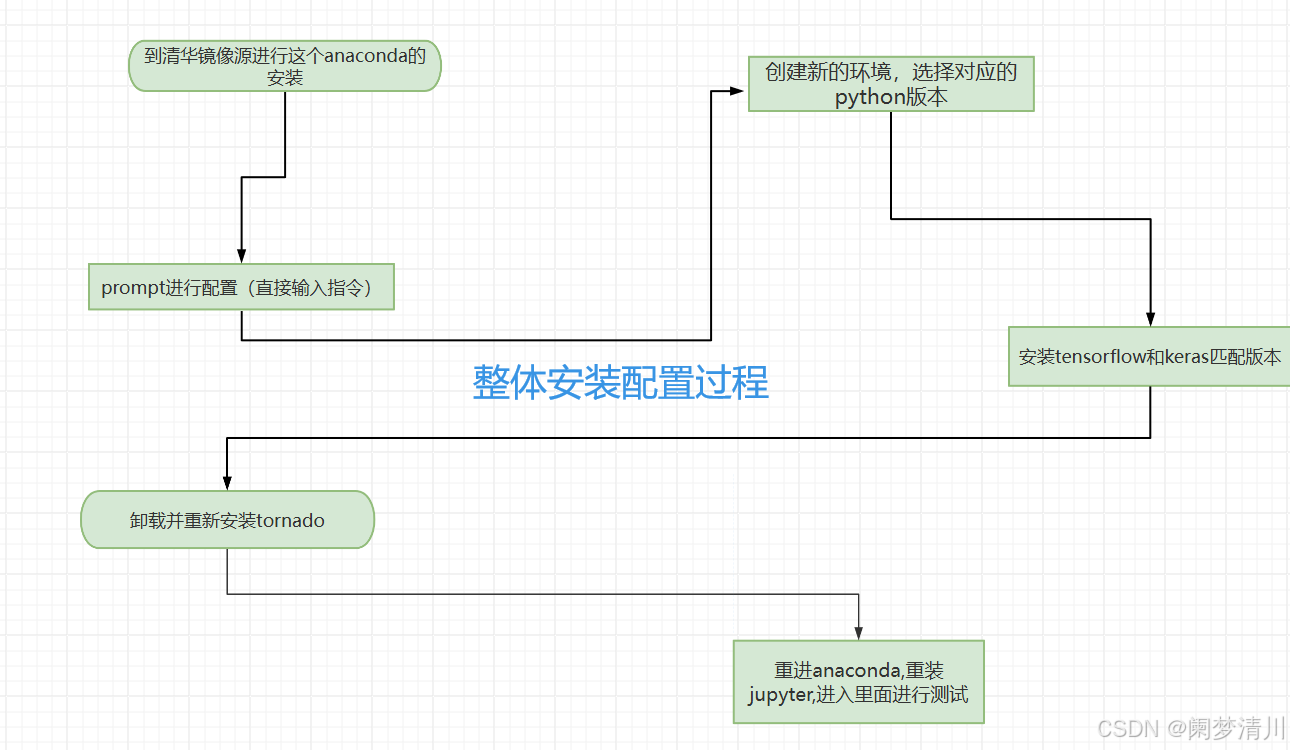
本文主要是介绍Anaconda安装和环境配置教程(深度学习准备),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.下载选择
2.prompt配置
3.虚拟环境配置
4.检查是不是安装成功
5.安装jupter
6.关闭anaconda重新进入
7.总结
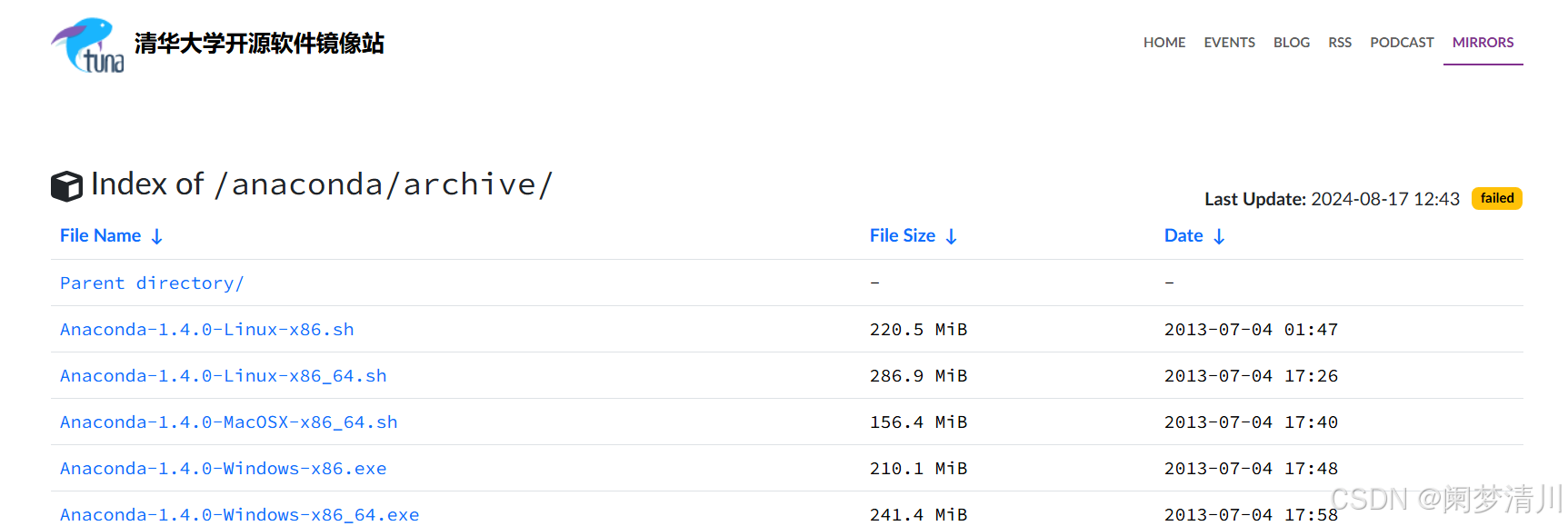
1.下载选择
我第一次使用的这个官网上面的邮箱的方式下载的,但是这个方式真的特别慢,于是用了这个清华的镜像网站,网上有很多的介绍,我就不班门弄斧了,建议使用清华的镜像;
我安装的是这个2022年5月份的版本;
2.prompt配置
