本文主要是介绍掌握 Redis 数据冗余:主从服务器的角色与职责,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
掌握 Redis 数据冗余:主从服务器的角色与职责
- 一 . 什么是主从复制
- 1.1 主从复制是什么 ?
- 1.2 什么是主从模式
- 1.3 主从复制能够解决的问题
- 二 . 配置主从复制
- 2.1 启动多个 redis-server
- 2.2 配置主从模式
- 2.3 查看主从结构信息
- 2.4 断开 / 临时修改主从结构
- 三 . 主从复制的补充内容
- 3.1 安全性、只读、传输延时
- 安全性
- 只读
- 传输延迟
- 3.2 主从复制的拓扑结构
- 3.3 主从复制的基本流程
- replicationid 的作用
- offset 的作用
- psync 的执行流程
- 3.4 全量复制和部分复制
- 3.5 实时复制
- 3.6 从节点什么情况下会自动升级成主节点
- 四 . 小结
Hello , 大家好 , 这个专栏给大家带来的是 Redis 系列 ! 本篇文章给大家讲解的是 Redis 的主从复制机制 . Redis 主从复制是一种重要的数据冗余机制 , 它允许多个从服务器(slaves)精确地复制主服务器(master)的数据 . 那具体什么叫做主服务器 , 什么叫做从服务器 ? 我们可以一起研究一下 .
本专栏旨在为初学者提供一个全面的 Redis 学习路径,从基础概念到实际应用,帮助读者快速掌握 Redis 的使用和管理技巧。通过本专栏的学习,能够构建坚实的 Redis 知识基础,并能够在实际学习以及工作中灵活运用 Redis 解决问题 .
专栏地址 : Redis 入门实践

一 . 什么是主从复制
1.1 主从复制是什么 ?
在分布式系统中 , 涉及到一个非常关键的问题 : 单点问题 , 如果某个服务器只有一个节点 (也就是说只搞一个物理服务器来部署服务器程序) , 那这样的话就可能会遇到一些困难
- 可用性问题 : 如果这个机器挂了 (比如 : 服务器内存过载、服务器硬盘已满 …) , 那就意味着这个服务就中断了 , 无法给其他服务提供支持
- 性能 / 支持的并发量也是有限的 : 一个服务器处理请求 , 每个请求都需要消耗一定的硬件资源 (CPU、内存、硬盘、网络带宽 …) , 那一台主机的硬件资源也是有限的 , 如果消耗的硬件资源超过了主机能够提供的硬件资源 , 那么就会导致主机出现一些异常情况
那引入分布式系统 , 主要也是为了解决单点问题 .
而在分布式系统中 , 往往希望有多个服务器来部署 Redis 服务 , 从而构成一个 Redis 集群 , 此时就可以让这个集群来给整个分布式系统中其他的服务提供更加高效更加稳定的数据存储功能
在分布式系统中 , 存在以下几种 Redis 的部署方式
- 主从模式
- 主从 + 哨兵模式
- 集群模式
我们先了解一下主从模式
1.2 什么是主从模式
在若干个 Redis 节点中 , 分为主节点和从节点 .
比如我们有三个物理服务器 (叫做三个节点) , 分别部署了 redis-server 进程 , 此时就可以把其中的一个节点 , 作为主节点 , 另外的两个节点作为从节点 .
从节点的数据要跟随主节点进行变化 , 从节点的数据要跟主节点保持一致 . (从节点就相当于主节点的副本)
❓ 如果我们修改了从节点的数据 , 是否需要把从节点的数据往主节点上同步呢 ?
✔️ 不可以
在 Redis 的主从模式中 , 从节点上面的数据 , 是不允许修改的 , 只能提供读取操作 .
1.3 主从复制能够解决的问题

那如果是单点模式 , 如果这个 Redis 服务器节点挂了 , 那整个 Redis 就都挂了 . 如果是上面的主从结构 , 那这些 Redis 的机器是很小可能性同时挂的 .
但是也有可能整个机房全挂了 (断电 / 断网 …) , 那为了考虑到更高的可用性 , 就可以把这些节点放到全国各地不同的机房中 , 这就是异地多活 .
如果我们只是挂了某个从节点 , 并不会造成什么影响 , 其他从节点继续从主节点中读取数据即可 .
但是如果挂掉了主节点 , 还是有一定影响的 , 从节点依然可以正常读数据 , 但是主节点并不能继续写入数据了 .
更严谨的说 , 主从模式主要是提升的 “读操作” , 来去提升高并发和高可用的要求 , 而写操作的话 , 无论是高并发还是高可用 , 都非常依赖主节点 , 但是主节点只能有一个
主节点只能有一个的原因是当我们有多个主节点 , 那不同的主节点插入同一个数据 , 这样就会造成数据的冗余 , 不能确定哪个数据到底是我们真正需要的 [也就是一山不容二虎]
二 . 配置主从复制
2.1 启动多个 redis-server
既然要配置主从复制模式 , 那我们肯定需要启动多个 Redis 服务器 . 正常情况下 , 每个 Redis 服务器程序 , 都应该部署在各自单独的主机上 , 这才是真正的分布式 .
但是一般来说 , 我们每个人手里应该只有一个云服务器 , 所以我们只能这样操作 : 在一个云服务器主机上 , 运行多个 redis-server 进程 , 但是要保证多个 redis-server 的端口号是不同的 .
本来 redis-server 默认的端口号是 6379 , 那么我们配置新的 redis-server 就不能再使用 6379 了
那如何去指定 redis-server 的端口呢 ?
- 可以在启动程序的时候 , 通过命令行来去指定端口号
- 在配置文件中 , 设定端口号
我们选择第二种方式
首先 , 我们在我们的根目录创建一个文件夹 , 叫做 redis-conf
cd / # 进入到根目录
mkdir redis-conf # 创建 redis-conf 文件夹

然后进入到该文件夹 , 使用 cd redis-conf 命令

接下来 , 我们就需要创建多份配置文件了
将原来的 Redis 的配置文件拷贝过来
# 将 redis.conf 复制过来 , 然后重命名为 slave1.conf / slave2.conf
cp /etc/redis/redis.conf ./slave1.conf
cp /etc/redis/redis.conf ./slave2.conf
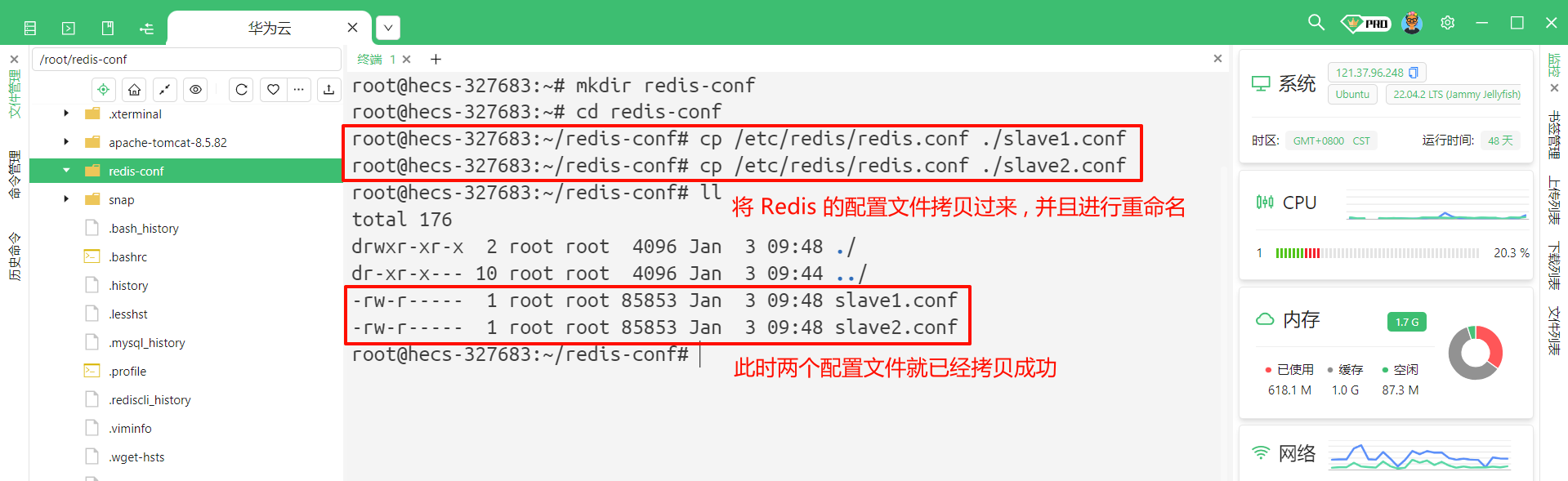
这样的话我们就已经有了一个主节点和两个从节点 , 主节点的配置不用修改 , 我们只需要修改从节点的配置即可
使用 vim slave1.conf 和 vim slave2.conf 命令即可
我们需要修改两个位置
端口号 : 修改成 6380


