本文主要是介绍图像的加法 | 05,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
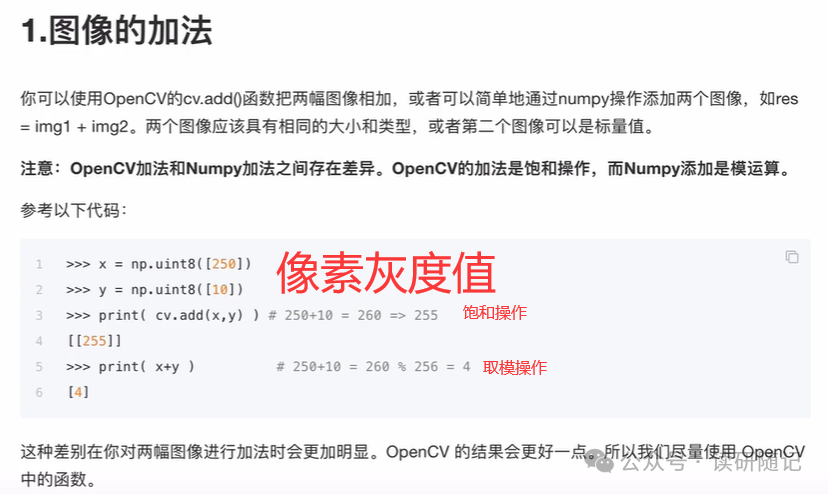
大于255的直接取255。

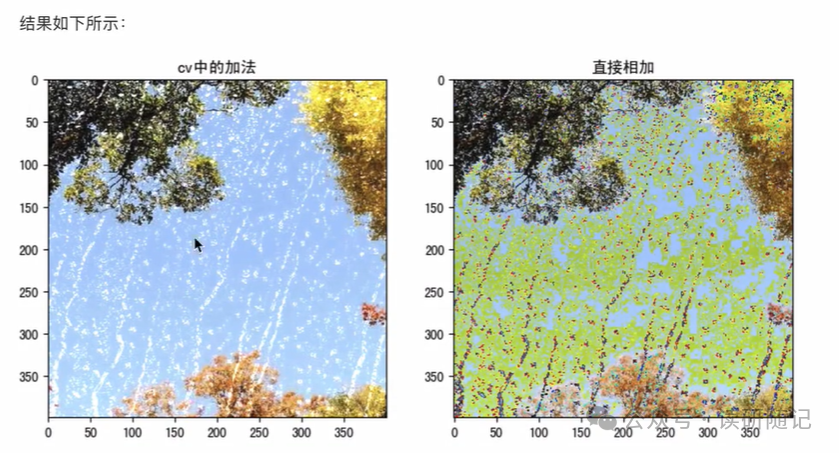
code:
import cv2 as cvimport matplotlib.pyplot as pltrain = cv.imread("../Dataset/TrainValDataset/Image/camourflage_00007.jpg")plt.imshow(rain[:,:,::-1])plt.show()view = cv.imread("../Dataset/TrainValDataset/Image/camourflage_00007.jpg")plt.imshow(view[:,:,::-1])plt.show()img1 = cv.add(rain,view)plt.imshow(img1[:,:,::-1])plt.show()img2 = rain+viewplt.imshow(img2[:,:,::-1])plt.show()
算数运算:
加法:img1 = cv.add(x1,x2) 截断处理【大于255的直接取255】
加法用在图像合并的时候,减法用在背景消除的时候。
#减法img3 = cv.subtract(view,rain)plt.imshow(img3[:,:,::-1])plt.show()img4 = view-rainplt.imshow(img3[:,:,::-1])plt.show()x = np.uint8([250])y = np.uint8([255])#乘法cv.multiply()#除法cv.divide()
乘除用的很少,像素点进行乘除。
这篇关于图像的加法 | 05的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







