本文主要是介绍常用排序算法分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 插入排序
1.1 性能分析
时间复杂度O(n^2), 空间复杂度O(1)
排序时间与输入有关:输入的元素个数;元素已排序的程度。
最佳情况,输入数组是已经排好序的数组,运行时间是n的线性函数; 最坏情况,输入数组是逆序,运行时间是n的二次函数。
1.2 核心代码
public void sort(){int temp;for(int i = 1; i<arraytoSort.length; i++){for(int j = i-1; j>=0; j--){if( arraytoSort[j+1] < arraytoSort[j] ){temp = arraytoSort[j+1];arraytoSort[j+1] = arraytoSort[j];arraytoSort[j] = temp;} } }}2.选择排序
2.1 性能分析
时间复杂度O(n^2), 空间复杂度O(1)
排序时间与输入无关,最佳情况,最坏情况都是如此, 不稳定 如 {5,5,2}。
2.2核心代码
public void sort(){ for(int i = 0; i<arraytoSort.length-1; i++){int min = i;int temp;//find minfor(int j = i+1; j<arraytoSort.length ;j++){if(arraytoSort[j] <arraytoSort[min]){min = j;}}//swap the min with the ith elementtemp = arraytoSort[min];arraytoSort[min] = arraytoSort[i];arraytoSort[i] = temp;}}3. 归并排序
3.1 性能分析
时间复杂度 O(nlogn), 空间复杂度O(n) +O(logn)
排序时间与输入无关,最佳情况,最坏情况都是如此, 稳定。
原理:
可以将数组分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序
归并排序的时间复杂度,合并耗费O(n)时间,而由完全二叉树的深度可知,整个归并排序需要进行log_2n次,因此,总的时间复杂度为 O(nlogn),而且这是归并排序算法中最好、最坏、平均的时间性能。
由于归并排序在归并过程中需要与原始记录序列同样数量的存储空间存放归并结果 以及 递归时深度为 log_2n 的栈空间,因此空间复杂度为O(n+logn)。
另外,对代码进行仔细研究,发现 Merge 函数中有if (L[i]<R[j]) 语句,这就说明它需要两两比较,不存在跳跃,因此归并排序是一种稳定的排序算法。
也就是说,归并排序是一种比较占用内存,但却效率高且稳定的算法。
3.2 核心代码
public int merge( int p, int q, int r ){int count = 0;int[] right = assignlist(p,q); //赋值左半部分数组(赋值就是用for循环,还有一个哨兵:最后一个元素设置为maxvalue)int[] left = assignlist(q+1,r); //赋值有半部分数组int i = 0;int j = 0;for(int k = p; k<=r; k++){if(right[i] <= left[j]){ arraytoSort[k] = right[i];i++; }else if(right[i] > left[j]){arraytoSort[k] = left[j];j++;count = count + (q - p + 1) -i;}}return count;}void MergeSort(int arry[],int start,int end){if(start<end){int mid=(start+end)/2;//数组重点MergeSort(arry,start,mid);//递归调用,排序前半段arry[start...mid]MergeSort(arry,mid+1,end);//递归调用,排序后半段arry[mid+1,end]MergeArry(arry,start,mid,end);//归并上述两段有序数组。}}3.3 延伸
求逆序对
4. 冒泡排序
4.1 性能分析
时间复杂度O(n^2), 空间复杂度O(1), 稳定,因为存在两两比较,不存在跳跃。
排序时间与输入无关,最好,最差,平均都是O(n^2)
4.2 核心代码
for(int i=0;i<arraytoSort.length-1;i++){ for(int j=arraytoSort.length-1;j>=i+1;j--){int temp;if(arraytoSort[j]<arraytoSort[j-1]){temp = arraytoSort[j];arraytoSort[j] = arraytoSort[j-1];arraytoSort[j-1] = temp;}}
}4.3 延伸
冒泡排序缺陷:
在排序过程中,执行完当前的第i趟排序后,可能数据已全部排序完备,但是程序无法判断是否完成排序,会继续执行剩下的(n-1-i)趟排序。解决方法: 设置一个flag位, 如果一趟无元素交换,则 flag = 0; 以后再也不进入第二层循环。
当排序的数据比较多时排序的时间会明显延长,因为会比较 n*(n-1)/2次。
5. 堆排序
5.1 性能分析
时间复杂度 O(nlogn), 空间复杂度O(1). 从这一点就可以看出,堆排序在时间上类似归并,但是它又是一种原地排序,时间复杂度小于归并的O(n+logn)
排序时间与输入无关,最好,最差,平均都是O(nlogn). 不稳定
堆排序借助了堆这个数据结构,堆类似二叉树,又具有堆积的性质(子节点的关键值总小于(大于)父节点)
堆排序包括两个主要操作:
- 保持堆的性质
heapify(A,i)
时间复杂度O(logn) - 建堆
buildmaxheap(A)
时间复杂度O(n)线性时间建堆
对于大数据的处理: 如果对100亿条数据选择Topk数据,选择快速排序好还是堆排序好? 答案是只能用堆排序。 堆排序只需要维护一个k大小的空间,即在内存开辟k大小的空间。而快速排序需要开辟能存储100亿条数据的空间,which is impossible.