daemonize 修改成 yes (有的电脑上直接就是 yes) , 它的作用是让 redis-server 能够在后台运行
直接在底部输入 /daemonize 就可以进行搜索
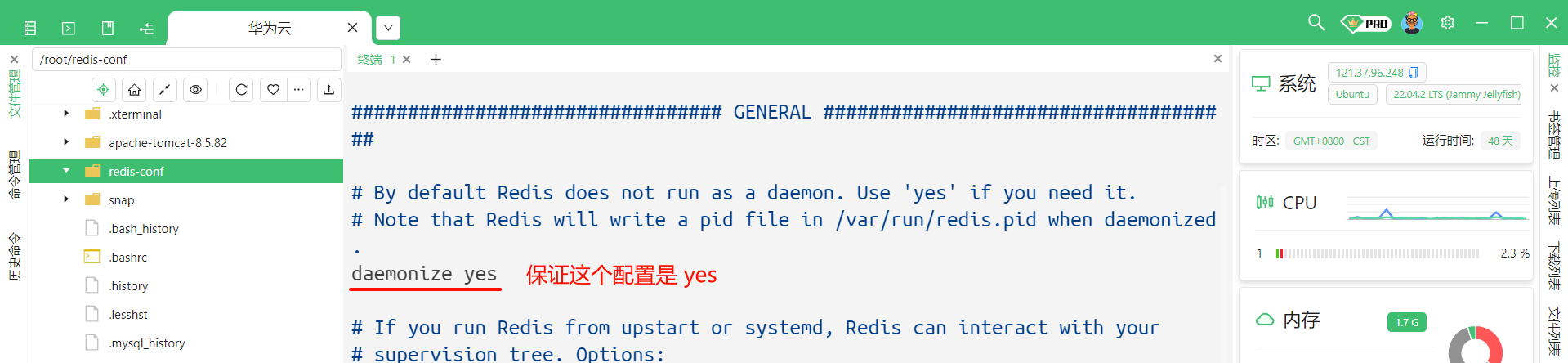
此时 , 我们就可以通过在启动 Redis 服务端的时候 , 在后面追加配置文件参数就可以达到启动多个服务器的效果了
# 启动多个 redis-server
root@hecs-327683:~/redis-conf# redis-server ./slave1.conf
root@hecs-327683:~/redis-conf# redis-server ./slave2.conf
root@hecs-327683:~/redis-conf# ps -aux | grep redis-server
redis 3858927 0.1 0.5 67196 10048 ? Ssl Jan02 1:20 /usr/bin/redis-server 0.0.0.0:6379
root 3934457 0.1 0.3 67196 5776 ? Ssl 09:56 0:00 redis-server 0.0.0.0:6380 # slave1 已经启动
root 3934659 0.0 0.3 67196 5820 ? Ssl 09:56 0:00 redis-server 0.0.0.0:6381 # slave2 已经启动
root 3934871 0.0 0.1 6608 2284 pts/1 S+ 09:56 0:00 grep --color=auto redis-server
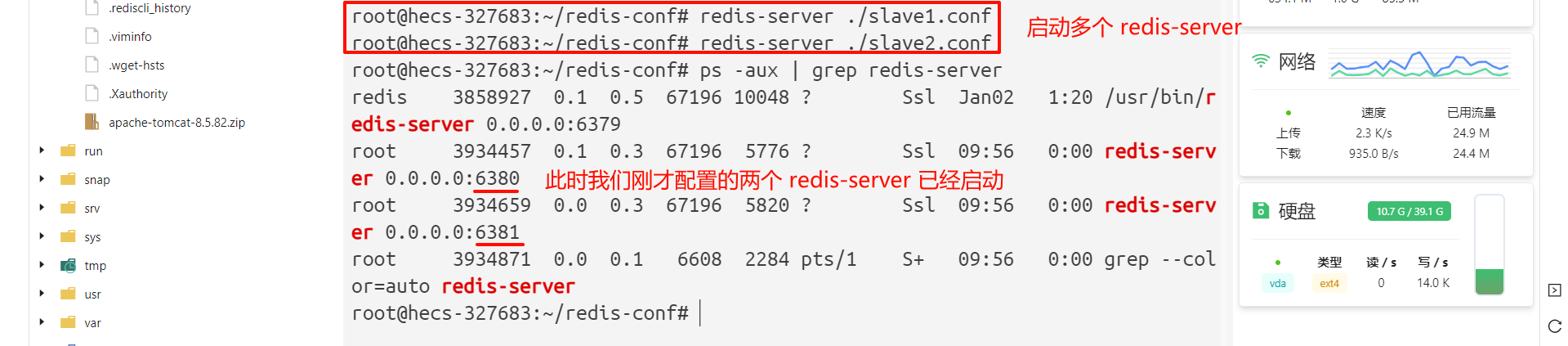
但是此时只是三个普通的 redis-server 节点 , 我们需要将他们进行绑定 , 形成主从模式
2.2 配置主从模式
要想配置成主从结构 , 就需要用到 slaveof
- 在配置文件中加入 slaveof {masterHost} {masterPort} , 然后 Redis 重启生效
- 在 redis-server 启动命令加入 --slaveof {masterHost} {masterPort}
- 直接使用 Redis 命令 : slaveof {masterHost} {masterPort}
我们依然选择使用配置文件的方式
分别使用 vim /root/redis-conf/slave1.conf 和 vim /root/redis-conf/slave2.conf
然后跳转到配置文件最底部 , 使用快捷键 Shift + G
然后添加这两行内容
# 主从结构的配置
slaveof 127.0.0.1 6379
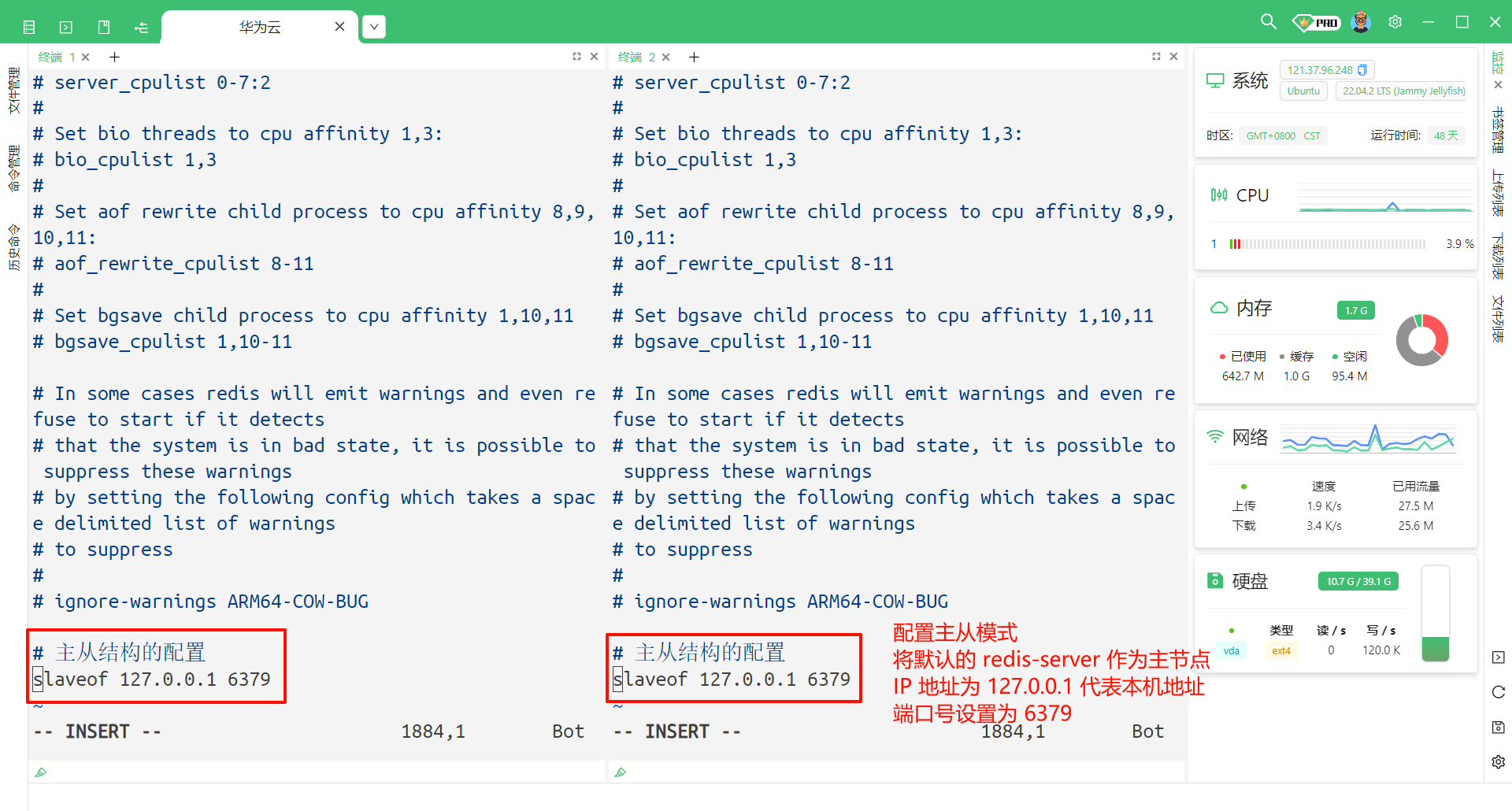
然后按 ESC 然后输入 :wq 进行保存
然后对 slave1 和 slave2 进行重启
使用 netstat -anp | grep redis 找到我们的进程 ID , 然后通过 kill -9 进程 ID 来去停止线程
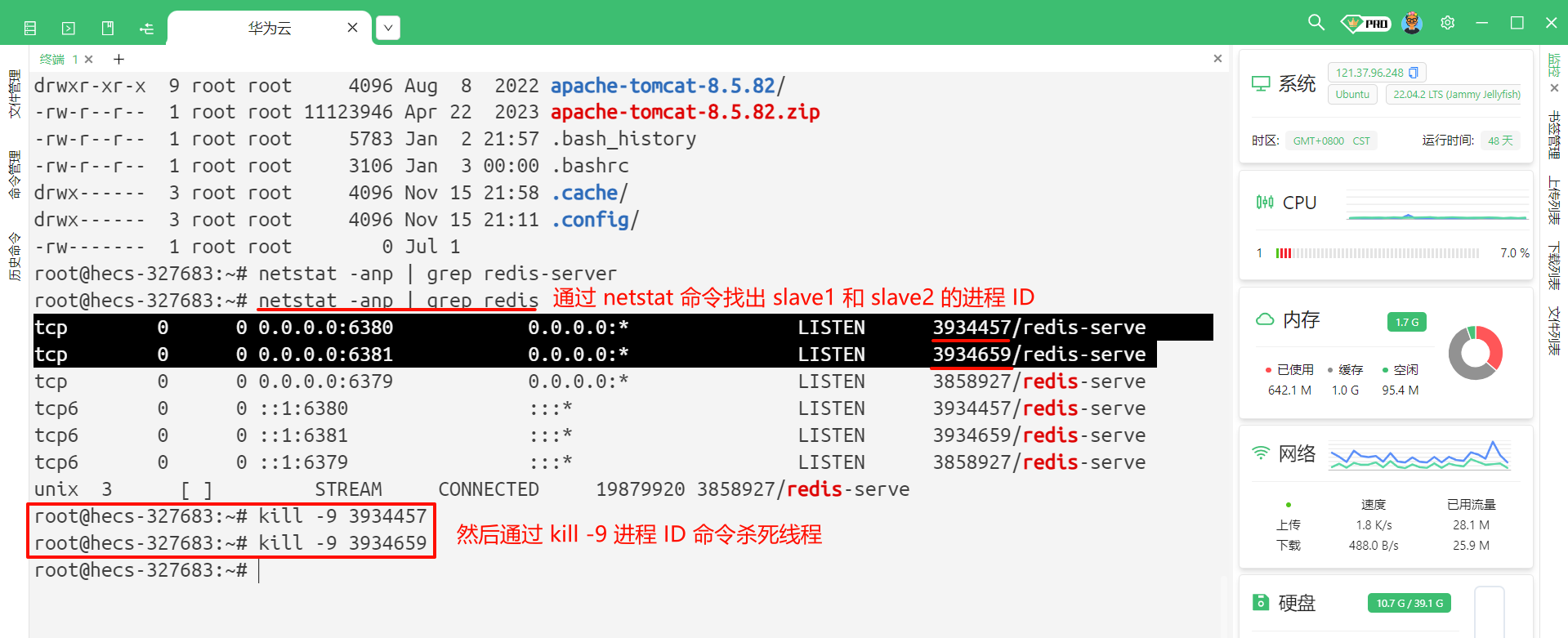
如果启动方式使用的是 redis-server 这种方式 , 那结束线程就需要使用 kill -9 进程 ID 这种方式来去停止线程
如果启动方式使用的是 service redis-server start 这种方式启动的 , 就必须使用 service redis-server stop 来去停止线程 , 如果使用 kill -9 进程 ID 这种方式杀死进程 , 那 redis-server 就会自动启动
然后我们重新运行 slave1 和 slave2
cd /root/redis-conf
redis-server ./slave1.conf
redis-server ./slave2.conf

