个单词,并赋予第一无二的 idfor word,freq in word_freq_dict:if freq>frequency:curr_id=len(word2id_dict)word2id_dict[word]=curr_idid2word_dict[curr_id]=wordelse: # else 部分在 使 单词 指向unk,对于汉字,我们不设置unk,令frequency=0word2id_dict[word]=1return word2id_dict,id2word_dict
word_frequency=0
word2id_dict,id2word_dict=build_dict(bulid_cropus(data_in_nospace,data_out_nospace),word_frequency)word_size=len(word2id_dict)
id_size=len(id2word_dict)
print("汉字个数:",word_size,"\n id个数:",id_size)
汉字个数: 9017 id个数: 9017
# 将token-->id的字典、id-->token的字典存储到文件中(不是必须的)
with open("word2id.txt",'w',encoding='utf-8') as w2i:for k,v in word2id_dict.items():w2i.write(str(k)+","+str(v)+'\n')with open("id2word.txt",'w',encoding='utf-8') as w2i:for k,v in id2word_dict.items():w2i.write(str(k)+","+str(v)+'\n')
3.4 输入向量化并划分数据集
- 统一长度:couplet_maxlen
- padid使用token
<end>的id代替 - 测试集:验证集:训练集=1:1:18.
def getensor(w2i,datalist,maxlength=couplet_maxlen):in_tensor=[]for lista in datalist:in_samll_tensor=[]for li in lista:in_samll_tensor.append(w2i[li])if len(in_samll_tensor)<maxlength:in_samll_tensor+=[w2i['<end>']]*(maxlength-len(in_samll_tensor))in_tensor.append(in_samll_tensor)return np.array(in_tensor)
in_tensor=getensor(word2id_dict,data_in_nospace)
out_tensor=getensor(word2id_dict,data_out_nospace)test_data_lines=int(all_data_lines*0.05)
val_data_lines=int(all_data_lines*0.1)test_in_tensor=in_tensor[:test_data_lines]
val_in_tensor=in_tensor[test_data_lines:val_data_lines]
train_in_tensor=in_tensor[val_data_lines:]test_out_tensor=out_tensor[:test_data_lines]
val_out_tensor=out_tensor[test_data_lines:val_data_lines]
train_out_tensor=out_tensor[val_data_lines:]print("训练集数目:",len(train_in_tensor),"测试集数目:",len(test_in_tensor),"验证集数目:",len(val_in_tensor))
训练集数目: 670424 测试集数目: 37245 验证集数目: 37246
3.5 封装数据集
# 1.继承paddle.io.Dataset
class Mydataset(paddle.io.Dataset):# 2. 构造函数,定义数据集大小def __init__(self,first,second):super(Mydataset,self).__init__()self.first=firstself.second=second# 3. 实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)def __getitem__(self,index):return self.first[index],self.second[index]# 4. 实现__len__方法,返回数据集总数目def __len__(self):return self.first.shape[0]
def prepare_input(inputs,padid):src=np.array([inputsub[0] for inputsub in inputs])trg=np.array([inputsub[1] for inputsub in inputs])trg_mask =(trg[:,:-1]!=padid).astype(paddle.get_default_dtype())return src,trg[:,:-1],trg[:,1:,np.newaxis],trg_mask
def create_data_loader(dataset):data_loader=paddle.io.DataLoader(dataset,batch_sampler=None,drop_last=True,batch_size=BATCH_SIZE,collate_fn=partial(prepare_input, padid=padid))return data_loader
# 封装数据集
BATCH_SIZE=128
padid=word2id_dict['<end>']train_tensor=Mydataset(train_in_tensor,train_out_tensor)
val_tensor=Mydataset(val_in_tensor,val_out_tensor)train_loader=create_data_loader(train_tensor)
val_loader=create_data_loader(val_tensor)
for i,data in enumerate(val_loader):for d in data:print(d.shape)break
[128, 34]
[128, 33]