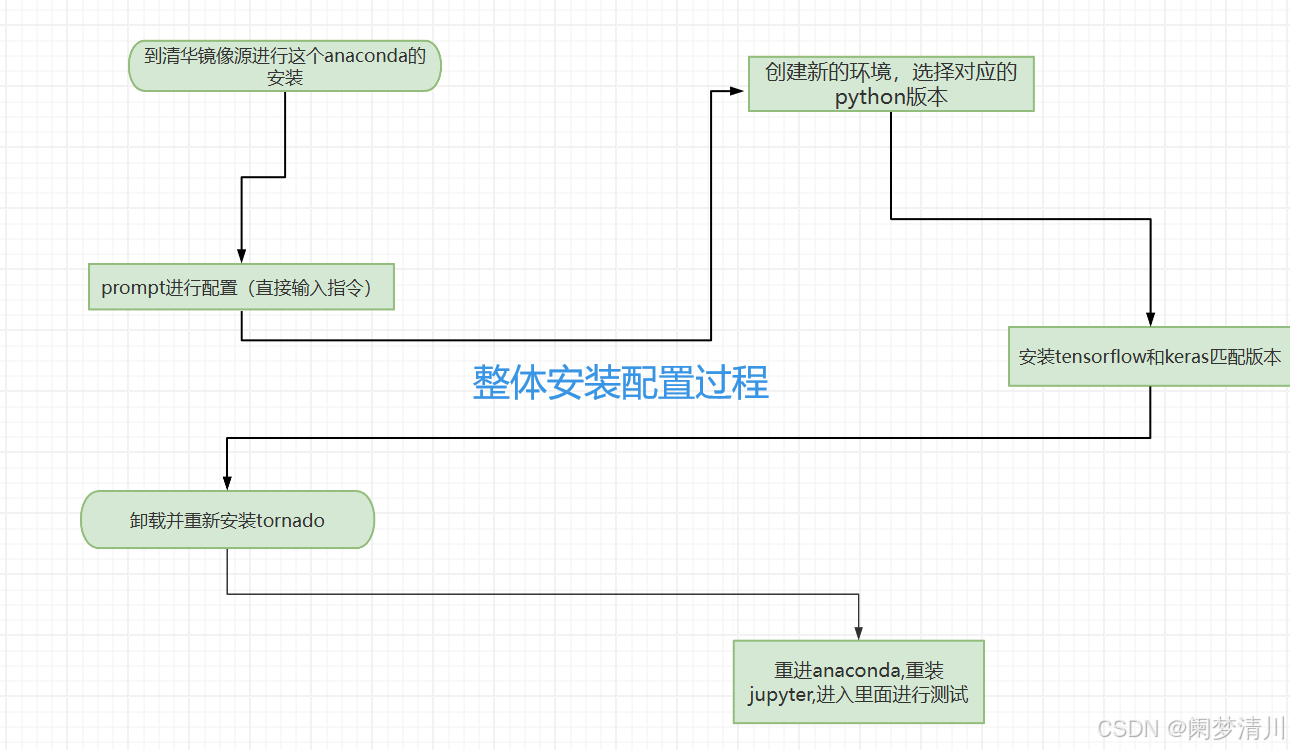
我们的anaconda的许多安装包都是国外的,下载的速度很慢,因此我们需要进行设置,把这个设置成清华大学的,具体操作如下:
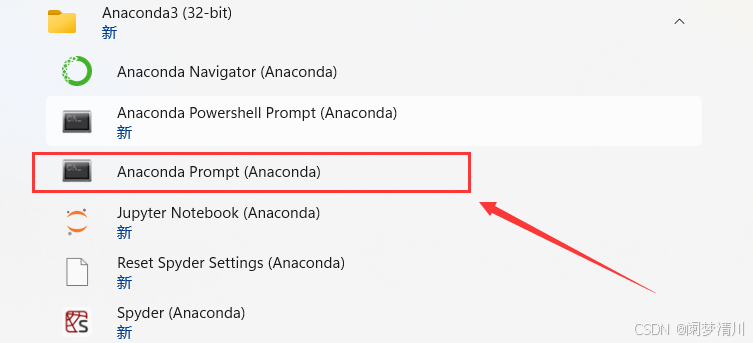
输入下面的三行指令依次回车就可以了:

为了方便实用,我直接贴在下面:一条一条运行即可
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/conda config --set show_channel_urls yes3.虚拟环境配置
创建新的虚拟环境:
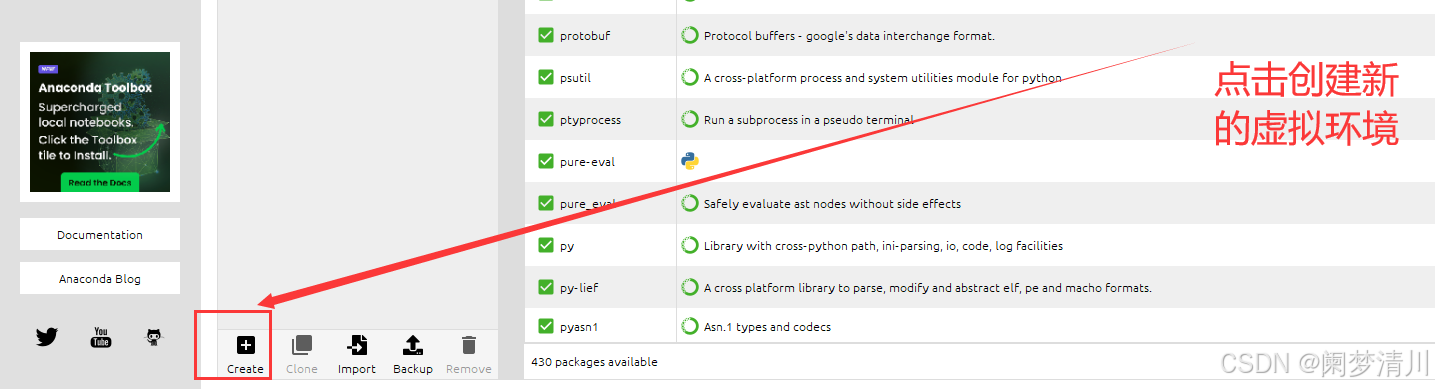