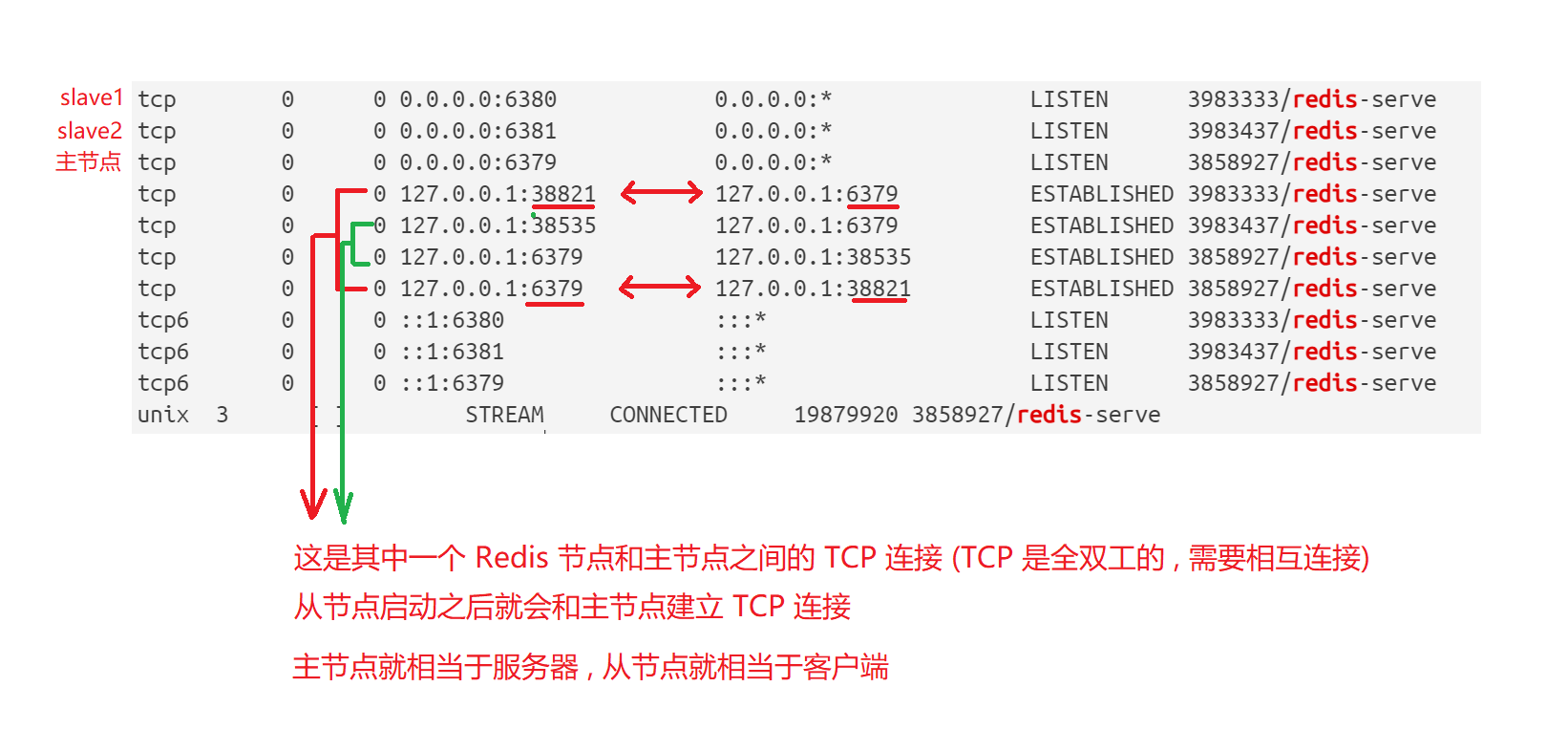
那这个时候我们就可以验证主从结构是否部署成功
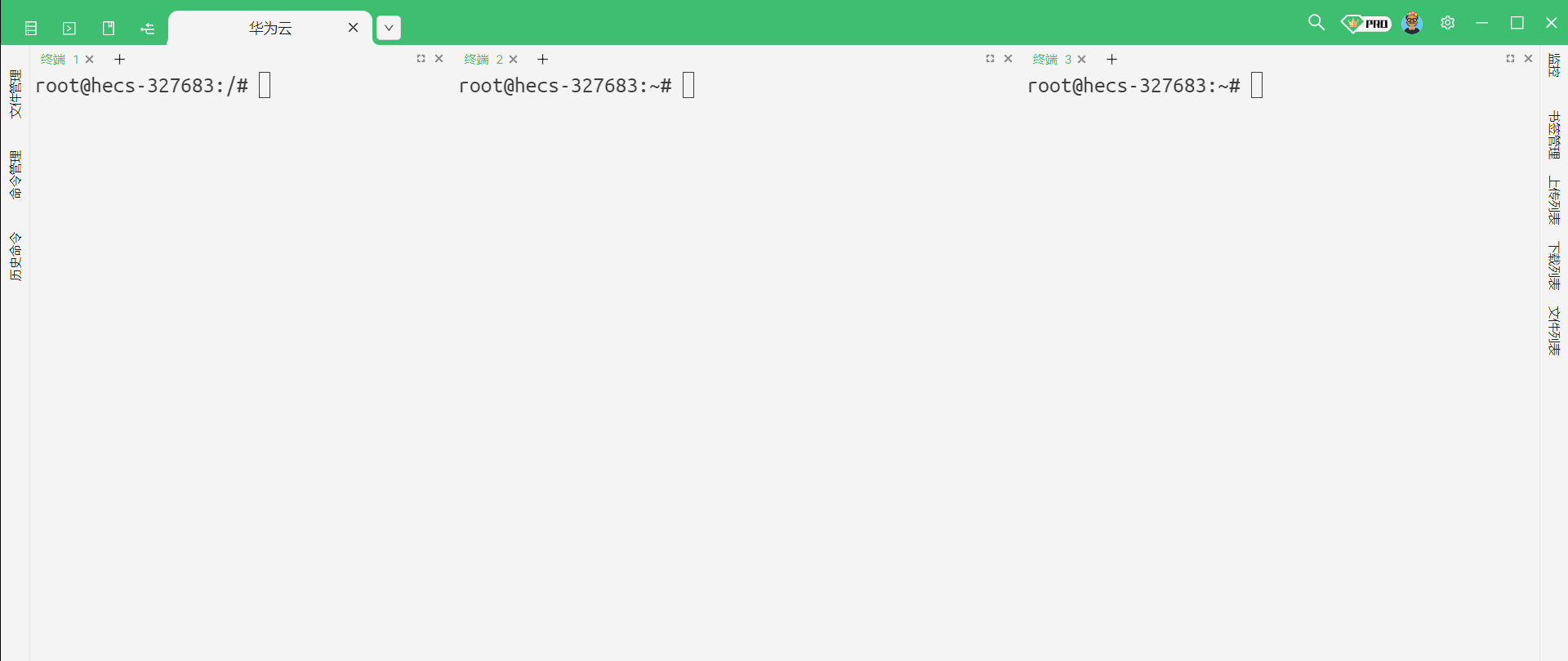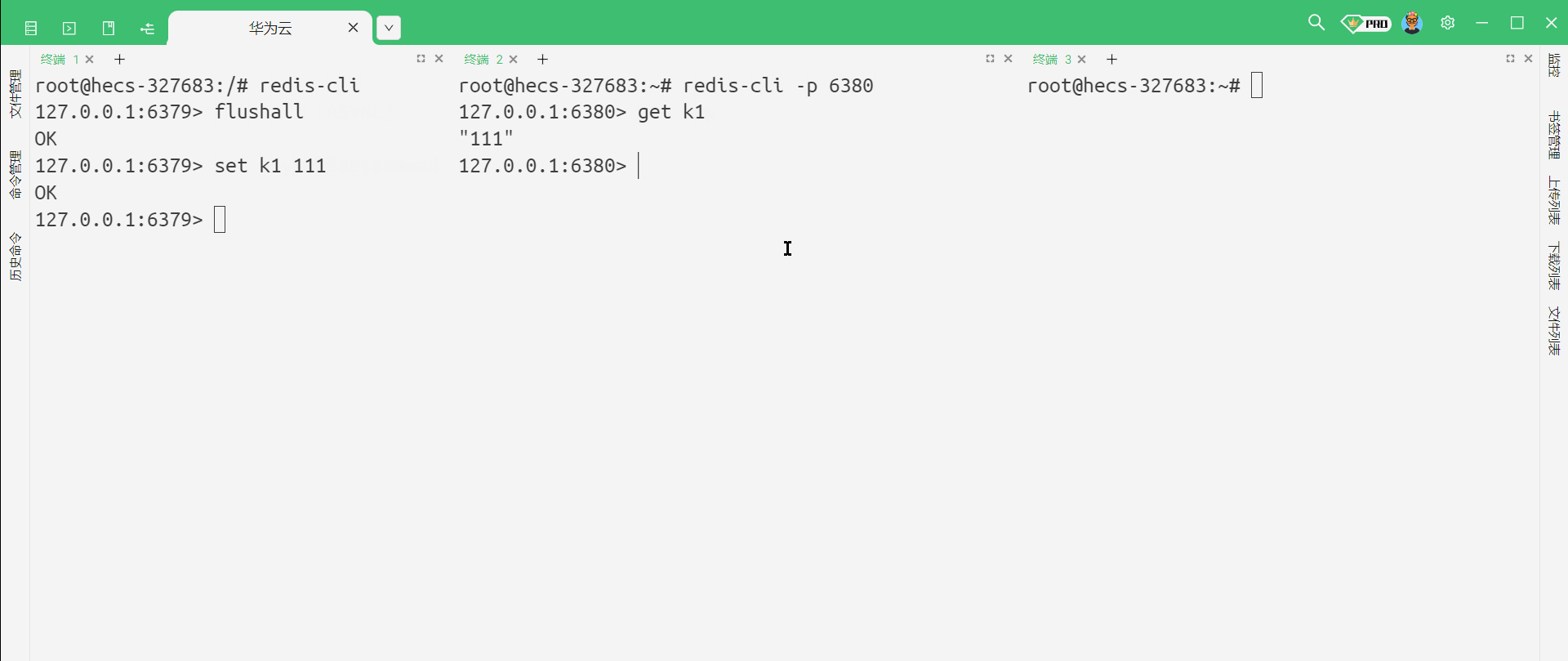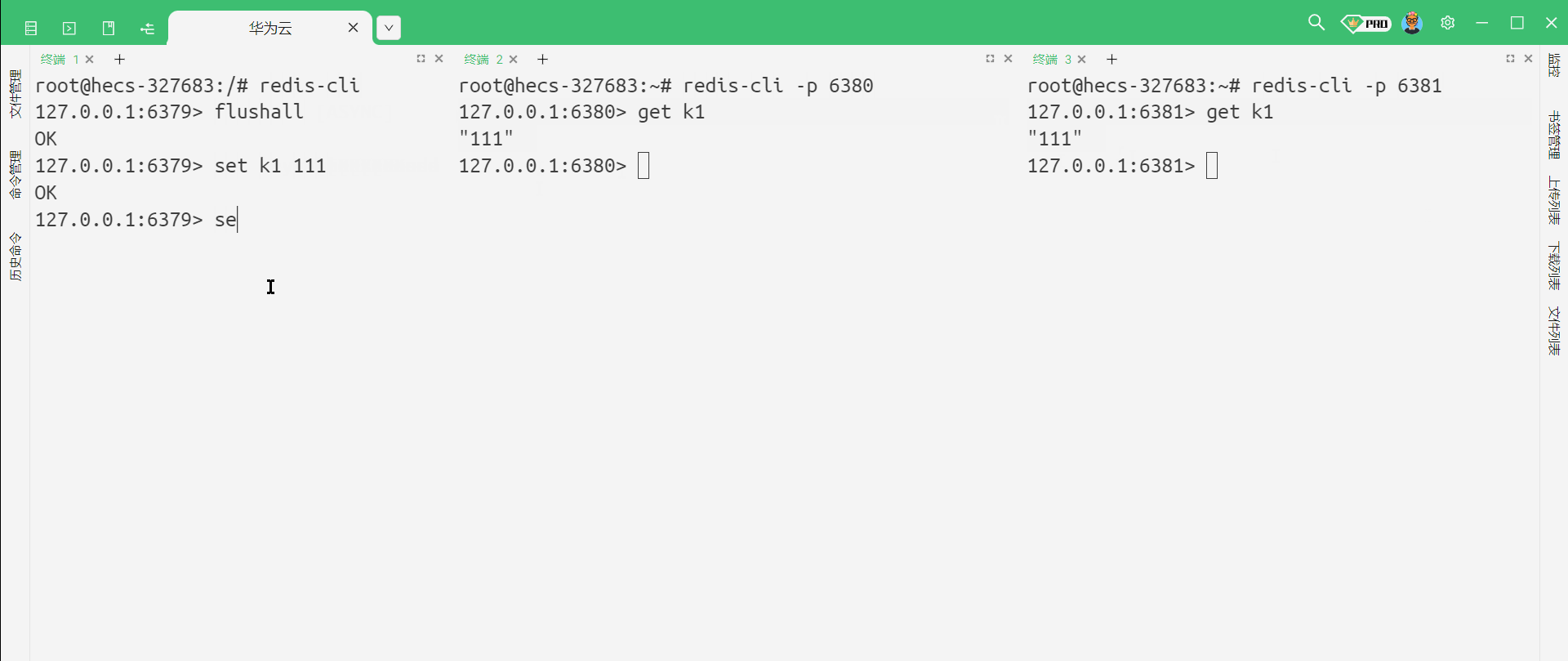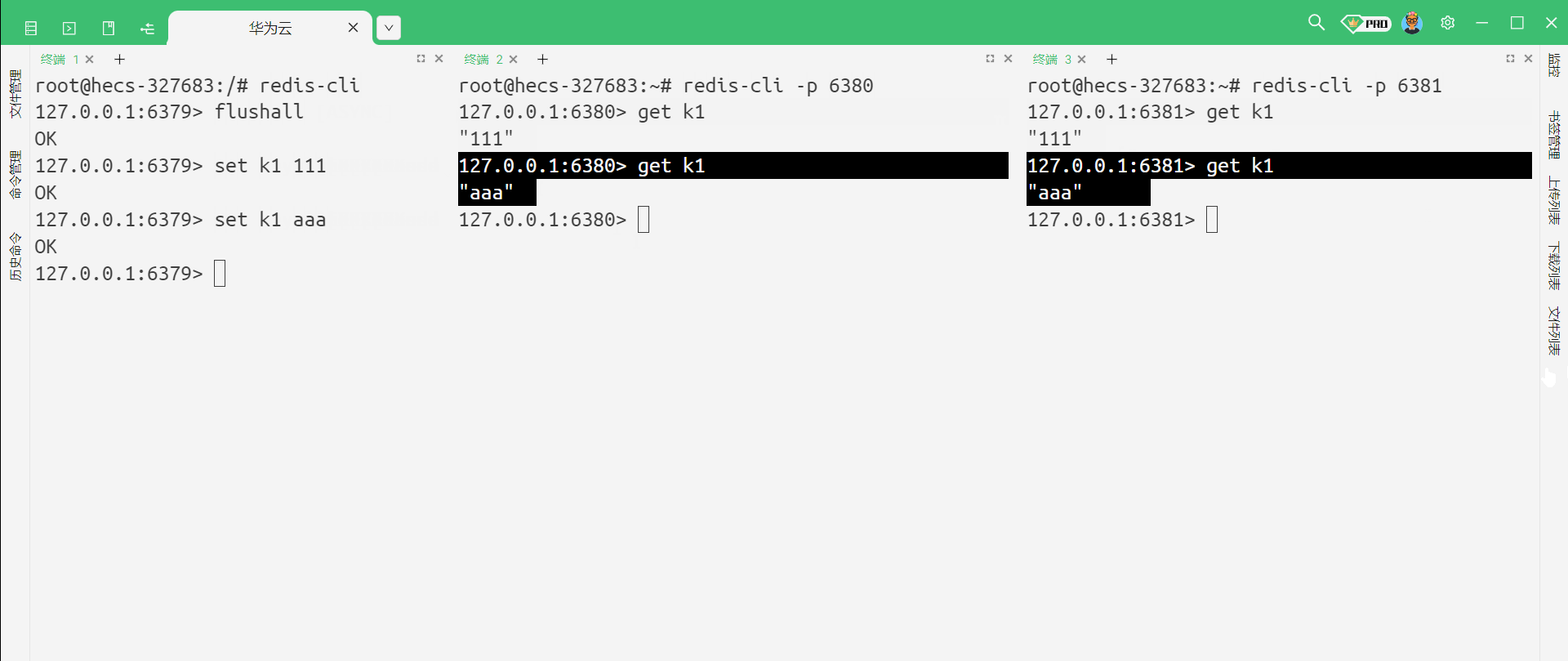
我们可以看到 , 主节点这边发生任何的修改 , 从节点就能够立即感知到
另外 , 从节点能否写入数据呢 ?