[128, 33, 1]
[128, 33]
4.模型组网
# 为方便调试网络,我们提前定义一些参数
embed_dim=256 # 词嵌入embedding的维度
latent_dim=2048 # feed forward 前馈神经网络的相关参数
num_heads=8 # 多头注意力机制的‘头’数
4.1 Encoder
Encoder部分主要包含了多头注意力机制、层归一化层以及前馈神经网络序列。
- MultiHeadAttention :使用
paddle.nn.MultiHeadAttention实现多头注意力机制,需要注意其掩码attn_mask需要的shape是[batch_szie,num_heads,sequence_legth,sequence_legth] - Feed Forward:点式前馈网络由两层全联接层组成,两层之间有一个 ReLU 激活函数。
- LayerNorm:归一化层
class TransformerEncoder(paddle.nn.Layer):def __init__(self, embed_dim, dense_dim, num_heads):super(TransformerEncoder, self).__init__()self.embed_dim = embed_dimself.dense_dim = dense_dimself.num_heads = num_headsself.attention = paddle.nn.MultiHeadAttention(num_heads=num_heads, embed_dim=embed_dim, dropout =0.1)self.dense_proj =paddle.nn.Sequential(paddle.nn.Linear(embed_dim, dense_dim), paddle.nn.ReLU(),paddle.nn.Linear(dense_dim, embed_dim) )self.layernorm_1 = paddle.nn.LayerNorm(embed_dim)self.layernorm_2 = paddle.nn.LayerNorm(embed_dim)self.supports_masking = Truedef forward(self, inputs, mask=None):padding_mask=Noneif mask is not None:padding_mask = paddle.cast(mask[:, np.newaxis, np.newaxis, :], dtype="int32")attention_output = self.attention(query=inputs, value=inputs, key=inputs, attn_mask=padding_mask)proj_input = self.layernorm_1(inputs + attention_output)proj_output = self.dense_proj(proj_input)return self.layernorm_2(proj_input + proj_output)# pencoder=TransformerEncoder(embed_dim, latent_dim, num_heads)
# print(pencoder)
# inputs=paddle.rand([BATCH_SIZE,34,256])
# print("inputs.shape:",inputs.shape)
# out=pencoder(inputs)
# print("out.shape:",out.shape)
4.2 位置编码
Transformer模型并不包括任何的循环或卷积网络,所以模型添加了位置编码,为模型提供一些关于单词在句子中相对位置的信息。我们用paddle.nn.Embedding实现位置编码,其中num_embeddings=sequence_length。
class PositionalEmbedding(paddle.nn.Layer):def __init__(self, sequence_length, vocab_size, embed_dim):super(PositionalEmbedding, self).__init__()self.token_embeddings = paddle.nn.Embedding(num_embeddings =vocab_size, embedding_dim =embed_dim)self.position_embeddings = paddle.nn.Embedding(num_embeddings =sequence_length, embedding_dim =embed_dim)self.sequence_length = sequence_lengthself.vocab_size = vocab_sizeself.embed_dim = embed_dimdef forward(self, inputs):length = inputs.shape[-1]positions = paddle.arange(start=0, end=length, step=1)embedded_tokens = self.token_embeddings(inputs)embedded_positions = self.position_embeddings(positions)return embedded_tokens + embedded_positionsdef compute_mask(self, inputs, mask=None):return paddle.not_equal(inputs, 0)# ps=PositionalEmbedding(34,word_size,256)
# print(ps)
# inputs=paddle.randint(0,word_size,[BATCH_SIZE,34])
# print("inputs.shape:",inputs.shape)
# out=ps(inputs)
# print("out.shape:",out.shape)
4.3 Decoder
编码器含有两个多头注意力组件,一个用于处理西班牙语的输入,另一个用于处理编码器的输出和前一个多头注意力机制的输出。
