本文主要是介绍基于Python的电影票房信息数据的爬取及分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、研究背景与意义
- 1.1研究现状
- 1.2研究方法
- 二、功能性需求分析
- 3.1系统功能分析
- 3.2系统功能性需求分析
- 3.2.1 系统用户功能性需求分析
- 三、项目的实现
- 4.1 以2019年的票房榜单Top20为例分析
- 6.2 结果分析
- 四、总结
- 六、 目录
概要
现如今,人民群众对物质生活水平的要求已不再局限于衣食住行,对于精神文化有了更多的需求。电影在我国越来越受欢迎,电影业的发展越来越迅猛,为了充分利用互联网技术的发展,掌握电影业的态势,对信息进行挖掘和处理、提高数据库的利用率,本文采用文献分析法,对网络爬虫的相关内容以及发展现状进行简单介绍,并利用网页抓取技术爬取电影票房网站的相关数据,进行分析,为票房分析提供数据支撑。
关键词:Python 网络爬虫 电影票房
一、研究背景与意义
1.1研究现状
&emsp网络爬虫在消息探索与数值整理进程中发挥着关键作用,上世纪初,就已有科学家对爬虫开启探究模式,现今,爬虫技能已处于成熟阶段。网络爬虫可主动获取网络界面,从而自行下载主人所需要的东西,基本实现了大幅度的数据下载模式,也更便于人们利用其进行高效工作。
在我国,爬虫技能发展的有关探究开启速度比较慢,但其后续的发展却非常迅猛。2003年该技能得到正式发展,国内数据探索的学论会越来越常态化,在该区域中的探究也随之扩展。2007年,浙大教授罗兵在旧版网络爬虫的基准上,增添了分析模型,使对该内容的分析越发完善。近几年,经过我国学界的专家、学者们的积极探讨与破除障碍,使得我国流动性网络消息的获得能力不断提升,爬虫体系的效能也随之增强。既减弱了人工完成的压迫感,也逐步实现了高效率的下载任务,成为了大众查找、分解与融合信息中不可或缺的手段。
1.2研究方法
①著作了解法
②撰写程序语言:Python语言、HTML语言、JS语言、css语言
③信息库技能:MySQL信息库技能
二、功能性需求分析
3.1系统功能分析
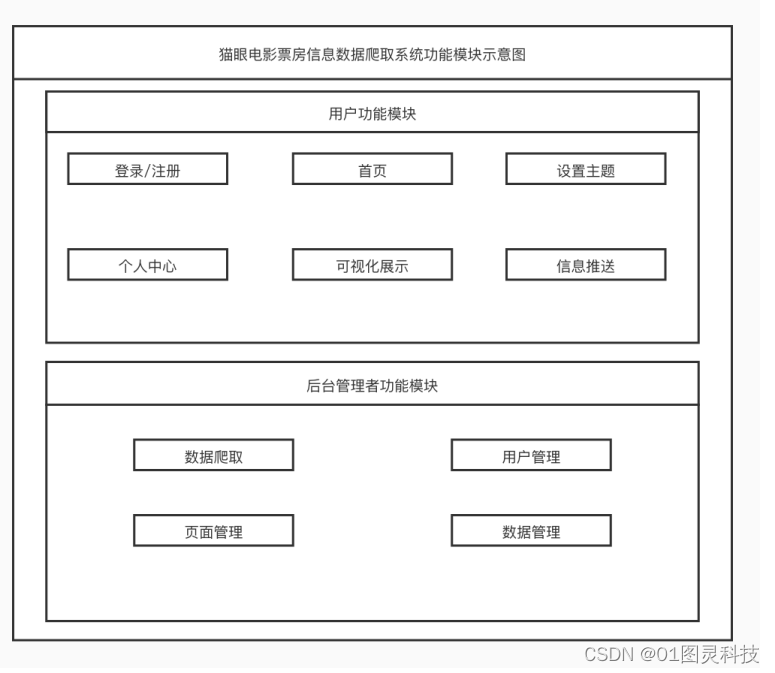
本电影信息数据爬取系统主要由后台管理模块和用户模块两大模块组成,其中用户模块的适用对象为普通用户,主要功能包括了登录注册、主题设置、个人中心、可视化展示以及信息推送功能。其中除了登录注册功能之外,其他功能需要再用户登录的情况下才能使用。接着是后台管理模块,其适用对象主要为管理者。后台管理模块的主要功能为:数据爬取、用户管理、页面管理以及数据管理。其管理权限较大。具体功能模块示意图如3-1所示。
