本文主要是介绍冒泡排序算法及其简单优化(基于Java),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
冒泡排序算法通过多次比较和交换来实现排序,其流程如下: (1)对数组中的各数据,依次比较相邻两个元素的大小。
(2)如果前面的数据大于后面的数据,就交换这两个数据。通过第一轮的多次比较排序后,便可将最小的数据排好。
(3)再用同样的方法把剩下的数据逐个进行比较,最后便可按照从小到大的顺序排好数组的各数据。
所谓“冒泡”,就是大数沉下去(数组的底部),小数相应的浮上来(数组的顶部)。
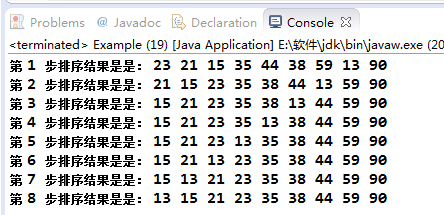
下面是程序呈现:
package 冒泡排序;public class Example {public static void main(String[] args) {int[] a = { 23, 35, 21, 15, 59, 44, 38, 90, 13 };int temp;for (int i = 1; i < a.length; i++) {for (int j = 0; j < a.length - i; j++) {/** 将两个相邻的数据进行比较,较大的数沉到底部*/if (a[j] > a[j + 1]) {//交换相邻两个数temp = a[j];a[j] = a[j + 1];a[j + 1] = temp;}}System.out.print("第 "+i+" 步排序结果是是: ");//输出每步排序结果for(int t=0;t<a.length;t++){System.out.print(a[t]+" ");}System.out.println();}}
}
时间复杂度和空间复杂度分析:
我们知道冒泡排序嵌套了两个for循环,我们令数据交换操作为基本操作,那么基本操作总共执行了(n-1)+(n-2)+……+1次,那么很容易得出其最差时间复杂度为O(n^2),空间复杂度为O(1)。
那么我们想对算法进行优化,就要在其最优时间复杂度上下功夫了,我们假设要排序的数组是由小到大排列好的,比如
int[] a={1,2,3,4,5,6,7,8,9};
那么程序自始至终都不符合if条件,也就是在for循环上空转,这样一来就浪费了时间和资源,好了,我们可以这样优化:
package 冒泡排序;public class Example {public static void main(String[] args) {int[] a = { 1,2,3,4,5,6,7,8,9 };int temp;boolean judge=true;for (int i = 1; judge==true&&i < a.length; i++) {for (int j = 0; j < a.length - i; j++) {/** 将两个相邻的数据进行比较,较大的数沉到底部*/judge=false;if (a[j] > a[j + 1]) {judge=true;//交换相邻两个数temp = a[j];a[j] = a[j + 1];a[j + 1] = temp;}}System.out.print("第 "+i+" 步排序结果是是: ");//输出每步排序结果for(int t=0;t<a.length;t++){System.out.print(a[t]+" ");}System.out.println();}}
}

在第一层for循环的循环条件里加上一个judge判断标记,当给出的数组顺序已排列完成时便不再继续执行下去。这样算法便得到一定优化。
有关时间复杂度和空间复杂度的问题,可以参阅博客
常用算法的时间复杂度和空间复杂度
这篇关于冒泡排序算法及其简单优化(基于Java)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