接下俩就很重要了,我们需要安装这个tensorflow需要和这个python和这个keras相互版本匹配(网上有这个版本匹配图,搜一下就好了)
下面的这个是以tensorflow的1.13.1为例和python3.6.13进行演示的:
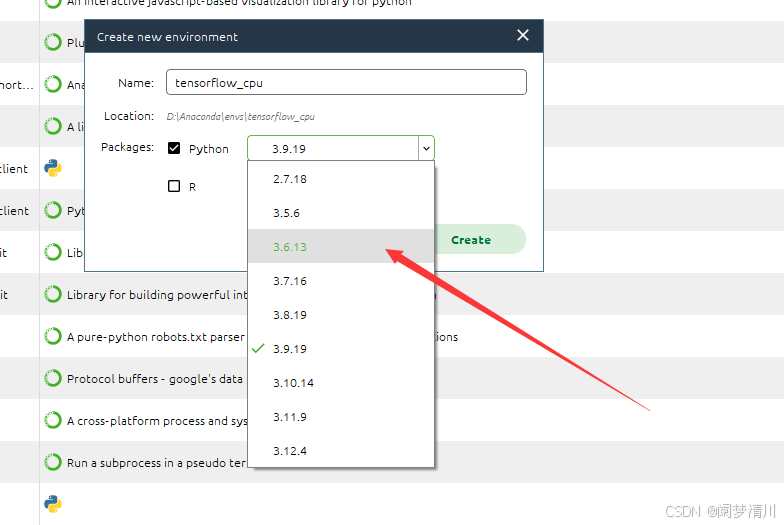
打开创建的虚拟环境安装tensorflow:
conda install tensorflow=1.13.1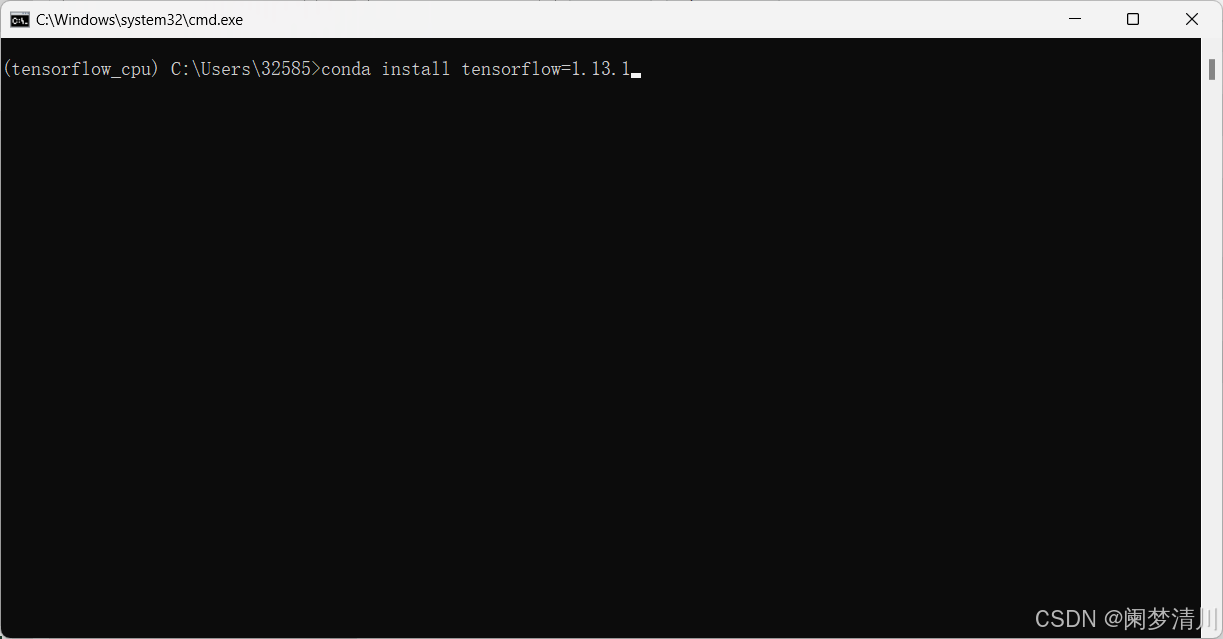
接下来安装与之兼容的keras版本:
conda install keras=2.2.4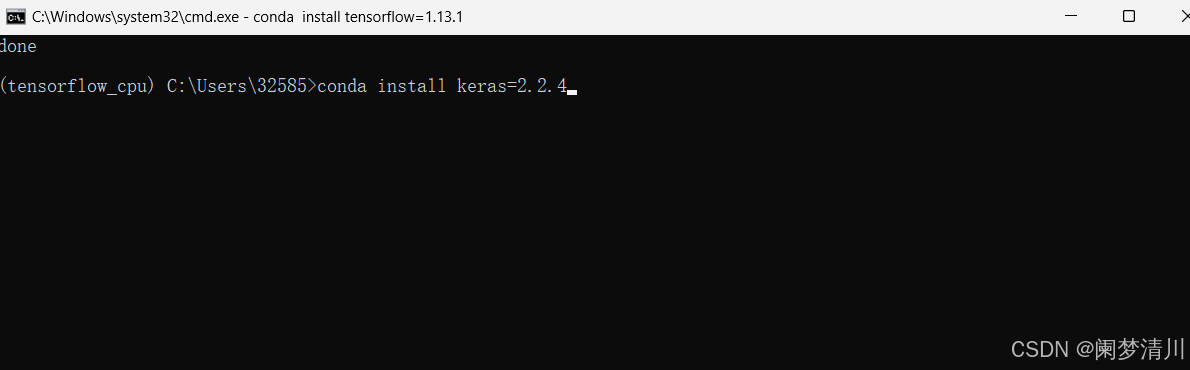
4.检查是不是安装成功
导入模块之后检查版本:

导入模块:
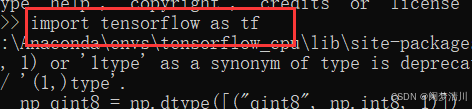