其中,管理员功能用例图对应图3-3,用户功能用例图对应图3-2
图3-1 系统功能模块示意图
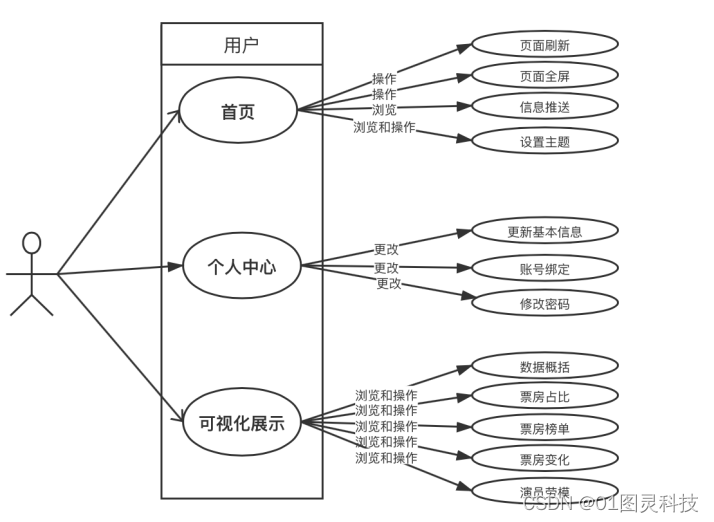
图3-2 用户功能用例图
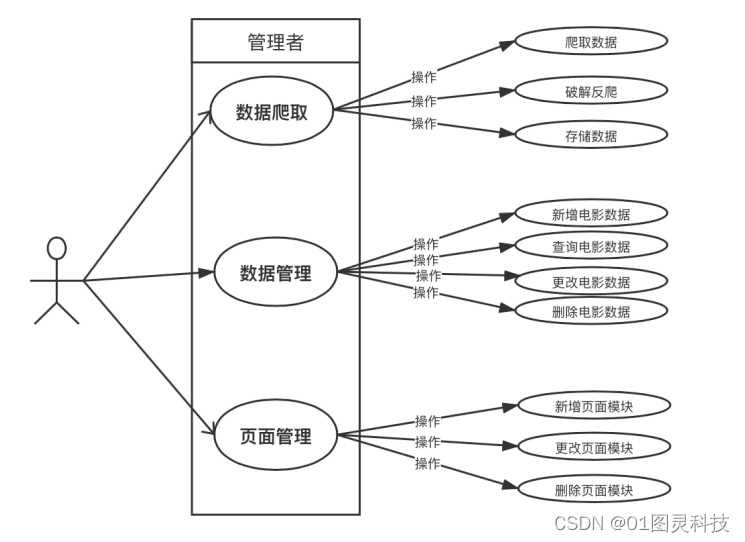
图3-3 管理员功能用例图
3.2系统功能性需求分析
本节从用户功能和管理员这两个模块分别阐述其功能性需求和做详细的分析介绍。通过详细的分析介绍进一步明确系统功能性需求,为接下来的系统设计与开发做好布置工作。
3.2.1 系统用户功能性需求分析
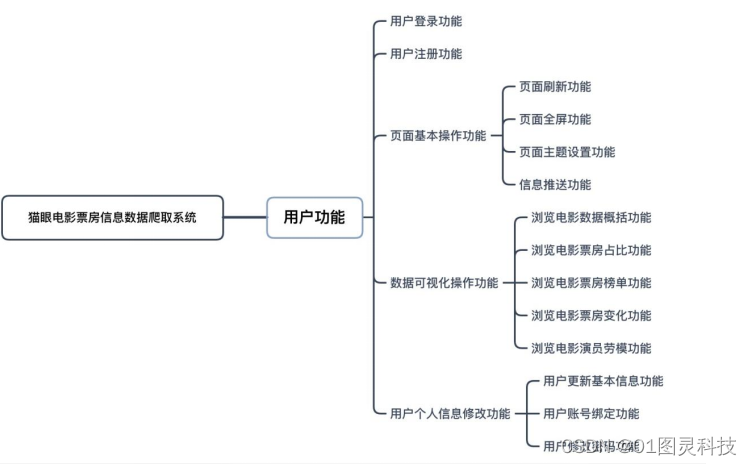
图3-4 用户功能需求概述图
图3-4为猫眼电影票房信息数据爬取系统的用户功能需求的概述图,下面将对图3-4所列的功能进行详细的讲解和说明。
(1)用户登录功能
用户登录功能为该系统的基础功能,用户进入该系统的前提是登录账号,登录账号之后可以进入系统,并且系统会开放所有功能供用户使用。用户在未登录账号的情况下,无法进入该系统。
(2)用户注册功能
用户注册功能的作用是让用户在未拥有账号的状态下可以进行注册,获得账号,以得到更多的功能。
(3)页面基本操作功能
页面基本操作功能是该系统的基础功能,该功能具有四个子功能,分别为页面刷新功能、页面全屏功能、页面主题设置功能以及信息推送内容。以下对其四个子功能进行详细的讲解和说明。
页面刷新功能:该功能为页面基础功能的子功能之一,主要是给系统页面进行刷新,将系统页面置于初始状态。
页面全屏功能:该功能为页面基础功能的子功能之一,主要是将系统页面放至全屏状态,方便用户更详细的查看页面。
页面主题设置功能:该功能为页面基础功能的子功能之一,主要是将系统页面的主题颜色、按钮进行更改,方便用户根据自己的喜好对系统页面主题进行DIY设置。
信息推送功能:该功能为页面基础功能的子功能之一,主要是查看和预览用户的个人推送信息。
(4)数据可视化操作功能
数据可视化操作功能为该系统的重要功能,该功能具有五个子功能,分别为浏览电影票房变化功能、浏览电影数据概括功能、浏览电影票房榜单功能、浏览电影演员劳模功能以及浏览电影票房占比功能。以下将其五个子功能进行详细的讲解和说明。
浏览电影数据概括功能:该功能为数据可视化操作功能的子功能之一,主要是对全部电影信息数据进行概括,将其基本信息以表格形式展示出来,方便用户浏览查看。
浏览电影票房占比功能:该功能为数据可视化操作功能的子功能之一,主要是对各个电影类型票房占比情况分别以柱状图和玫瑰图的形式展示出来,用户可以选择不同的年份和月份查看不同时期时的各个电影类型票房占比情况。