class TransformerDecoder(paddle.nn.Layer):def __init__(self, embed_dim, latent_dim, num_heads):super(TransformerDecoder, self).__init__()self.embed_dim = embed_dimself.latent_dim = latent_dimself.num_heads = num_headsself.attention_1 = paddle.nn.MultiHeadAttention(num_heads=num_heads, embed_dim=embed_dim)self.attention_2 = paddle.nn.MultiHeadAttention(num_heads=num_heads, embed_dim=embed_dim)self.dense_proj = paddle.nn.Sequential(paddle.nn.Linear(embed_dim, latent_dim), paddle.nn.ReLU(),paddle.nn.Linear(latent_dim, embed_dim) )self.layernorm_1 = paddle.nn.LayerNorm(embed_dim)self.layernorm_2 = paddle.nn.LayerNorm(embed_dim)self.layernorm_3 = paddle.nn.LayerNorm(embed_dim)self.supports_masking = Truedef forward(self, inputs, encoder_outputs, mask=None):causal_mask = self.get_causal_attention_mask(inputs) #[batch_size, equence_length, sequence_length]padding_mask=Noneif mask is not None:padding_mask = paddle.cast(mask[:, np.newaxis, :], dtype="int32")padding_mask = paddle.minimum(padding_mask, causal_mask)attention_output_1 = self.attention_1(query=inputs, value=inputs, key=inputs, attn_mask=causal_mask)out_1 = self.layernorm_1(inputs + attention_output_1)attention_output_2 = self.attention_2(query=out_1,value=encoder_outputs,key=encoder_outputs,attn_mask=padding_mask,)out_2 = self.layernorm_2(out_1 + attention_output_2)proj_output = self.dense_proj(out_2)return self.layernorm_3(out_2 + proj_output)def get_causal_attention_mask(self, inputs):input_shape = inputs.shapebatch_size, sequence_length = input_shape[0], input_shape[1]i = paddle.arange(sequence_length)[:, np.newaxis]j = paddle.arange(sequence_length)mask = paddle.cast(i >= j, dtype="int32") #[sequence_length, sequence_length]mask = paddle.reshape(mask, (1,1, input_shape[1], input_shape[1])) #[1, equence_length, sequence_length]mult = paddle.concat([paddle.to_tensor(BATCH_SIZE,dtype='int32'), paddle.to_tensor([1,1, 1], dtype="int32")],axis=0,) #[batch_size,1,1]return paddle.tile(mask, mult) #[batch_size, equence_length, sequence_length]# decoder=TransformerDecoder(embed_dim, latent_dim, num_heads)
# print(decoder)# inputs=paddle.rand([BATCH_SIZE,34,256])
# enout=paddle.rand([BATCH_SIZE,34,256])# out=decoder(inputs,enout)
# print("out.shape:",out.shape)
4.4 搭建Transformer模型
class Transformer(paddle.nn.Layer):def __init__(self, embed_dim, latent_dim, num_heads,sequence_length, vocab_size):super(Transformer, self).__init__()self.ps1=PositionalEmbedding(sequence_length, vocab_size, embed_dim)self.encoder=TransformerEncoder(embed_dim, latent_dim, num_heads)self.ps2=PositionalEmbedding(sequence_length, vocab_size, embed_dim)self.decoder=TransformerDecoder(embed_dim, latent_dim, num_heads) self.drop=paddle.nn.Dropout(p=0.5)self.lastLinear=paddle.nn.Linear(embed_dim,vocab_size)self.softmax=paddle.nn.Softmax()def forward(self,encoder_inputs,decoder_inputs):# 编码器encoder_emb=self.ps1(encoder_inputs)encoder_outputs=self.encoder(encoder_emb)# 解码器deocder_emb=self.ps2(decoder_inputs)decoder_outputs=self.decoder(deocder_emb,encoder_outputs)# dropoutout=self.drop(decoder_outputs)#最后输出out=self.lastLinear(out)return outtrans=Transformer(embed_dim, latent_dim, num_heads,couplet_maxlen, word_size)