检查版本:
tf. __version__keras. --version__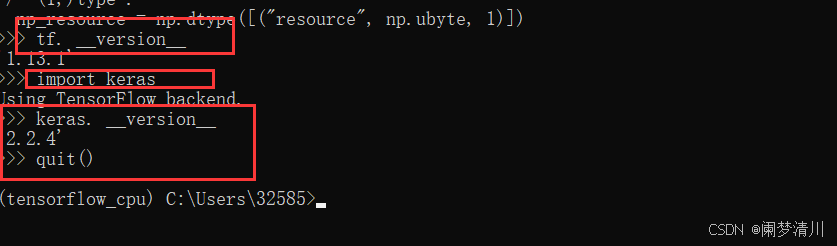
5.安装jupter
这个主要是简化操作的:让我们虚拟环境下直接在这个jupter notebook里面写代码,这个jupyter就是一个类似于记事本的软件,有了这个,我们就可以直接在这个jupyter上面写我们的python代码,不用去在这个终端上面输入;
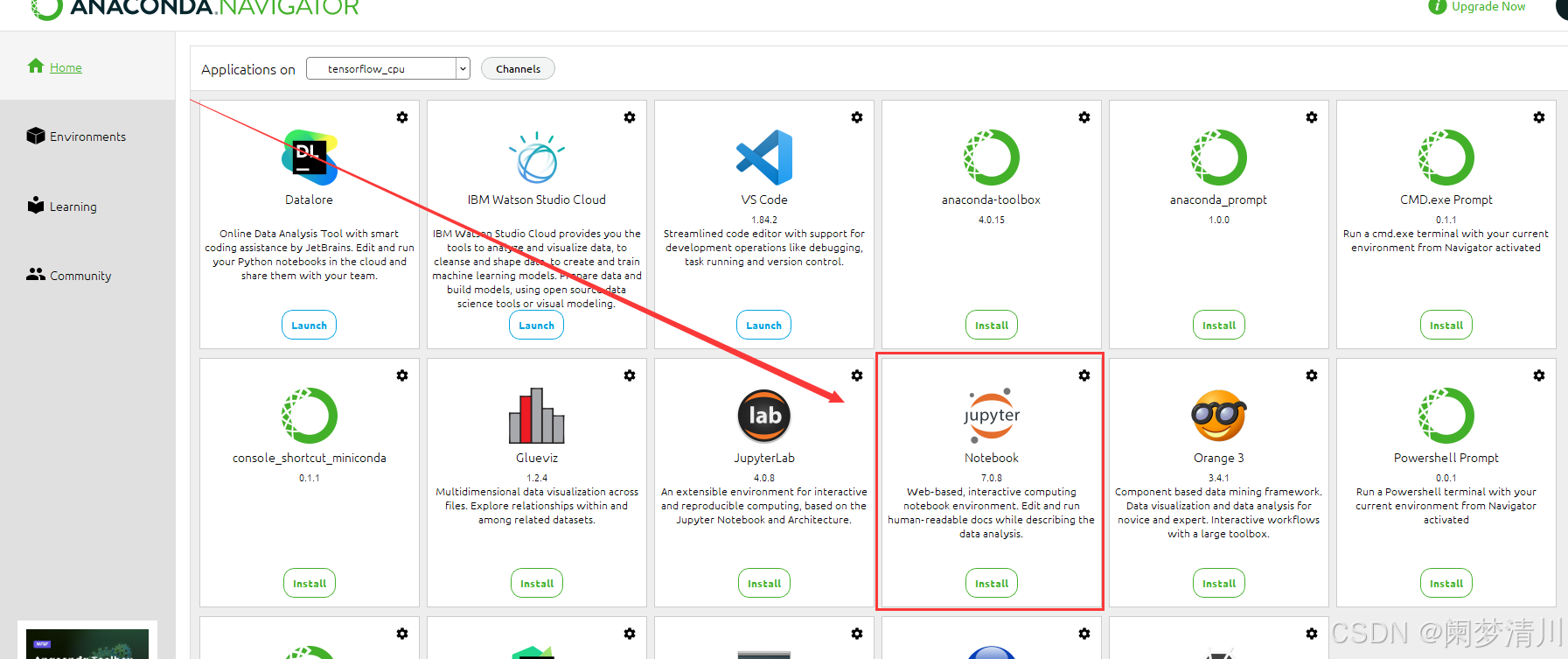
安装成功之后,我们发现在虚拟环境里面,这个已经可以使用了:但实际上因为这个版本各方面的原因,这个可能会打不开,但是没关系,我们暂时不用;
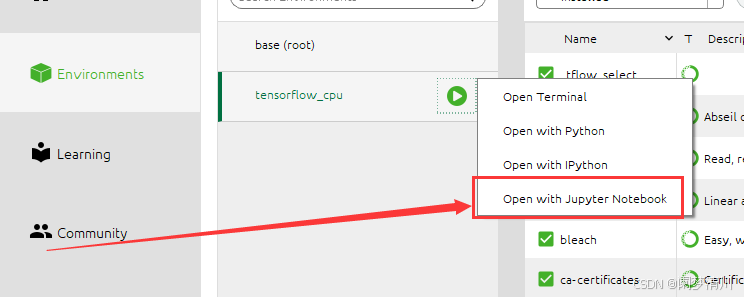