5.2 核心代码
public class HeapSort {public void buildheap(int array[]){int length = array.length;int heapsize = length;int nonleaf = length / 2 - 1;for(int i = nonleaf; i>=0;i--){heapify(array,i,heapsize);}}public void heapify(int array[], int i,int heapsize){int smallest = i;int left = 2*i+1;int right = 2*i+2;if(left<heapsize){if(array[i]>array[left]){smallest = left;}else smallest = i;}if(right<heapsize){if(array[smallest]>array[right]){smallest = right;}}if(smallest != i){int temp;temp = array[i];array[i] = array[smallest];array[smallest] = temp;heapify(array,smallest,heapsize);}}public void heapsort(int array[]){int heapsize = array.length;buildheap(array);for(int i=0;i<array.length-1;i++){// swap the first and the lastint temp;temp = array[0];array[0] = array[heapsize-1];array[heapsize-1] = temp;// heapify the arrayheapsize = heapsize - 1;heapify(array,0,heapsize);} }5.3 延伸
堆这种数据结构的很好的应用是 优先级队列,如作业调度。
6. 快速排序
6.1 性能分析
时间复杂度 O(nlogn) 空间复杂度O(logn) 不稳定 【两个时间复杂度O(nlogn) 的排序算法都不稳定】
时间复杂度:
最坏O(n^2) 当划分不均匀时候 逆序and排好序都是最坏情况
最好O(n) 当划分均匀
partition的时间复杂度: O(n)一共需要logn次partition
空间复杂度:递归造成的栈空间的使用,最好情况,递归树的深度logn 空间复杂的logn,最坏情况,需要进行n‐1 递归调用,其空间复杂度为 O(n),平均情况,空间复杂度也为O(log2n)。
由于关键字的比较和交换是跳跃进行的,因此,快速排序是一种不稳定的排序方法。
快速排序的每一轮就是将这一轮的基准数归位,直到所有的数都归为为止,排序结束。(类似冒泡).
partition是返回一个基准值的index, index 左边都小于该index的数,右边都大于该index的数。
快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的都是 O(n^2),它的平均时间复杂度为 O(nlogn)。其实快速排序是基于 “二分” 的思想。
6.2 核心代码
public class Quicksort {public int partition(int A[], int begin, int end){int i = begin;int j = end;int q;int pivot = begin;int pivotnumber = A[pivot];while(i!=j){int temp;while(A[j]>pivotnumber && i<j){j--;}while(A[i]<=pivotnumber && i<j){i++;}temp = A[i];A[i] = A[j];A[j] = temp;}if(i == j){int temp;temp =A[pivot];A[pivot] = A[i];A[i] = temp; }return i;}public void sort(int A[], int begin,int end){if(begin<end){int q;q = partition(A,begin, end);sort(A,begin, q-1);sort(A,q+1,end);} }public static void main(String[] args) {int array[] = {8,7,1,6,5,4,3,2};Quicksort s = new Quicksort();s.sort(array, 0, 7);for(int i=0;i<array.length;i++){System. out.println("output " + array[i]);}}
}非比较排序: ,计数排序,基数排序,桶排序,时间复杂度能够达到O(n). 这些排序为了达到不比较的目的,对数据做了一些基本假设(限制)。如计数排序假设数据都[0,n] 范围内,且范围较小;基数排序假设数据都[0,n] 范围内;也是桶排序假设数据均匀独立的分布。
而且,非比较排序的空间要求比较高,用空间换取时间吧。当我们的待排序数组具备一些基数排序与桶排序要求的特性,且空间上又比较富裕时,桶排序与基数排序不失为最佳选择。
7. 计数排序
我们希望能线性的时间复杂度排序,如果一个一个比较,显然是不实际的,书上也在决策树模型中论证了,比较排序的情况为nlogn 的复杂度。既然不能一个一个比较,我们想到一个办法,就是如果在排序的时候就知道他的位置,那不就是扫描一遍,把他放入他应该的位置不就可以了。 要知道他的位置,我们只需要知道有多少不大于他不就可以了吗?
