本文主要是介绍实时日志监控系统-全览,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大数据处理,大致可以分为两大模块:
- 离线数据处理:比如说电商、运营商出现的大批量的日志,可以由flume、sqoop或者其他路径,导入到HDFS中,然后经过数据清洗,使用Hive进行分析和处理,对于优化服务器资源等有很好的作用;个人觉得,支付宝的年账单就是离线数据处理的应用之处了。
- 实时数据处理:对于有些业务需要,可能第二天或者更晚的时候进行分析无关紧要,但对于一些高频的金融交易来说,实时性就太重要了,还有一些如百度搜索的top10,新浪微博的微博热点等等,如果等到第二天处理,那这些新闻也没什么吸引的价值了。
所以,纵观来说,离线数据处理和实时数据处理撑起了大数据处理的一片天,本文将介绍本人亲自负责并予以实施的日志监控项目,麻雀虽小,五脏俱全。
主要模块
- 日志收集模块
- 日志处理模块
主要工具
- flume:用于日志的收集,堪称是业内最好的日志收集工具,支持多种日志收集的渠道,同时支持诸多的日志收集存放地,功能强大;官方链接:flume官网
- kafka:消息缓冲队列,大数据处理中常用的缓冲队列,用于数据爆炸的时候,避免拖垮后续的处理逻辑,将消息先存放到队列中,延迟一定的时间进行处理。
- log4j:我们在Tomcat服务器上部署的业务系统,需要指定flume-appender,因此需要使用到log4j。
- SparkStreaming:在第一版本中,由于实时性不是很强,因此使用该工具予以处理,其处理日志会有一定的延迟,但吞吐量较大。
- MySql:用于读取配置数据,已经将配置数据全部迁移到zookeeper上。
- Spring boot:构建数据配置服务,方便用户配置自己的日志数据,比如邮件发给何人,短信发给何人,都可以自由指定。
- zookeeper:数据配置中心,在本项目用途中,主要是用于配置数据的管理,官方链接:zookeeper官网
1:日志收集模块
在日志收集模块中,针对我们自身的业务,可以分为两大部分:
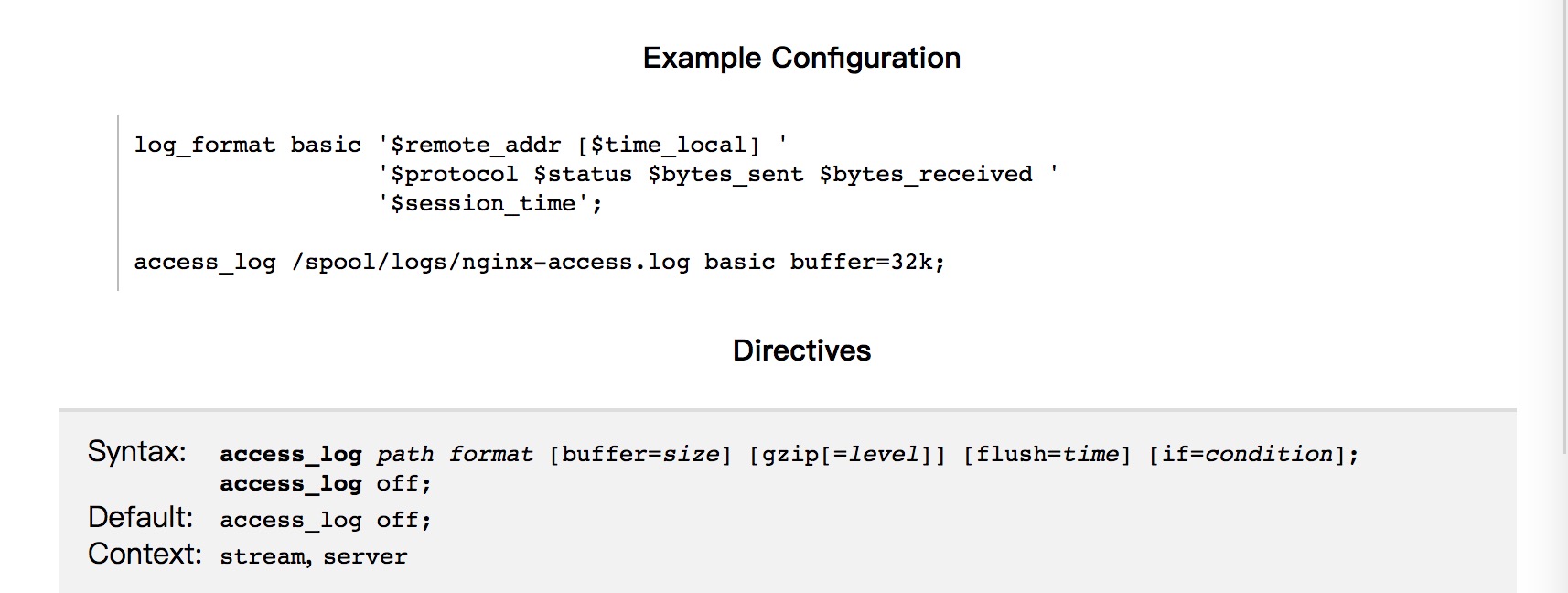
- Nginx日志和数据库运行日志:首先是Nginx,作为业内比较强大的负责均衡工具,其性能比较优良,我们在日常的服务中,也是使用该工具来进行负载均衡的功能实现;插播一句,业内另一比较强大的负载均衡工具是淘宝的章文嵩博士开发的LVS,对于访问量不是很大的网站,使用Nginx完全可以实现功能;为了能够准确处理出错的日志,我们对日志格式进行了一定的定义,类似下图:
- 对于Tomcat类型的服务,选择使用log4j内置的flume-appender方式来实现,具体配置可以参考官网:https://logging.apache.org/log4j/2.x/manual/appenders.html#FlumeAppender;其中有很详细的flume-appender配置,在日志中配置合理,每一条日志都会按照相应的格式,作为flume收集日志的来源。

对于收集到的日志,统一采用kafkaSink的方式,输送到后续的kafka中,以备后续的处理。
关于日志的收集,在处理过程中有几点收获:
- 对于flume的收集渠道有了更加深入的理解,flume不愧是强大的工具,支持的收集渠道非常多,而且支持的类型也很多,我们在收集nginx日志的时候,配置的type为exec,即命令执行方式,其会执行该命令,把需要监控的日志实时进行读取,配置如下:
a1.sources = r1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /var/log/secure a1.sources.r1.channels = c1
- 对于tail命令,支持同时读取多个日志文件,会统一把这些日志输送到同一个源,输送到目的地。
- 拦截器的使用:有时候,收集到的日志并不是完全如我们的意愿,这时候,拦截器就派上了用场,我们在plugins.d目录下,部署了自己的jar包,用于拦截读取到的日志,进行第二步骤的处理;而且拦截器支持链式,即多个拦截器会依次处理收集到的日志。
2:日志处理模块
对于收集到的日志的处理,我们采用的是Spark-Streaming工具,将其与kafka对接,对于收集到的每一条数据进行处理:
public void startTask() { //新建sparkConfSparkConf conf = new SparkConf().setAppName(ConfigUtils.SPARK_APPNAME);conf.setMaster("local[4]");// 本地多线程调用// conf.setMaster(ConfigUtils.SPARK_MASTER);//集群调用//制作StreamingContextJavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(Long.valueOf(ConfigUtils.SPARK_DURATIONS)));Map<String, String> kafaParameters = new HashMap<String, String>();//部署kafka机器的ip及端口号kafaParameters.put("metadata.broker.list", ConfigUtils.KAFKA_BROKER);//消费组的groupIdkafaParameters.put("group.id", ConfigUtils.KAFKA_GROUPID);kafaParameters.put("fetch.message.max.bytes", ConfigUtils.KAFKA_FETCH_MAX);kafaParameters.put("num.consumer.fetchers", ConfigUtils.KAFKA_FETCH_NUM);Set<String> topics = new HashSet<String>();topics.add(ConfigUtils.KAFKA_TOPIC);try {//指定直连,消费kafka某个topic内的数据JavaPairInputDStream<String, String> lines = KafkaUtils.createDirectStream(jsc, String.class, String.class,StringDecoder.class, StringDecoder.class, kafaParameters, topics);JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String, String>, String>() {public Iterator<String> call(Tuple2<String, String> tuple) throws Exception {// log.info("接收kafka数据:" + tuple._2);return Arrays.asList(tuple._2.split(SPACE.pattern())).iterator();}});words.foreachRDD(new VoidFunction2<JavaRDD<String>, Time>() {public void call(JavaRDD<String> word, Time arg1) throws Exception {// TODO Auto-generated method stubprocess(word);}});}catch(Exception e) {e.printStackTrace();}}这里,主要是将SparkStreaming与kafka对接起来的实现,需要指定消费组的group id,需要指定消费的topic,指定消费的机器,最重要的一步就是创建接下来需要进行处理的JavaRDD,其实,spark最核心的概念就是rdd的处理,其SparkStreaming,实际上处理的也就是一段时间内产生的RDD而已。
对于上述的代码中一些问题予以优化下:
try {JavaPairInputDStream<String, String> lines = KafkaUtils.createDirectStream(jsc, String.class, String.class,StringDecoder.class, StringDecoder.class,kafaParameters, topics);lines.foreachRDD(new VoidFunction<JavaPairRDD<String, String>>() {@Overridepublic void call(JavaPairRDD<String, String> t)throws Exception {t.foreachPartition(new VoidFunction<Iterator<Tuple2<String, String>>>() {@Overridepublic void call(Iterator<Tuple2<String, String>> t)throws Exception {while (t.hasNext()) {String res = t.next()._2;try {// 这里,很重要的一点是,到底要不要输出日志if (flag) {log.info("read kafka message:" + res);}process(res);} catch (Exception e) {log.info(res + "------处理异常------"+ getExeptionMessage(e));}}}});}});} catch (Exception e) {e.printStackTrace();}接下来的处理,则是对收集到的日志,进行自己的处理,在此处不予赘述。
项目总结:本项目其实难度并不大,重点在于拦截器的设置,kafka集群的搭建,后续处理的完善,以及如何形成spark与kafka数据的对接等方面。
这篇关于实时日志监控系统-全览的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






