本文主要是介绍火山引擎 ByteHouse:TB 级数据下,如何实现高效、稳定的数据导入,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
近期,火山引擎开发者社区、火山引擎数智平台(VeDI)联合举办以《数智化转型背景下的火山引擎大数据技术揭秘》为主题的线下 Meeup。活动主要从数据分析、数据治理、研发提效等角度,带领数据领域从业者全面了解数智化转型背景下的火山引擎数据飞轮模式在数据资产建设上的技术与实践。其中,火山引擎 ByteHouse 产品专家受邀到现场,发表主题为《基于 ByteHouse 引擎的增强型数据导入技术实践》的分享。
数据导入是衡量 OLAP 引擎性能及易用性的重要标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。作为一款 OLAP 引擎,火山引擎云原生数据仓库 ByteHouse 源于开源 ClickHouse,在字节跳动多年打磨下,提供更丰富的能力和更强性能,能为用户带来极速分析体验,支撑实时数据分析和海量离线数据分析,具备便捷的弹性扩缩容能力,极致的分析性能和丰富的企业级特性。
随着 ByteHouse 内外部用户规模不断扩大, 越来越多用户对数据导入提出更高的要求,这也为 ByteHouse 的数据导入能力带来了更大的挑战。
从字节跳动内部来看,ByteHouse 主要以 Kafka 为实时导入的主要数据源。对于大部分内部用户而言,其数据体量偏大,用户更看重数据导入的性能、服务的稳定性以及导入能力的可扩展性。在数据延时性方面,用户的需求一般为秒级左右。
据火山引擎 ByteHouse 产品专家的介绍,基于以上场景和需求,ByteHouse 首先基于 ClickHouse 引擎进行升级,其次又针对数据导入能力进行一系列定制性优化,主要包括两个方面,第一为 MaterializedMySQL 增强;第二个是 HaKafka 引擎。

在引擎优化方面,在 TB 级数据量级下,ClickHouse 容易出现集群故障,还存在读性能较低、耗损内存的问题。针对这些痛点,ByteHouse 自研的 HaMergeTree 和 HaUniqueMergeTree 可以降低负载,确保集群在单节点故障下能平稳运行服务,还能平衡读写性能,保障读取时性能一致。
在数据导入能力的定制化优化方面,社区版 MaterializedMySQL 不支持分布式表等功能,也存在无法定位问题、无法同步状态等运维问题。一方面,通过构建分布式模式的 MaterializedMySQL 库,用户可将每个表都对应同步至 ByteHouse 的一个分布式表,让数据不重复存储,充分利用分布式集群的计算能力,又降低了对源端的同步压力。另一方面,ByteHouse 也提供可视化运维的功能,支持同步状态和任务管理,一旦出现系统运维故障,用户会收到异常警告。
而 HaKafka 引擎则是 ByteHouse 推出的一种特殊的表引擎,主要基于 ClickHouse 社区的 Kafka engine 进行了优化。用户可以通过一个 Kafka 消费表、分布式存储表、物化视图表,三元组实现数据消费、数据转换、数据写入功能。
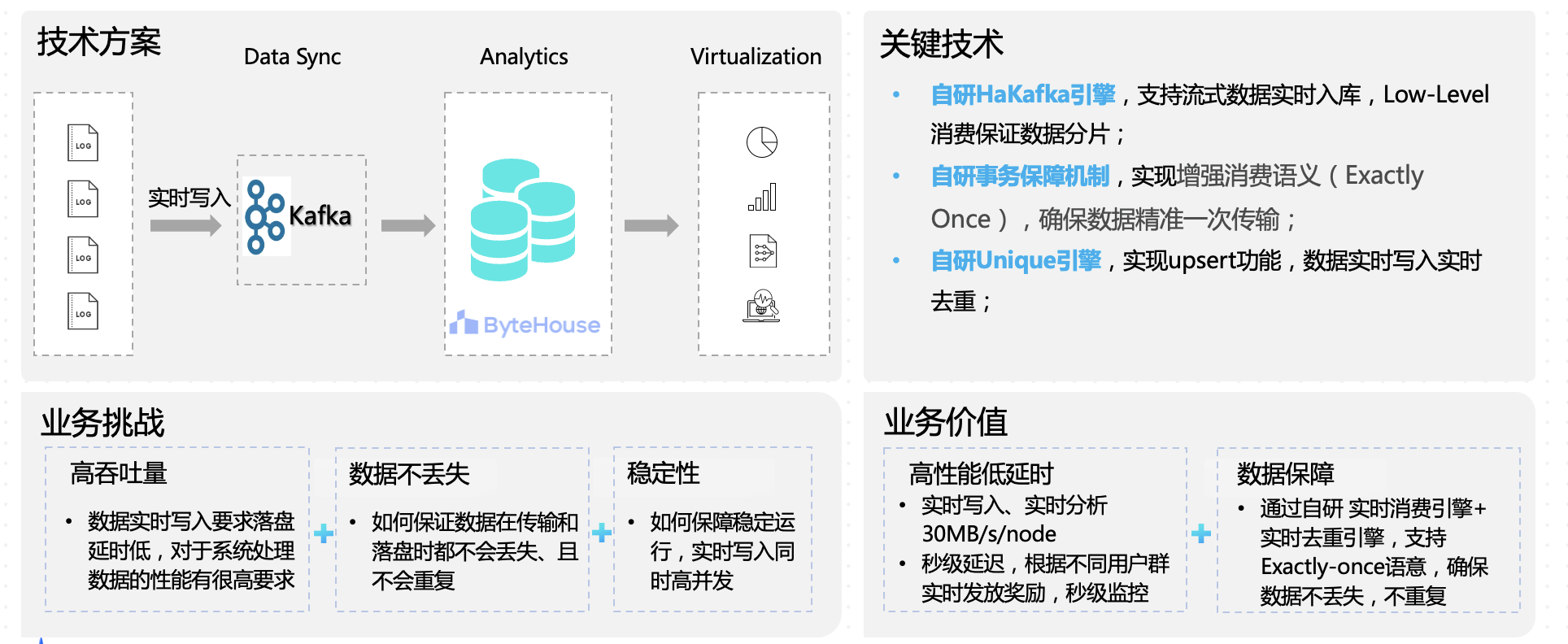
目前,以上能力已经在短视频、营销实时数据监控、游戏广告数据分析等领域落地。以营销实时数据监控为例,活动的主办方需要对营销活动效果进行实时监控,以便通过实时奖励发放来动态调整奖励流量分配,提升 ROI 收益。这类场景要求数据实时写入,对系统性能具备高要求 。另外,为保障奖励不会发放错误,也需要保证数据在传输和落盘时都不丢失、不重复,且稳定运行。
ByteHouse 基于自研 HaKafka 引擎,能支持流式数据实时入库, 用自研事务保障机制,确保数据精准一次传输,最后通过自研 Unique 引擎实现数据实时写入实时去重。在效果上实现实时写入、实时分析 30MB/s/node,业务可以根据不同用户群实时发放奖励,做到秒级延迟、秒级监控。
这篇关于火山引擎 ByteHouse:TB 级数据下,如何实现高效、稳定的数据导入的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