2.3 查看主从结构信息
我们刚才已经配置好了主从结构 , 并且已经验证了主节点可以写数据而从节点不能写数据 , 但是从节点可以读取数据这样的特性 .
那当我们建立好主从结构之后 , 我们也还可以通过命令来查看的 : info replication
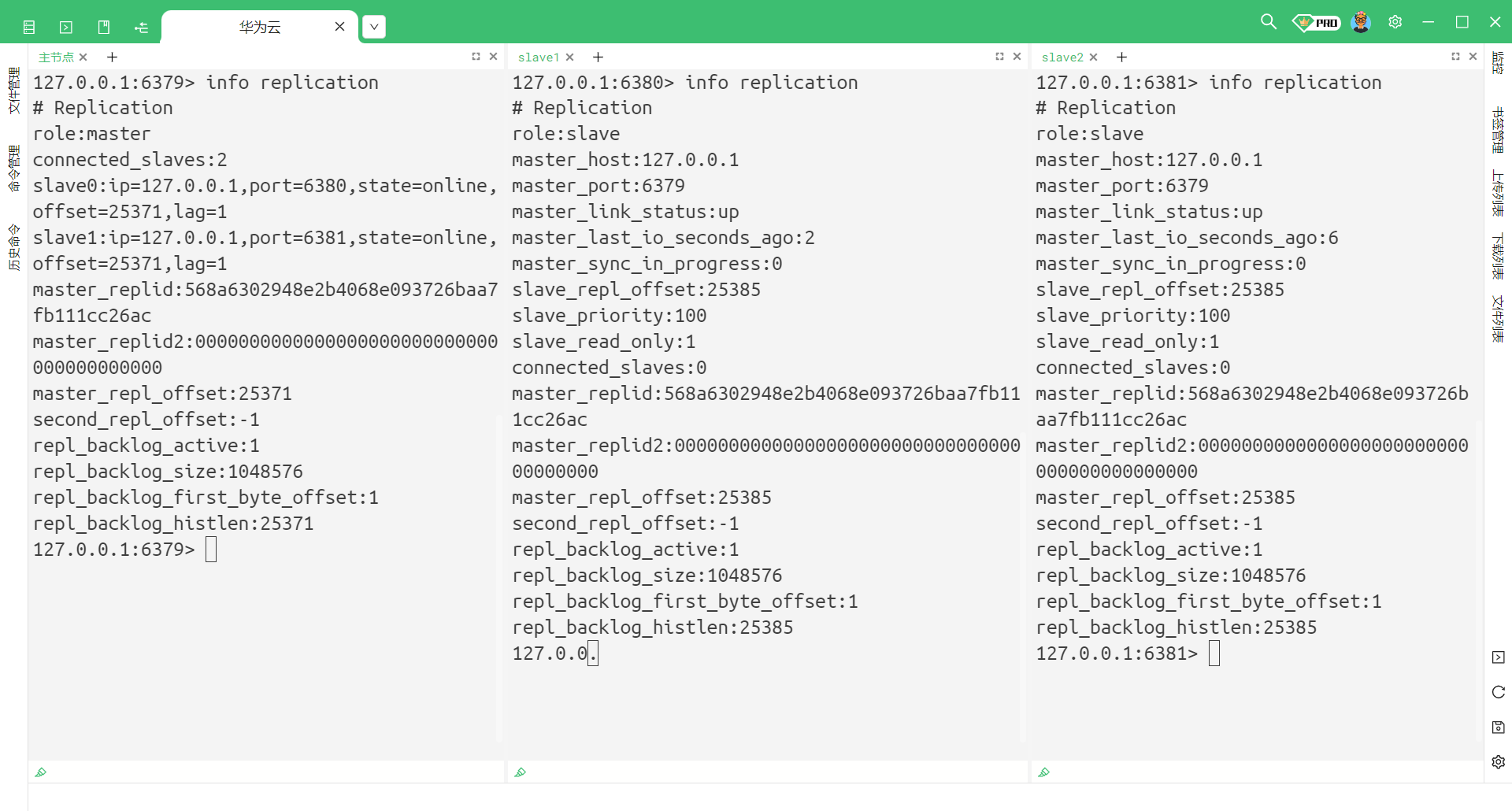
那我们分别来看
先来看主节点的相关信息