paddle.summary(trans,input_size=[(BATCH_SIZE,34),(BATCH_SIZE,34)],dtypes='int32')
W1122 09:28:31.102437 1380 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1122 09:28:31.106657 1380 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.---------------------------------------------------------------------------------------------Layer (type) Input Shape Output Shape Param #
=============================================================================================Embedding-1 [[128, 34]] [128, 34, 256] 2,308,352 Embedding-2 [[34]] [34, 256] 8,704
PositionalEmbedding-1 [[128, 34]] [128, 34, 256] 0 Linear-1 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-2 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-3 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-4 [[128, 34, 256]] [128, 34, 256] 65,792
MultiHeadAttention-1 [] [128, 34, 256] 0 LayerNorm-1 [[128, 34, 256]] [128, 34, 256] 512 Linear-5 [[128, 34, 256]] [128, 34, 2048] 526,336 ReLU-1 [[128, 34, 2048]] [128, 34, 2048] 0 Linear-6 [[128, 34, 2048]] [128, 34, 256] 524,544 LayerNorm-2 [[128, 34, 256]] [128, 34, 256] 512
TransformerEncoder-1 [[128, 34, 256]] [128, 34, 256] 0 Embedding-3 [[128, 34]] [128, 34, 256] 2,308,352 Embedding-4 [[34]] [34, 256] 8,704
PositionalEmbedding-2 [[128, 34]] [128, 34, 256] 0 Linear-7 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-8 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-9 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-10 [[128, 34, 256]] [128, 34, 256] 65,792
MultiHeadAttention-2 [] [128, 34, 256] 0 LayerNorm-3 [[128, 34, 256]] [128, 34, 256] 512 Linear-11 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-12 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-13 [[128, 34, 256]] [128, 34, 256] 65,792 Linear-14 [[128, 34, 256]] [128, 34, 256] 65,792
MultiHeadAttention-3 [] [128, 34, 256] 0 LayerNorm-4 [[128, 34, 256]] [128, 34, 256] 512 Linear-15 [[128, 34, 256]] [128, 34, 2048] 526,336 ReLU-2 [[128, 34, 2048]] [128, 34, 2048] 0 Linear-16 [[128, 34, 2048]] [128, 34, 256] 524,544 LayerNorm-5 [[128, 34, 256]] [128, 34, 256] 512
TransformerDecoder-1 [[128, 34, 256], [128, 34, 256]] [128, 34, 256] 0 Dropout-1 [[128, 34, 256]] [128, 34, 256] 0 Linear-17 [[128, 34, 256]] [128, 34, 9017] 2,317,369
=============================================================================================
Total params: 9,845,305
Trainable params: 9,845,305
Non-trainable params: 0
---------------------------------------------------------------------------------------------
Input size (MB): 0.03
Forward/backward pass size (MB): 818.03
Params size (MB): 37.56
Estimated Total Size (MB): 855.62
---------------------------------------------------------------------------------------------{'total_params': 9845305, 'trainable_params': 9845305}
5.模型训练与评估