jupter是否可以找到tensor和keras:因为我们的这个jupyter有自己的路径,我们想要在这个里面写代码,首先我们安装的这个leras和tensorflow要可以找到才行,这个怎么找呢?
首先进入终端:
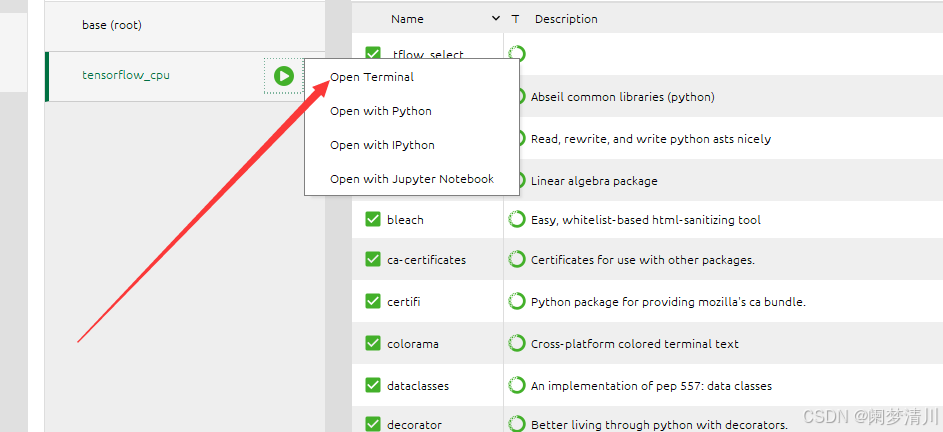

使用这个指令查看这个jupyter下面可以支撑的,我们的这个打印结果可能会有差异,有的是只有python,有的就已经有这个tensorflow了,没关系的;
jupyter kernelspec list我们这个时候启动jupyter,这个时候是进不去的,因为这个里面的一个版本过高(我们可以使用这个pip list指令查看所有的软件包和对应的版本,发现这个tornado包的版本是>5的),我们需要在这个终端上面输入:
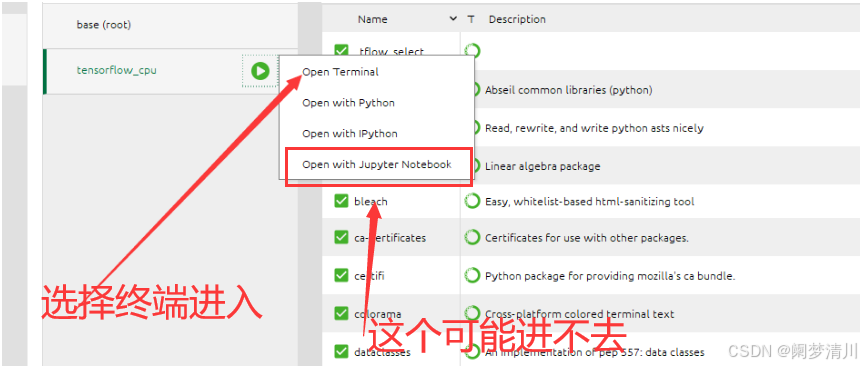
就是因为我们直接打开第四个选项jupyter notebook的时候进不去,我们打开第一个,在这个里面输入jupyter notebook 这个时候发现报错了,这个就是因为我们的这个里面的tornado版本过高,我们这个时候需要卸载重新安装;

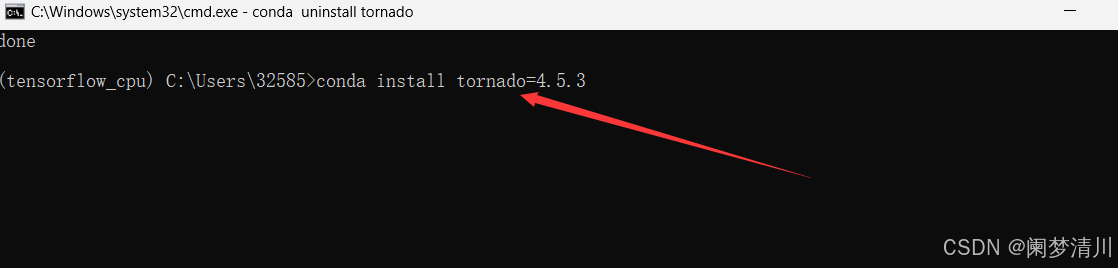
卸载指令:

重现安装,降低版本:降低到5以下的版本即可;
6.关闭anaconda重新进入
我们进入之后到这个对应的环境里面发现这个jupyter又不可以点击(就是一共四个选项,前面的两个可以使用,后面的两个事白色的,我们没有办法使用)