再来看一下从节点的相关信息

2.4 断开 / 临时修改主从结构
我们可以通过 slave no one 这个命令来去断开已有的主从复制关系 , 这个命令直接执行即可 , 不需要修改配置文件

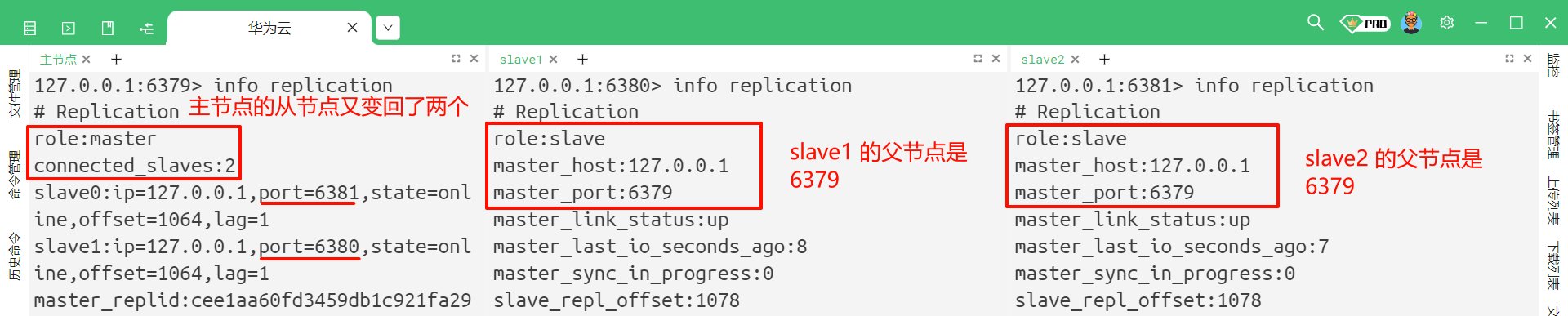
此时再去查看主节点的主从结构信息
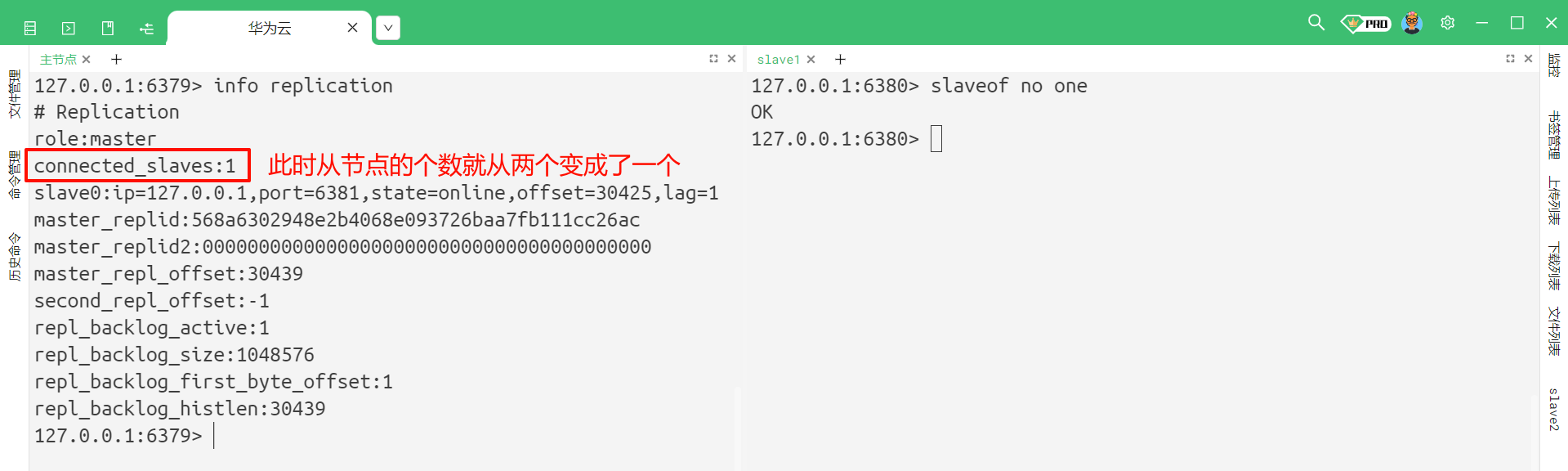
我们再来看一下从节点的主从结构信息