浏览电影票房榜单功能,该功能为数据可视化操作功能的子功能之一,主要是将电影票房靠前的电影名字以词云图的形式展示出来,用户可以选择不同的年份和排行数量,查看不同时期时电影票房排行靠前的电影名字。票房越高的电影,其名称字号大小将会更大。方便用户对电影票房查看,一目了然。
浏览电影票房变化功能,该功能为数据可视化操作功能的子功能之一,主要是将2015年至2019年的电影票房走势以折线图的形式展示出来,用户可以选择不同的电影类型查看该电影类型的票房走势情况。
浏览电影演员劳模功能,该功能为数据可视化操作功能的子功能之一,主要是将电影演员参演次数情况以词云图和柱状图的形式展示出来,用户可以选择不同的年份和排行数量,查看不同时期时电影演员参演次数靠前的演员名字。参演次数越多的演员,在词云图里,其名字的字号大小将会更大,在柱状图里,将会更明显。
(5)用户个人信息修改功能
用户个人信息修改功能为该系统的基础功能,该功能具有三个子功能,分别为用户更新基本信息功能、用户账号绑定功能以及用户修改密码功能。以下将其三个子功能进行详细的讲解和说明。
用户更新基本信息功能,该功能为用户个人信息修改功能的子功能之一,用户在该功能上可以更改自己的邮箱、昵称、个人简介、街道地址以及联系电话信息。
用户账号绑定功能,该功能为用户个人信息修改功能的子功能之一,用户可以在该功能上可以修改密保手机、密保邮箱、绑定QQ以及绑定微信。
用户修改密码功能,该功能为用户个人信息修改功能的子功能之一,用户可以在该功能上修改自己的账号密码。
三、项目的实现
经过一系列的爬虫工作,将有效的数据存储到数据库,最后再清洗加工将其可视化,直观地展示出数据的价值及意义。
4.1 以2019年的票房榜单Top20为例分析
构建2019年票房榜单Top20词云图,其生成图如下图6-1所示:

图6-1 2019年的票房榜单Top20词云图
6.2 结果分析
以上图6-1的2019年的票房榜单Top20词云图为例,票房榜首的《哪吒之魔皇降世》在图6-1中十分突出明显,该影片在上映短短的时间内就突破了以往动漫电影的票房记录。《哪吒之魔皇降世》的成功,归功于该影片创作团队的努力。导演一人为了该部影片亲力亲为,甚至为了省钱,自学担任动画的动作指导。而参与制作这部影片的人数高达1600多人,突破了目前国产动画制作人数的记录,是国产动漫电影新的里程碑。同时这部电影传达的价值观念也深深的引起广大观众的共鸣。只要努力,即使与众不同也能找到自己的光辉。所谓那句“我命由我不由天”。
下面以2015年至2019年之间电影票房为例,实现可视化。
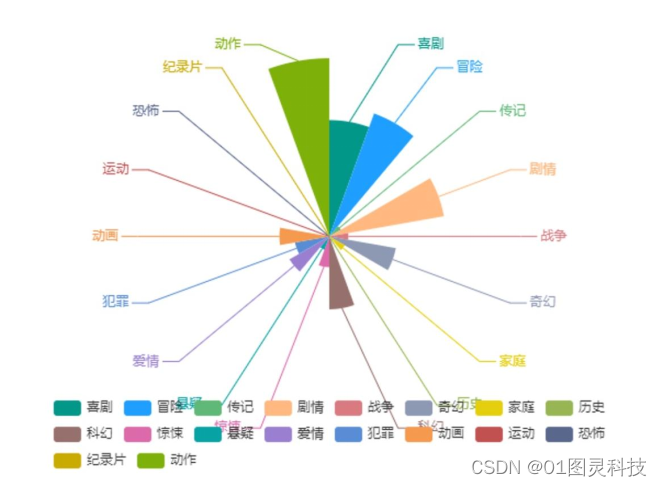
图6-2各电影类型票房占总电影票房的玫瑰图