7.1 性能分析
最好,最坏,平均的时间复杂度O(n+k), 天了噜, 线性时间完成排序,且稳定。
优点:不需要比较函数,利用地址偏移,对范围固定在[0,k]的整数排序的最佳选择。是排序字节串最快的排序算法。
缺点:由于用来计数的数组的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。
7.2 核心代码
public int[] countsort(int A[]){int[] B = new int[A.length]; //to store result after sortingint k = max(A);int [] C = new int[k+1]; // to store tempfor(int i=0;i<A.length;i++){ C[A[i]] = C[A[i]] + 1;}// 小于等于A[i]的数的有多少个, 存入数组Cfor(int i=1;i<C.length;i++){C[i] = C[i] + C[i-1];}//逆序输出确保稳定-相同元素相对顺序不变for(int i=A.length-1;i>=0;i--){B[C[A[i]]-1] = A[i]; C[A[i]] = C[A[i]]-1;}return B;}7.3 扩展
请给出一个算法,使之对给定的介于 0到 k 之间的 n个整数进行预处理,并能在O(1) 时间内回答出输入的整数中有多少个落在 [a...b] 区间内。你给出的算法的预处理时间为O(n+k)。
分析:就是用计数排序中的预处理方法,获得数组 C[0...k],使得C[i]为不大于 i的元素的个数。这样落入 [a...b] 区间内的元素个数有 C[b]-C[a-1]。
计数排序的重要性质是他是稳定的。一般而言,仅当卫星数据随着被排序的元素一起移动时,稳定性才显得比较重要。而这也是计数排序作为基数排序的子过程的重要原因
8 基数排序
为什么要用基数排序 ?
计数排序和桶排序都只是在研究一个关键字的排序,现在我们来讨论有多个关键字的排序问题。
假设我们有一些二元组(a,b),要对它们进行以a 为首要关键字,b的次要关键字的排序。我们可以先把它们先按照首要关键字排序,分成首要关键字相同的若干堆。然后,在按照次要关键值分别对每一堆进行单独排序。最后再把这些堆串连到一起,使首要关键字较小的一堆排在上面。按这种方式的基数排序称为 MSD(Most Significant Dight) 排序。
第二种方式是从最低有效关键字开始排序,称为 LSD(Least Significant Dight)排序 。首先对所有的数据按照次要关键字排序,然后对所有的数据按照首要关键字排序。要注意的是,使用的排序算法必须是稳定的,否则就会取消前一次排序的结果。由于不需要分堆对每堆单独排序,LSD 方法往往比 MSD 简单而开销小。下文介绍的方法全部是基于 LSD 的。
通常,基数排序要用到计数排序或者桶排序。使用计数排序时,需要的是Order数组。使用桶排序时,可以用链表的方法直接求出排序后的顺序。

8.1 性能分析
时间复杂度O(n) (实际上是O(d(n+k)) d是位数)
8.2 核心代码
RADIX-SORT(A,d)for i = 1 to ddo use a stable sort to sort array A on digit i
8.3扩展
问题:对[0,n^2-1]的n 个整数进行线性时间排序。
思路 : 把整数转换为n进制再排序,每个数有两位,每位的取值范围是[0..n-1],再进行基数排序
http://blog.csdn.net/mishifangxiangdefeng/article/details/7685839
问题: 给定一个字符串数组,其中不同的串包含的字符数可能不同,但所有串中总的字符个数为 n。说明如何在 O(n) 时间内对该数组进行排序
9. 桶排序
桶排序的思想近乎彻底的分治思想。
桶排序假设待排序的一组数均匀独立的分布在一个范围中,并将这一范围划分成几个子范围(桶)。
然后基于某种映射函数f ,将待排序列的关键字 k 映射到第i个桶中 (即桶数组B 的下标i) ,那么该关键字k 就作为 B[i]中的元素 (每个桶B[i]都是一组大小为N/M 的序列 )。
接着将各个桶中的数据有序的合并起来 : 对每个桶B[i] 中的所有元素进行比较排序 (可以使用快排)。然后依次枚举输出 B[0]….B[M] 中的全部内容即是一个有序序列。