虽然从节点断开了主从关系 , 他就不在属于任何其他节点了 , 但是他之前保存的主节点的数据依然存在

但是后续主节点如果针对数据进行修改 , 从节点就无法再同步数据了
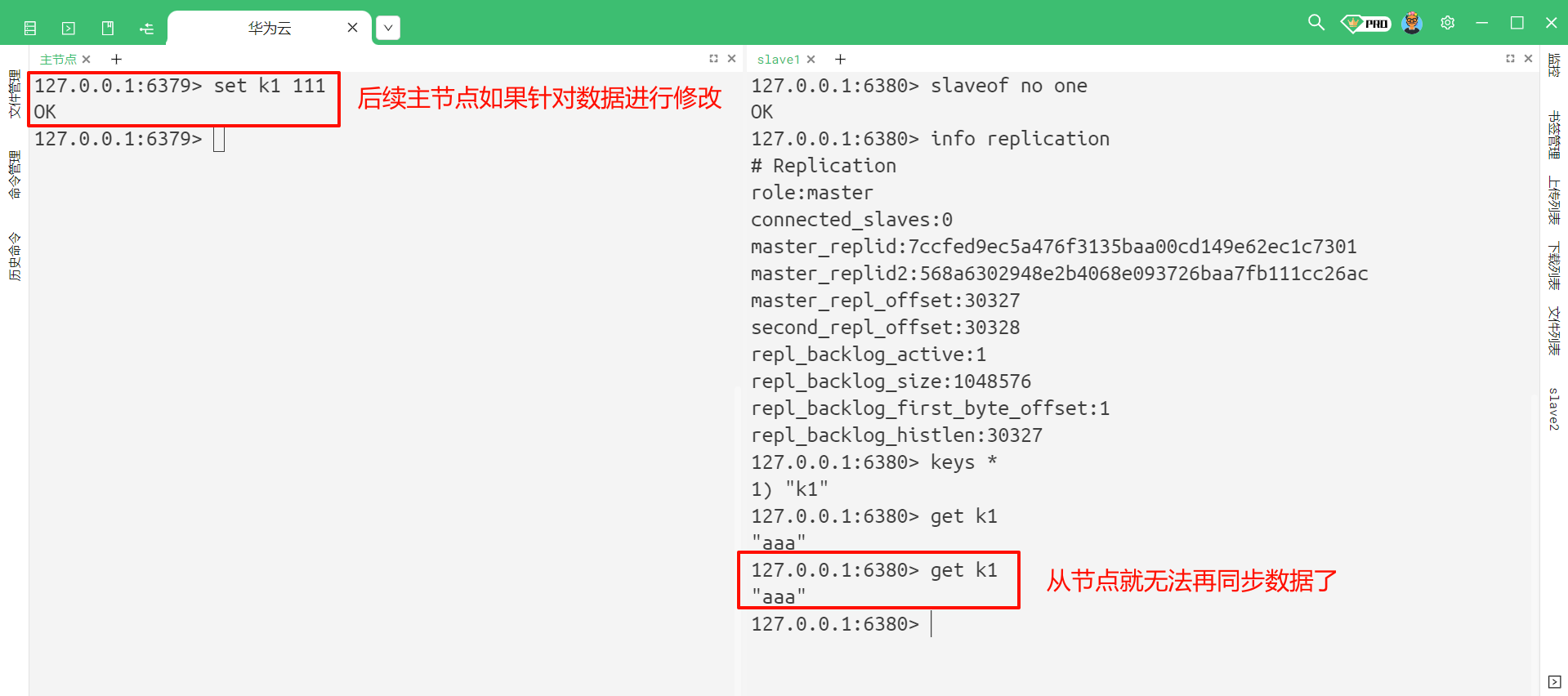
我们还可以使用 slave 这个命令让当前节点去投靠别的节点 [认贼作父] , 但是这种修改只是临时的 , 如果我们重新启动 Redis 整个服务器 , 他依然会按照配置文件中配置的主从关系来去配置
我们使用 slaveof 目标 IP 目标端口号 这个命令