图6-2的玫瑰图是通过统计2015年至2019年里评分排行靠前的电影列表中,各部电影类型票房占全部电影票房的百分比。通过玫瑰图6-2 可以看到票房排行前三的分别是:动作、冒险及喜剧。可见观众对于动作片的喜爱程度是十分之高的,更偏向于视觉上带来的享受。

图6-3 总票房排名前20的词云图
图6-3的词云图是通过统计2015年至2019年里评分排行靠前的电影清单中,对总票房里排名前20的各部电影做视觉上的突出。图中清晰地看到《战狼2》这部电影的票房是最高的。《战狼2》这部电影的成功是多方面因素的结果,起决定作用的还是电影的质量,电影不论是在特效的处理上还是对剧情的把握,都不输好莱坞大片。同时该部电影军旅题材符合爱国主旋律,上映的时机恰逢建军90周年,观众对于民族文化的认同感在该部电影上得到了极大的共鸣。
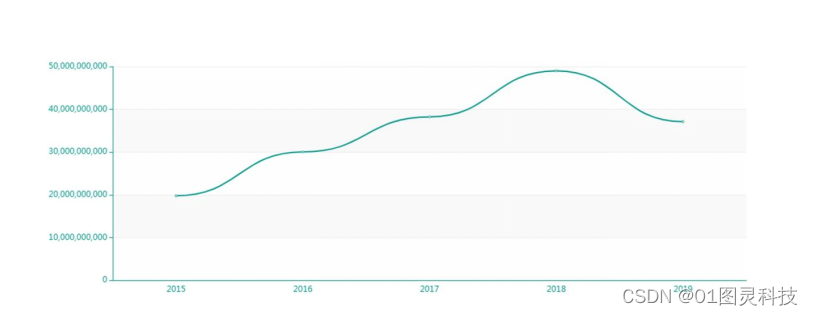
图6-4 2015年至2019年总票房走势折线图
图6-4的折线图是通过统计2015年至2019年里评分排行靠前的电影清单中,电影总票房在这段时期里的走势。图中清晰地看到在2018年总票房达到顶峰,随之到了2019年出现下滑趋势。分析来看,2019年出现下滑原因主要有三个:1.许多热门的电影在2019年6月份的暑期阶段宣布了撤档,这对于原本期待影片上映的许多观众都没法到影院进行观看,影院票房的跌落十分明显。2.全国的银幕数量增速放缓。3.可能是热门头部电影的撤档,导致了影院观影的人数大幅度下降,再加上票房的上升,让许多观众望而止步。

图6-5 “演员劳模”词云图
图6-5的词云图是通过统计2015年至2019年里评分排行靠前的电影清单中,各个演员参演次数在总演员参演次数里,出现频率最高的“演员劳模”。图中清晰地看到道恩·强森这位演员近年来参演次数是最高的。笔者认为,国内外电影最大的差别就是演员的努力程度,近几年参演次数最高的道恩·强森,即使是参演次数很高,但是一年的录制的影视也没有多于五部,在保证影片质量同时也如此“高产”,可见的其投入的精力之多和时间分配的合理。一部作品的好坏和演员对作品的投入程度是离不开的。演员的付出对得起来之不易的作品剧本,只有这样才可以观众带来更好的作品。
四、总结
电影发展的越来越迅速,如何在这块红海市场中分得一杯羹成为一个比较具有挑战性的问题,因此本文基于python爬虫制作了一个爬取电影票房网站的爬虫程序,成功地爬取到了电影票房的数据并且保存到了数据库中并进行分析,通过这种操作,使得电影的票房更加透明,清晰。本文基于Python语言,对电影票房网站进行信息数据爬取和分析,通过利用 Python 抓取电影票房数据内容,数据从MYSQL 数据库提取出来,进行有效的清洗,使用MySQL和pandas库等方式进行操作,使用web前端网页,让数据以柱状图、玫瑰图、折线图,以及词云图等方式展示在大众的眼前。以数据展示的结果,从而对某个时间段的电影票房的数据进行分析,进而了解大众专注热点趋势,进而分析了热点电影的基本情况。