补充: 映射函数一般是 f = array[i] / k; k^2 = n; n是所有元素个数
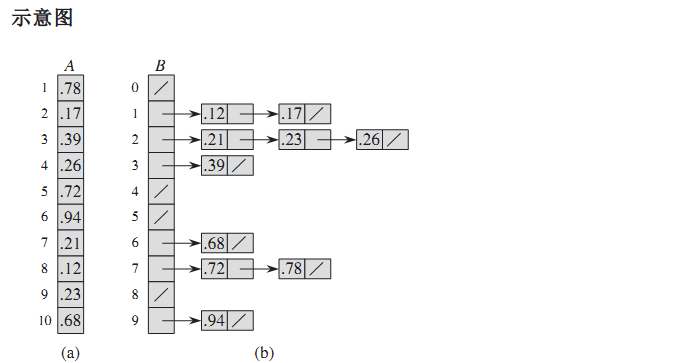
9.1 性能分析
平均时间复杂度为线性的 O(n+C) 最优情形下,桶排序的时间复杂度为O(n)。
桶排序的空间复杂度通常是比较高的,额外开销为O(n+m)(因为要维护 M 个数组的引用)。
就是桶越多,时间效率就越高,而桶越多,空间却就越大,由此可见时间和空间是一个矛盾的两个方面。
算法稳定性 : 桶排序的稳定性依赖于桶内排序。如果我们使用了快排,显然,算法是不稳定的。
一个讲bucket排序非常好的文章
桶排序利用函数的映射关系,减少了几乎所有的比较工作。实际上,桶排序的 f(k) 值的计算,其作用就相当于快排中划分,已经把大量数据分割成了基本有序的数据块 (桶)。然后只需要对桶中的少量数据做先进的比较排序即可。
对 N 个关键字进行桶排序的时间复杂度分为两个部分:
(1) 循环计算每个关键字的桶映射函数,这个时间复杂度是 O(n)。
(2) 利用先进的比较排序算法对每个桶内的所有数据进行排序,其时间复杂度为 ∑ O(ni*logni) 。其中 ni 为第 i个桶的数据量。
很显然,第 (2) 部分是桶排序性能好坏的决定因素。这就是一个时间代价和空间代价的权衡问题了。
9.2 核心代码
#include<iostream.h>
#include<malloc.h>typedef struct node{int key;struct node * next;
}KeyNode;void inc_sort(int keys[],int size,int bucket_size){KeyNode **bucket_table=(KeyNode **)malloc(bucket_size*sizeof(KeyNode *));for(int i=0;i<bucket_size;i++){bucket_table[i]=(KeyNode *)malloc(sizeof(KeyNode));bucket_table[i]->key=0; //记录当前桶中的数据量bucket_table[i]->next=NULL;}for(int j=0;j<size;j++){KeyNode *node=(KeyNode *)malloc(sizeof(KeyNode));node->key=keys[j];node->next=NULL;//映射函数计算桶号int index=keys[j]/10;//初始化P成为桶中数据链表的头指针KeyNode *p=bucket_table[index];//该桶中还没有数据if(p->key==0){bucket_table[index]->next=node;(bucket_table[index]->key)++;}else{//链表结构的插入排序while(p->next!=NULL&&p->next->key<=node->key)p=p->next; node->next=p->next;p->next=node;(bucket_table[index]->key)++;}}//打印结果for(int b=0;b<bucket_size;b++)for(KeyNode *k=bucket_table[b]->next; k!=NULL; k=k->next)cout<<k->key<<" ";cout<<endl;
}void main(){int raw[]={49,38,65,97,76,13,27,49}; int size=sizeof(raw)/sizeof(int); inc_sort(raw,size,10);
}9.3扩展

in summary

关于稳定性:
选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,
冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
常用时间复杂度的大小关系:O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(n^3)<O(2^n)<O(n!)<O(n^n)
这篇关于常用排序算法分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