此时 , 整条脉络就发生了变化
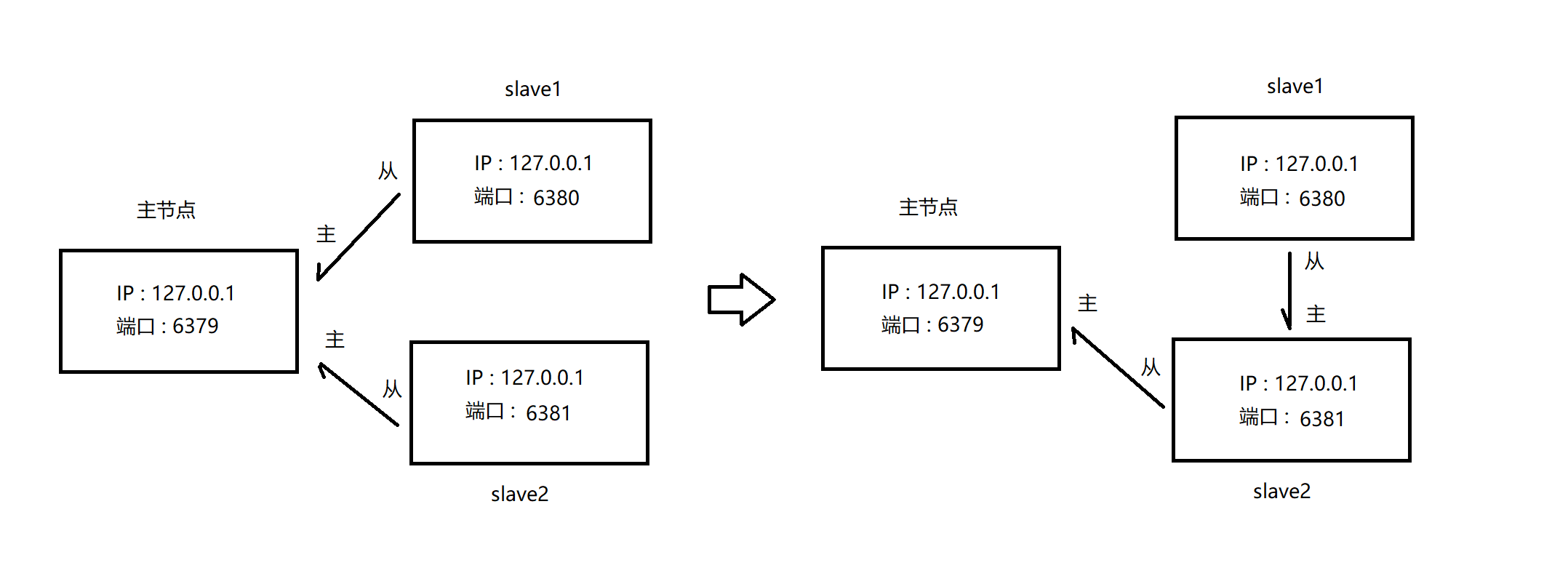
我们也可以通过 info replication 命令来去查看
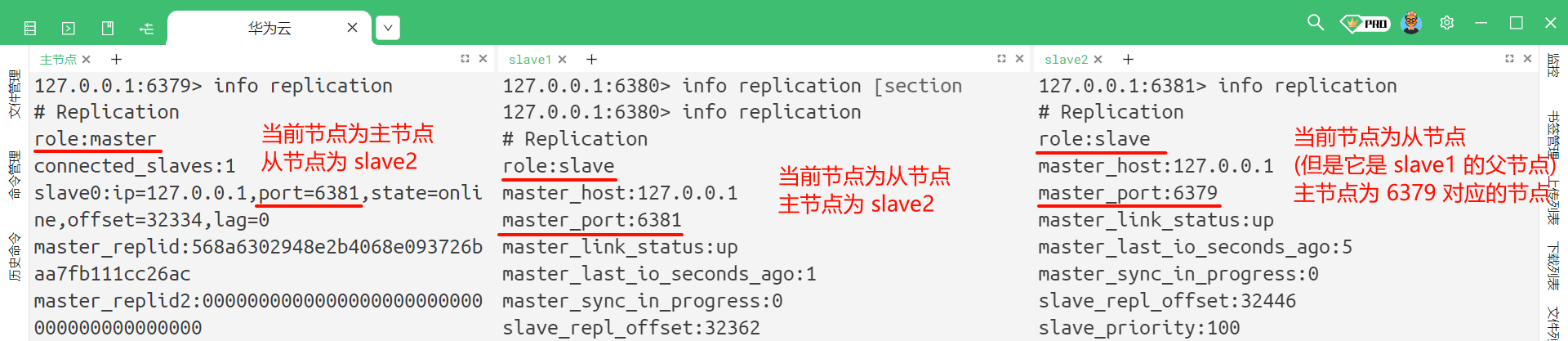
虽然此时 slave2 看起来是一个主节点 , 但是他实际上仍然是从节点 , 只是作为 slave1 同步数据的来源 , slave2 本身仍然是不能修改数据的
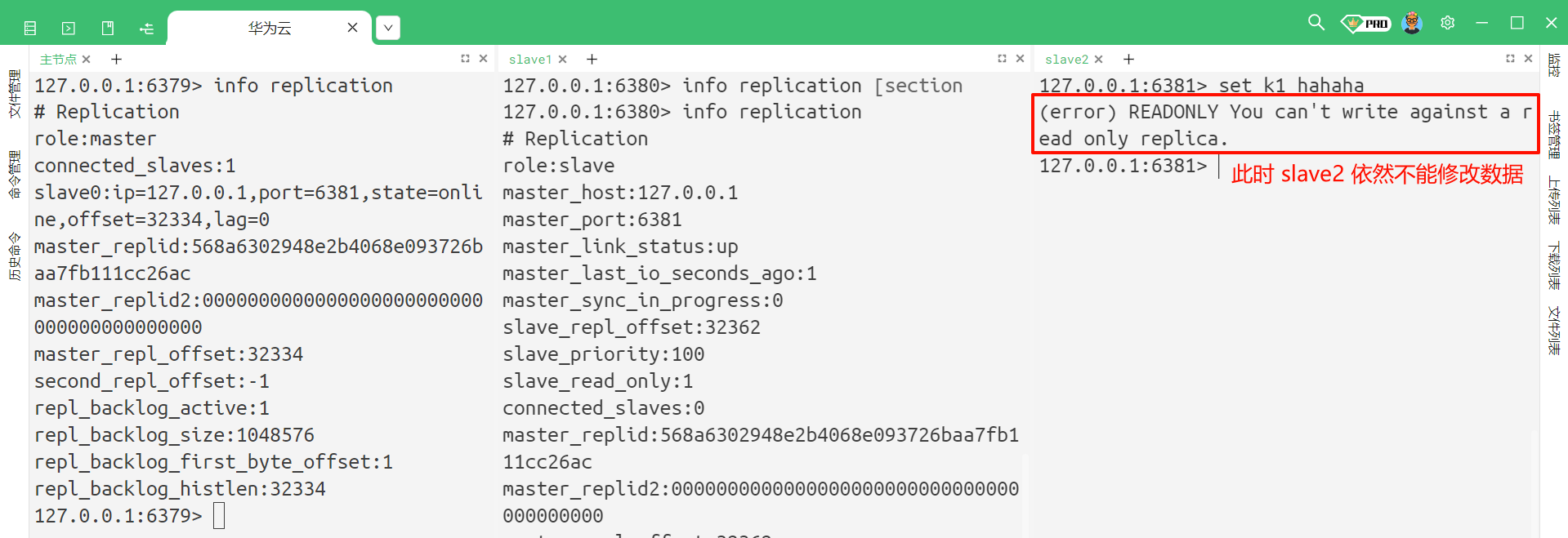
那我们重启一下服务器 , 看一下主从结构是否会恢复到配置文件中设置的情况

此时我们再来查看每个节点他所对应的主从结构信息
三 . 主从复制的补充内容
3.1 安全性、只读、传输延时
安全性
对于数据比较重要的节点 , 主节点可以在配置文件中通过设置 requirepass 参数进行设置密码 . 设置成功之后 , 所有的从节点都需要输入密码才能访问数据 .
同时 , 要求从节点也需要设置密码并且与主节点密码保持一致 , 才能够让从节点成功访问到主节点的数据 , 从节点也需要在配置文件中设置 masterpath 参数并且其密码要跟主节点一致 .
我们就不去配置了 , 很有可能给我们带来很多麻烦
只读
默认情况下 , 从节点不允许修改数据 .
但是我们可以在配置文件中修改 slave-read-only 这个参数为 no , 从节点就可以去修改数据了 , 但是这就违反了主从结构了 .
传输延迟
Redis 的主节点和从节点是通过网络 (TCP) 来进行数据传输的 , 只要是通过网络传输就会存在延迟 .
那 TCP 的底层设计支持 nagle 算法 , 如果开启就会增加 TCP 的传输延迟 , 然后节省了网络带宽 ; 如果关闭就会减少 TCP 的传输延迟 , 但是会增加网络带宽 .
一般情况下 , TCP 的 nagle 算法默认是开启的 , 他就类似于 TCP 的捎带应答机制 , 他会把一些小的 TCP 数据报进行合并 , 这样就减少了每次网络传输的包的个数次, 减少了封装和分用操作 .
一般来说及时性要求很高的游戏 , 就需要关闭 nagle 算法机制 .
在配置文件中 , 配置文件就提供了一个配置项 : repl-disable-tcp-nodelay , 这个选项可以用于在主从同步的通信过程中 , 关闭 TCP 的 nagle 算法 , 使从节点能够快速地和主节点进行同步 .
3.2 主从复制的拓扑结构
拓扑结构指的就是若干个节点之间 , 按照什么样的方式来进行组织和连接 .
在 Redis 中支持多种拓扑结构
- 一主一从结构 : 主节点和从节点存储的数据是一样的 , 主节点负责写数据 , 从节点负责读数据 , 但是从节点不能写数据

- 一主多从结构 : 在实际开发中 , 往往读请求是远远超过写请求的 , 所以还要进一步增强读请求的处理能力

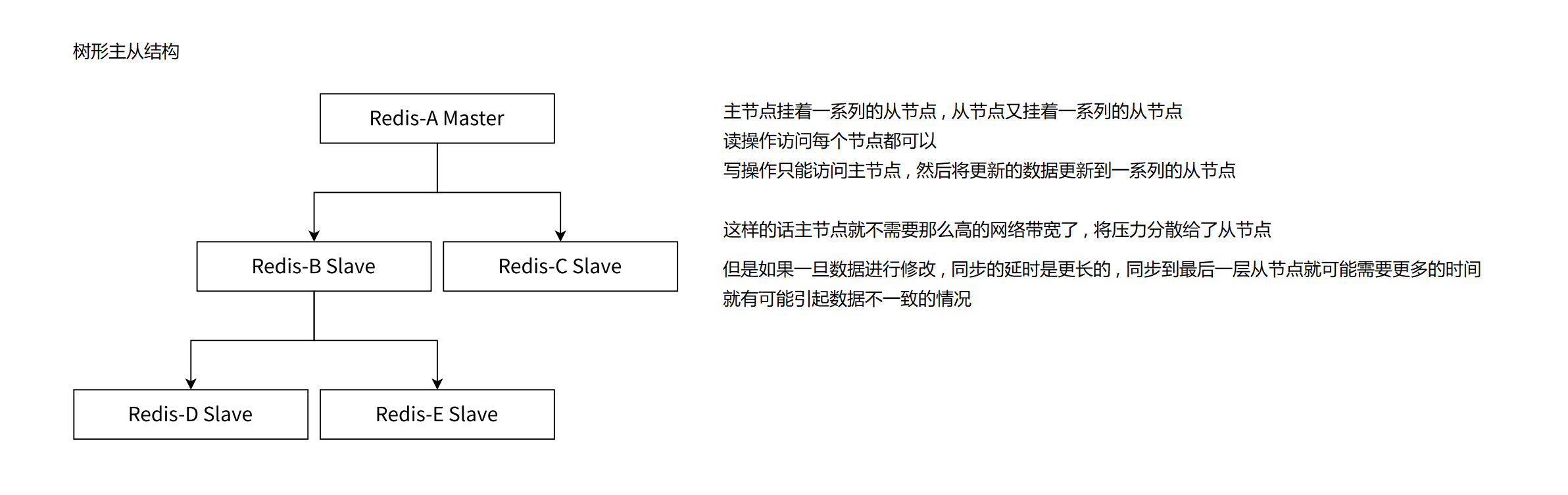
- 树形主从结构
3.3 主从复制的基本流程

我们重点关注数据同步的过程 , 也就是同步数据集和命令持续复制阶段
在 Redis 中 , 提供了一个 psync 命令来去同步数据 . 一般是从节点负责执行 psync , 也就是从节点负责从主节点拉取数据
psync 不需要我们手动执行 , Redis 服务器在建立好主从关系之后 , 会自动执行 psync
我们也可以手动输入 psync 命令 : psync replicationid offset , 我们来分析一下参数的含义
replicationid 的作用
replication 指的就是复制 , 那 replicationid 就是复制 ID 喽 . replicationid 是主节点在启动的时候就会生成的
即使是同一个主节点 , 每次重启生成的 replicationid 都是不一样的
可以通过 info replication 获取到当前 replicationid 的值

当从节点和主节点建立了复制关系 , 从节点就会从主节点这边获取到 replicationid , 来作为对应的身份标识 .
那我们也可以看到 , replid 有两个 , 那第二个 replid 是什么含义呢 ?

