本文主要是介绍SSD MTCNN YOLO基本对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SSD与MTCNN的区别
1)生成训练数据的方式不同
MTCNN需要将训练样本事先生成好,同时生成label(分类label和回归label),然后输入到网络中训练,而SSD直接输入原图,实际的训练数据由数据层和priorbox层共同完成,其中priorbox层用来确定每个样本的label,也就是说SSD将MTCNN的生成训练数据的部分融合到一个网络中,实现了真正意义上的端到端。
2)MTCNN和SSD实现了两种滑动窗口检测策略
MTCNN:首先构建图像金字塔,然后使用固定大小的滑动窗口在金字塔每一级滑动,对每个滑动窗口分类回归。这个固定大小的滑动窗口的大小就是PNet的输入大小,滑动窗口操作由全卷积PNet实现。
SSD: 近似于在原图中设置了不同大小的滑动窗口,对不同大小的滑动窗口进行分类和回归。由于SSD可以看作是由6个不同的PNet组成,所以这些不同大小的滑动窗口其实对应了6种PNet。
不管是MTCNN,还是SSD,本质上是对所有滑动窗口的分类。这与传统的目标检测方法本质上是一样的。
3)SSD使用3x3卷积核进行分类和回归,而MTCNN使用1x1卷积核进行分类和回归
3x3的卷积核覆盖了该像素点的感受野以及它的领域,加入了局部信息,使得模型更加鲁棒。
-
一. 我们发现SSD比Faster rcnn默认框还多,更比yolo多的多,为什么省时间呢?
1)Faster-rcnn是一个双阶段网络,尽管Faster-rcnn的BB少很多,但是其需要大量的前向和反向推理(训练阶段),而且需要交替的训练两个网络
2)SSD其实相当于一个优化了的RPN网络,不需要进行后面的检测,且没有全连接层裁剪
3)YOLO网络中含有大量的全连接层
4)通过裁剪限制输入图片大小 ,从而限制计算量
二.YOLOv3 为什么速度比ssd快呢?
1)分类器不同,ssd采用了softmax分类器。而yolov3则使用了多logistic分类器分别针对每个类进行二分类,只用设置阈值,便可以大批量筛选。
2)yolov3的默认框选取采用了聚类的方式,聚类
3)在ssd预测时,每次预测的bbox都是在defalut bbox上基础上,预测出其偏移量。
在刚开始训练时我们预测时,会十分不稳定,导致位置偏移量很大,出现越界现象(即超出图片范围),因此yolov3会在每个位置偏移后加入sigmoid函数激活(将其限定在0-1之间)(可以更有效进行多通道的融合)。
4) Darknet网络是个全卷积网络,大量采用残杀跳层。且网络中使用歩长为2 的卷积操作对网络进行降采样。
5)

三.分析 smooth 激活函数的意义
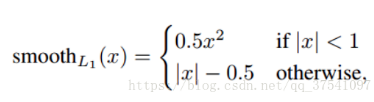
有函数可知,当坐标偏差过大时,斜率不再是正比增大,而是常数增长,可以有效减小 ![]() ,使得偏差大的坐标对训练影响小
,使得偏差大的坐标对训练影响小
YOLO ,SSD对目标检测的发展史:
yolov1:最后一层的输出特征图是固定7*7
缺点:最后一层的输出特征图是固定7*7
SSD:最后一层的检测是由之前多个尺度(Multi-Scale)的特征图共同生成的。
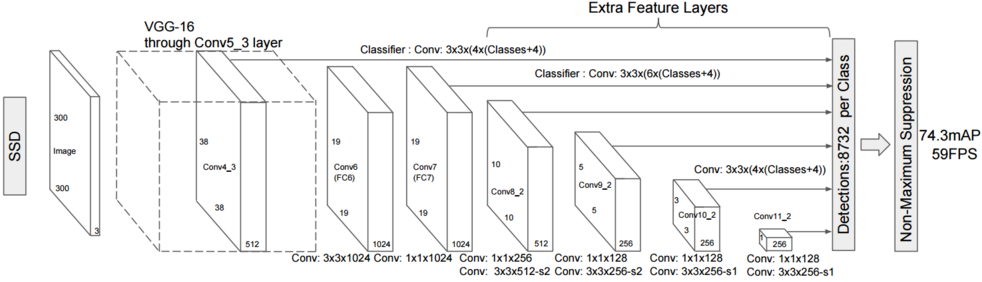
缺点:对于极小的目标识别,SSD就显得无能为力了

例如图中的风筝
FPN(特征金字塔网络):从顶层(自上而下)的每一层都进行上采样获取更准确的像素位置信息(有些类似残差网络的跳层连接)
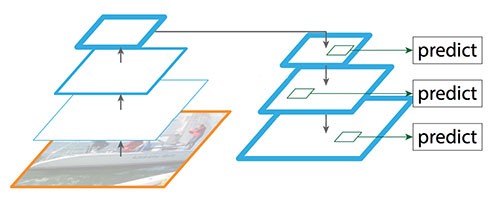
卷积操作缺点:像素错位(最上层特征图中,你早已分不清某个像素对应原图的哪些像素)
上采样还原特征图的方式很好地缓解了像素不准的问题(使得高层特征图的像素也有据可查)
缺点:计算量的增多(额外的上采样和跳层计算)
SNIPER:每个尺度大类下都维护一个重点关注区域(region)
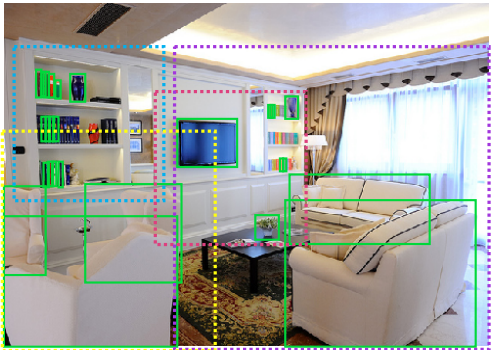
实线框是ground truth的目标物体框,可见SNIPER试图把ground truth都圈围在重点关注区域的合适尺度下。此外,SNIPER还在重点关注区域中加入了重点排除区域,在许多背景中,许多目标是无须识别的

其中红色框就是重点排除区域,与FPN不同的是,SNIPER不再需要处理每一层特征图的像素进行上采样,计算量下降了不少,据说只比普通的类似yolo的one shot模型多处理30%的像素
这篇关于SSD MTCNN YOLO基本对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