该系统利用了Python丰富的标准库以及快速开发的特长,其主要有这几个不错的优点:(1)该爬取系统对于使用Python程序比较陌生或者不熟悉的人来说也能很容易上手,只需要点击运行爬取程序里的get_data.py文件,爬取系统就会自动爬取数据,以完成复杂的爬取工作(2)采用相似度距离算法方式破解了猫眼电影网字体反爬,其亮点是方法新颖。(3)在Python程序里导入time方法,通过10秒的休眠时间,很大程度上降低了访问请求页面的频率。让服务器误以为是人为的操作,因此避免了被猫眼电影网站阻止或拒绝。(4)在爬虫程序里添加了头部信息headers文件,伪装给web服务器让其辨别为浏览器行为。方便后续的爬取工作正常进行。
六、 目录
目录
摘 要 1
Abstract 1
一、绪论 3
1.1研究背景 4
1.2研究现状 4
1.3研究方法 4
二、系统开发工具与相关技术 5
2.1 Python网络爬虫 5
2.2系统开发工具 5
2.2.1 pycharm工具 5
2.2.2 MySQL数据库 5
2.2.3 Hbuilder X工具 6
2.3系统后台技术 6
2.4 系统前端技术 6
三、系统分析 8
3.1 系统功能分析 8
3.2 系统功能性需求分析 10
3.2.1 系统用户功能性需求分析 10
3.2.2 系统管理员功能性需求分析 12
3.3 数据获取 14
3.4 数据分析 13
3.5 数据展示 13
四、系统设计 15
4.1文件结构图 15
4.1.1前端demo文件结构图 15
4.1.2后端爬虫系统文件结构图 15
4.2前端功能模块 16
4.3登录与注册模块设计 16
4.4数据库表设计 17
4.5数据展示模块设计 18
五、系统实现 20
5.1解决网站反爬机制 20
5.2 实现网络爬虫 23
5.2.1找出url变化规则并获取链接 26
5.2.2解析并获取网页数据 26
5.2.3将数据存储至数据库 27
5.3 登录注册模块实现 28
5.4 数据展示模块实现 28
六、 票房网站信息数据爬取结果及分析 32
6.1以2019年的票房榜单Top20为例分析 32
6.2结果分析 32
七、结论与建议 36
7.1结果分析 36
7.2不足点 36
7.3对未来的展望 37
参考文献 38
致 谢 39
这篇关于基于Python的电影票房信息数据的爬取及分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