一般情况下 , replid2 是用不上的 , 只有在少数情况下会用到 .
比如 : 有一个主节点 A , 还有一个从节点 B . 主节点会生成 replid , 从节点就会获取到主节点的 replid , 如果 A 和 B 通信过程中出现了一些网络抖动 , 从节点就会认为主节点挂了 , 那从节点就会变身为主节点 , 然后自动生成 replid , 但是从节点也会记录之前的旧的 repllid , 这就是 replid2 .
后续网络稳定了 , 从节点 B 还可以根据 replid2 来去找到之前的主节点 A , 然后继续之前的主从复制 .
offset 的作用
offset 叫做偏移量 , 主节点和从节点都有维护这个偏移量
- 主节点上会收到很多修改命令 , 每个命令都需要占据几个字节 , 那主节点会把这些修改命令的字节数累加 , 就会得到一个不断变大的数字
- 从节点的偏移量指的是从节点的数据同步到哪里了
replicationid 和 offset 共同描述了一个数据集合 , replicationid 描述的是数据从哪个节点上同步 , offset 就表示同步的进度 . 如果发现两个机器的 replication id 一样 , offset 也一样 , 就可以认为这两个 Redis 机器上存储的数据就是完全一样的 .
psync 的执行流程

3.4 全量复制和部分复制
全量复制的流程

全量复制的无硬盘模式

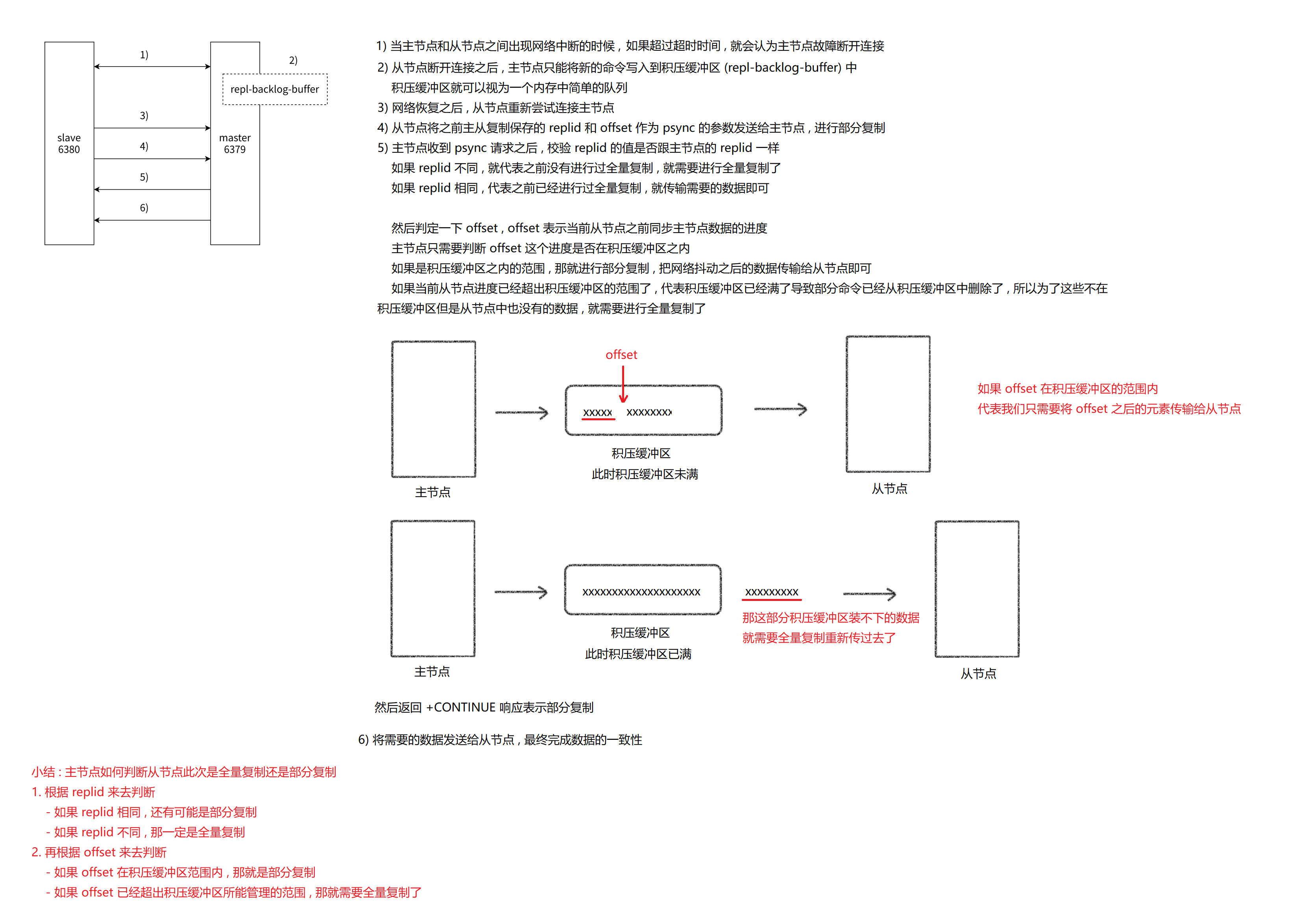
部分复制 : 从节点需要从主节点这里进行全量复制 , 那全量复制他的开销是很大的 . 但是有的时候从节点已经持有了主节点绝大部分数据 , 这个时候全量复制就不太适合了 .
部分复制一般出现在比如说网络抖动 , 主节点这边最近修改的数据可能就无法及时同步过来了 , 更严重的情况下从节点就感知不到主节点从而自动升级为主节点了 (但是网络抖动一般都是暂时的 , 几秒之后就能自动回复了) . 当从节点和主节点重新建立连接之后 , 就需要进行数据的同步 .
在最刚开始从节点全量获取主节点数据的时候 , 就已经获得了具体的 replid 和 offset 的值 , 那主节点就需要根据 psync 的 offset 参数来去进行判定当前这次复制是全量复制还是部分复制
3.5 实时复制
我们之前介绍过
- 全量复制 : 从节点刚开始连接上主节点之后 , 获取主节点全部数据的过程
- 部分复制 : 由于网络抖动等原因 , 导致从节点与主节点断开连接 . 等到再次连接的时候 , 从节点就需要获取丢失的数据 .
那实时复制是从节点已经和主节点同步好数据了 , 但是主节点之后也会不断收到一些新的数据 , 那就需要同步给从节点 . 从节点就需要和主节点之间建立 TCP 长连接 , 然后主节点就需要把收到的修改数据的请求通过 TCP 长连接发送给从节点 , 从节点再根据这些修改请求来去修改内存中的数据 .
那通过 TCP 长连接将数据同步给从节点这个过程也是需要时间的 . 正常来说这个延时是比较短的 , 但是如果是多层从节点 (树形主从结构) , 那延时就有可能很大 .
在实时复制的时候 , 需要始终保证连接处于可用状态 , 采用的是心跳包机制 .
- 主节点默认每 10s 就给从节点发送一个 ping 命令 , 从节点收到就会返回 pong . 如果 60s 还未收到 pong , 就会认为从节点下线
- 从节点默认每隔 1s 就会给主节点发送一个特定的请求 , 请求中就包含了当前从节点复制数据的进度 (也就是 offset)
3.6 从节点什么情况下会自动升级成主节点
从节点是否会自动升级成主节点 :
- 从节点主动和主节点断开连接 : 使用 slaveof no one 命令 , 这个时候从节点就能够晋升为主节点
- 主节点挂了 : 这个时候从节点不会自动晋升成主节点 , 必须通过人工干预的方式恢复主节点
四 . 小结
主从复制解决了单点问题 :
- 单个 Redis 节点可用性不高
- 单个 Redis 节点性能有限
主从复制的特点 :
- 通过 Redis 内部的复制功能实现主节点的多个副本
- 要求主节点用来写 , 从节点用来读 , 这样就降低了主节点的压力
- 支持多种拓扑结构 : 一主一从、一主多从、树形主从结构
- 复制分为全量复制、部分复制、实时复制
- 主节点和从节点通过心跳机制来验证主从节点是否正常连接
配置主从复制
- 主节点配置无需改动
- 从节点在配置文件中加入
slaveof 主节点IP 主节点端口
主从复制的缺点 : 从节点如果过多 , 就会存在非常高的延时性
主从复制的机制就给大家介绍完毕了 , 不知道你掌握多少呢 ? 不如先给个一键三连 ?

这篇关于掌握 Redis 数据冗余:主从服务器的角色与职责的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