5.1 自定义loss函数
class CrossEntropy(paddle.nn.Layer):def __init__(self):super(CrossEntropy,self).__init__()def forward(self,pre,real,trg_mask):# 返回的数据类型与pre一致,除了axis维度(未指定则为-1),其他维度也与pre一致# logits=pre,[batch_size,sequence_len,word_size],猜测会进行argmax操作,[batch_size,sequence_len,1]# 默认的soft_label为False,lable=real,[bacth_size,sequence_len,1]cost=paddle.nn.functional.softmax_with_cross_entropy(logits=pre,label=real)# 删除axis=2 shape上为1的维度# 返回结果的形状应为 [batch_size,sequence_len]cost=paddle.squeeze(cost,axis=[2])# trg_mask 的形状[batch_size,suqence_len]# * 这个星号应该是对应位置相乘,返回结果的形状 [bathc_szie,sequence_len]masked_cost=cost*trg_mask# paddle.mean 对应轴的对应位置求平均return paddle.mean(paddle.mean(masked_cost,axis=[0]))
5.2 训练与验证
epochs = 10
trans=Transformer(embed_dim, latent_dim, num_heads,couplet_maxlen, word_size)
model=paddle.Model(trans)model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),loss=CrossEntropy(), metrics=paddlenlp.metrics.Perplexity())model.fit(train_data=train_loader, epochs=epochs,eval_data= val_loader,save_dir='./savemodel',save_freq=5,verbose =0,log_freq =2000,callbacks=[paddle.callbacks.VisualDL('./log')])
save checkpoint at /home/aistudio/savemodel/0
save checkpoint at /home/aistudio/savemodel/5
save checkpoint at /home/aistudio/savemodel/final
10个epoch下的loss与Perplexity曲线图:
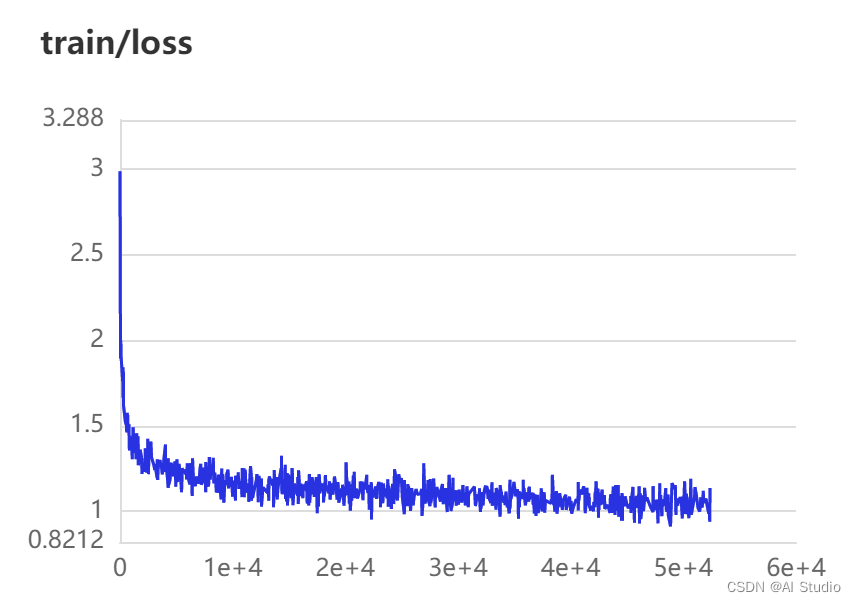
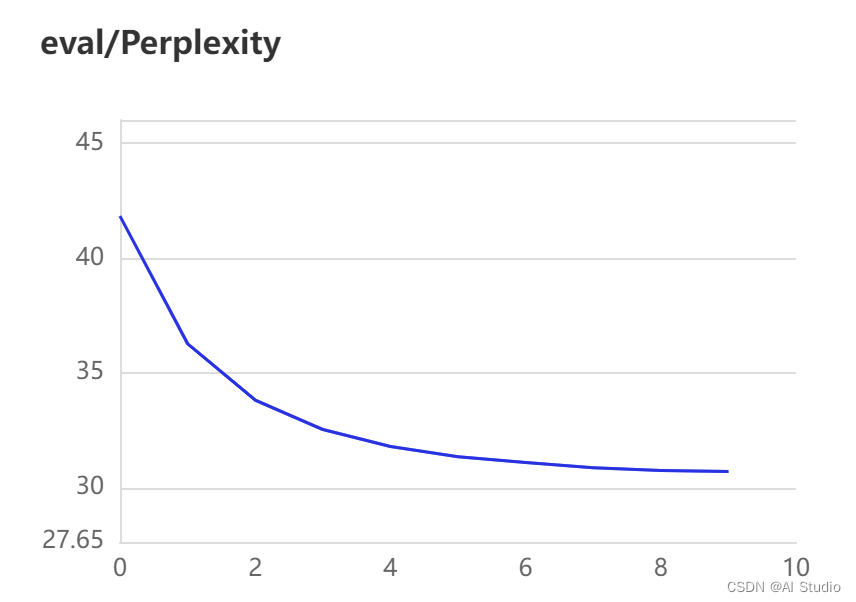
6. 结果预测
def evalute(eng,maxlen=couplet_maxlen):encoder_input=paddle.unsqueeze(eng,axis=0)decoded_sentence = "<start>"def get_pre_tensor(w2i,s,maxlen=maxlen):x=[padid]*couplet_maxlenlista=s.split()for i in range(len(lista)):x[i]=w2i[lista[i]]return paddle.to_tensor([x],dtype='int32')for i in range(maxlen):decoder_input=get_pre_tensor(word2id_dict,decoded_sentence)pre=trans(encoder_input,decoder_input)sampled_token_index = np.argmax(pre[0, i, :])sampled_token = id2word_dict[sampled_token_index]decoded_sentence += " " + sampled_tokenif sampled_token == "<end>":breakreturn decoded_sentence
def translate():with open('result.txt','w+') as re:#for i in tqdm.tqdm(range(len(test_in_tensor))):for i in range(5): result=evalute(paddle.to_tensor(test_in_tensor[i]))re.write(result+'\n')
translate()
with open('result.txt','r') as re:pre=re.readlines()for i in range(2):print('上联: ',"".join(l for l in data_in_nospace[i]))print('真实的下联:',"".join(l for l in data_out_nospace[i]))print('预测的下联:',pre[i])
上联: <start>腾飞上铁,锐意改革谋发展,勇当千里马<end>
真实的下联: <start>和谐南供,安全送电保畅通,争做领头羊<end>
预测的下联: <start> 发 展 宏 图 , 激 情 发 展 建 和 谐 , 喜 做 万 年 春 <end>上联: <start>风弦未拨心先乱<end>
真实的下联: <start>夜幕已沉梦更闲<end>
预测的下联: <start> 月 色 初 圆 梦 亦 空 <end>
实的下联: 夜幕已沉梦更闲
预测的下联: 月 色 初 圆 梦 亦 空
7.总结
- 本项目基于tranformer训练了一个可以对对联的神经网络模型,输出的结果在
对仗方面很好。 - 本项目的不足在与模型输出的下联在
语义上不是非常好,比如上联的“勇当千里马”,我们下联给的“喜做万年春”,马和春在语义上是不相关的。因此,本项目的一个改进方向就是语义方向。
总的来说,本项目是基于transformer对联模型全流程搭建流程,内容还算详细,欢迎uu们fork交流呀qwq
此文章为搬运
原项目链接
这篇关于【提前过年吧】来对对联吧,基于transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