这个时候,我们回到这个home里面去,发现这个jupyter又需要我们进行重新的安装,这个是因为我们上面把这个tornado的版本更新了,因此这个jupyter重新需要安装,并不是因为我们重新进入导致的,这个样的话我们每一次进入都需要重新安装,岂不是很麻烦,这个也提示我们对于这个软件的版本升级之后,这个需要重新生效;

重新安装这个jupyter之后,在这个invironment里面的第四个选项里面进入这个jupyter里面去,这个时候就可以进去了,并且会跳转到这个浏览器里面去打开;
新建一个python3的代码:
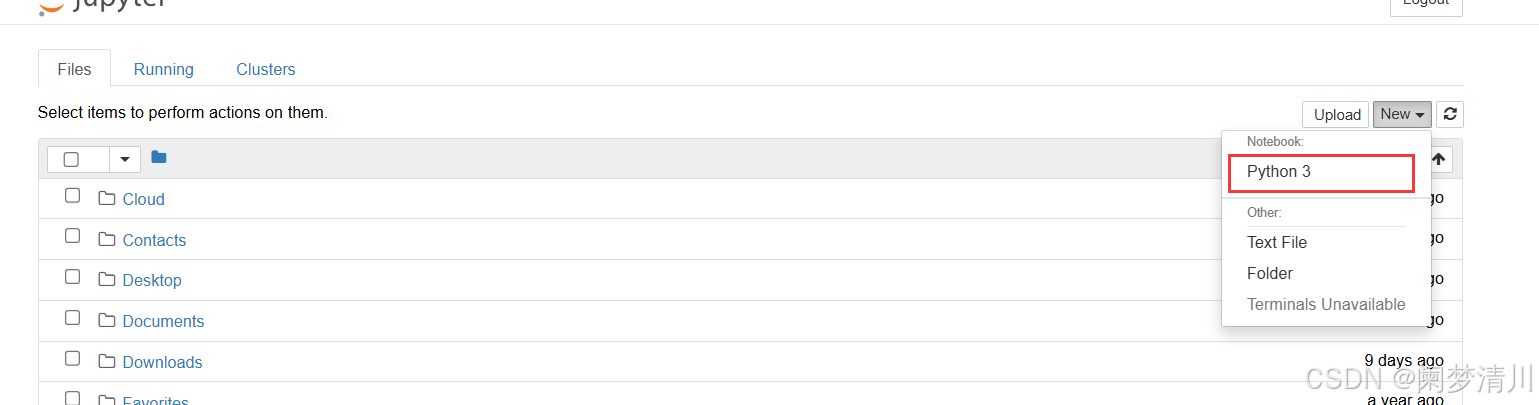
我们在这个里面导入对应的模块,查看对应的版本,这个时候就没有问题了,这个红色的不是报错!!!这个显示的是安装位置的相关的信息;
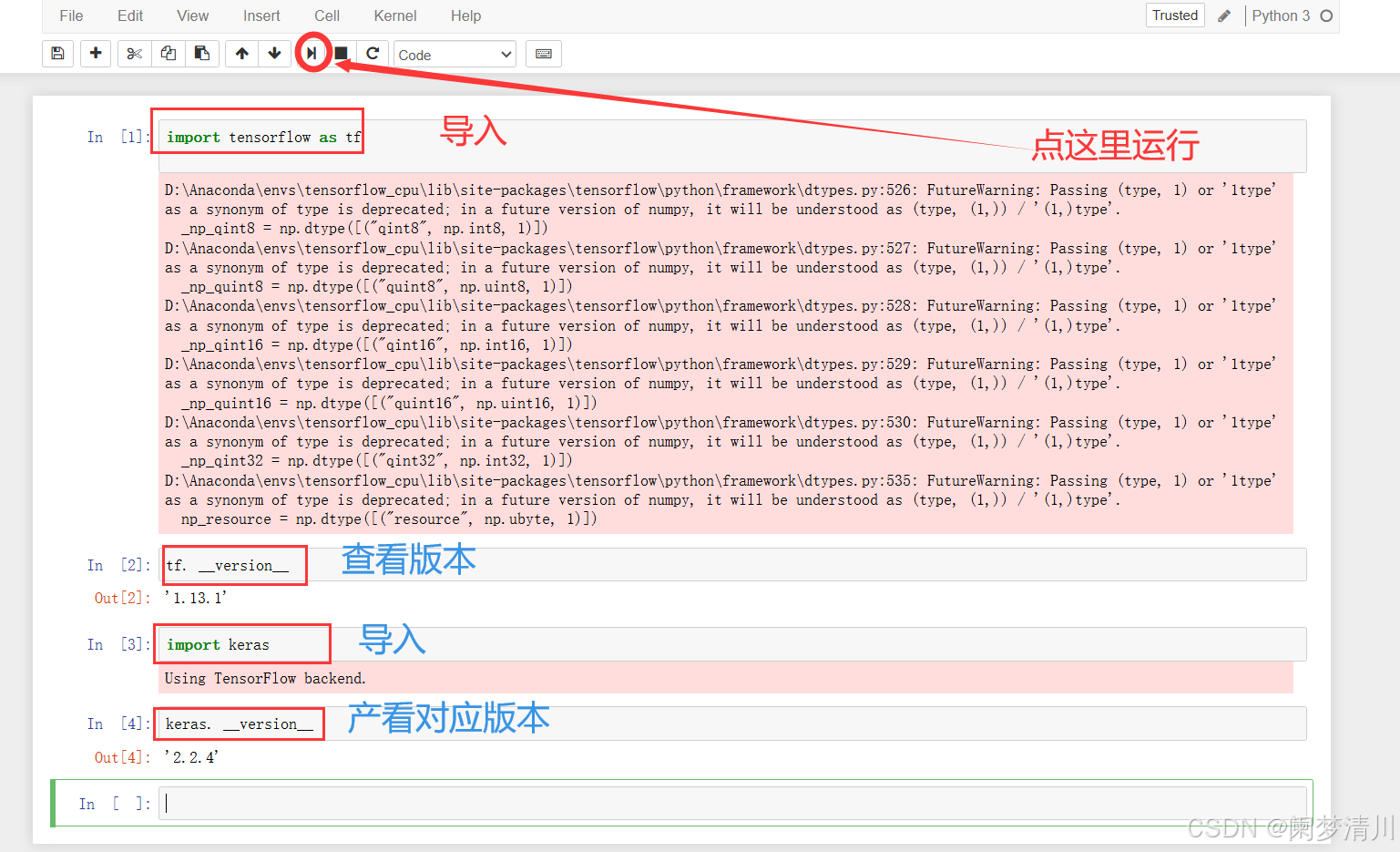
一切正常之后,我们以后想要导入的话,就可以直接在这个jupyter notebook里面使用这个conda install 包包的名字就可以直接安装了,不用在这个终端上面输入;
7.总结
其实这个anaconda的这个使用体验有时候确实不是很好,但是这个我们多试几次就好了,这个jupyter的安装,以及我们自己创建虚拟环境,安装这个keras和tensorflow匹配的版本很重要;
了解这个jupyter在虚拟环境里面进不去的原因,就是因为这个tornado的版本太高,我们需要重新安装以降低他的版本;
这篇关于Anaconda安装和环境配置教程(深度学习准备)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








