本文主要是介绍科研论文必须要了解的25个学术网址,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
各位同学大家好,我是Toby老师,今天介绍一下科研论文必须要了解的25个学术网站。下述论文网站收藏内容有差异,大家可以检索比较。
1.SCI
SCI(Science Citation Index)是一个学术引文数据库,收录了全球多个学科高质量的学术期刊。它由汤森路透(现为科睿唯安Clarivate Analytics)管理,旨在提供科研文献的引用分析和评估。SCI数据库被广泛用于评估学术期刊的影响力和学术成果的引用情况。

2.SSCI
SSCI(Social Sciences Citation Index)是社会科学引文索引,是由科睿唯安(Clarivate Analytics,前身为汤森路透)出版的一个学术引文数据库。该数据库专注于社会科学领域,涵盖了多个学科,包括但不限于心理学、社会学、经济学、政治学、人类学、教育学等。
影响因子:SSCI计算并提供各个期刊的影响因子,帮助研究人员评估特定期刊在其领域内的相对影响力。
SCI和SSCI区别
SCI(Science Citation Index)和SSCI(Social Sciences Citation Index)都是由科睿唯安(Clarivate Analytics,前身为汤森路透)出版的引文数据库。不同点在于SCI侧重点在自然科学,SSCI侧重点在社会科学。
-
SCI:主要覆盖自然科学领域,包括物理、化学、生命科学、环境科学、工程学等学科。
-
SSCI:专注于社会科学领域,涵盖心理学、社会学、经济学、政治学、人类学、教育学等学科。
3 谷歌学术

Google Scholar(谷歌学术搜索)是一个由Google开发的免费学术搜索引擎,它帮助用户查找和访问各种学术文献和资料。以下是Google Scholar的一些关键特点和概述:
1. 搜索范围:
-
Google Scholar 索引了广泛的学术文献,包括期刊文章、会议论文、学位论文、书籍章节、技术报告以及其他学术出版物。
2. 跨学科覆盖:
-
它涵盖了几乎所有学科领域,如自然科学、社会科学、人文学科、工程学、医学等。
3. 引文跟踪:
-
用户可以查看每篇文献的引用次数,这有助于评估文献的影响力和学术价值。
4. 相关文章推荐:
-
Google Scholar 会根据用户的搜索结果推荐相关的学术文章。
5. 访问全文:
-
对于许多文献,Google Scholar 提供了全文预览或链接,用户可以直接阅读或下载。
6. 作者资料页:
-
学者可以创建自己的Google Scholar个人资料页,展示他们的研究成果和引用信息。
7. 引用工具:
-
Google Scholar 提供了引用工具,帮助用户在撰写论文时正确引用文献。
8. 法律和专利信息:
-
除了学术文献,Google Scholar 还提供了对法律文件和专利的搜索。
9. 语言支持:
-
虽然主要支持英文,但Google Scholar 也支持多种语言的搜索。
10. 个性化设置:
-
用户可以根据自己的需要设置搜索偏好,如排序方式、显示结果的数量等。
11. 学术社区:
-
Google Scholar 为全球的研究人员、学生和教育工作者提供了一个共享和发现学术信息的平台。
12. 免费使用:
-
Google Scholar 是一个免费服务,对所有用户开放。
Google Scholar 是学术研究中的重要工具,它简化了文献检索过程,使得获取学术资源变得更加容易和高效。通过Google Scholar,用户可以快速找到所需的学术资料,促进了学术交流和知识传播。
4. 百度学术

网址:http://xueshu.baidu.com/
百度学术(Baidu Scholar)是百度公司推出的一个免费学术资源搜索平台,致力于帮助用户查找和获取学术文献。以下是百度学术的一些主要特点和功能:
-
海量学术资源:百度学术集成了海量的学术资源,包括中外文学术文献、期刊、会议论文等。
-
跨学科覆盖:平台涵盖了300个学科研究方向,为用户提供广泛的学术内容。
-
学术站点索引:百度学术索引了120万国内外学术站点,方便用户一站式检索。
-
文献全文链接:提供了12亿篇文献的全文链接,帮助用户快速获取所需文献。
-
学者主页:百度学术为400万国内学者提供了个人主页,学者可以管理自己的学术成果和被引情况。
-
学术影响力分析:平台提供学科分析、学者分析、期刊分析等工具,帮助用户评估学术影响力。
-
实时更新:百度学术实时监控全网文章更新,确保学术信息的时效性。
-
智能推荐:利用人工智能技术,百度学术能够根据用户的搜索历史和偏好推荐相关学术内容。
-
多语言支持:百度学术支持中文和英文等多种语言的文献检索。
-
用户中心:用户可以在百度学术的用户中心管理自己的订阅、收藏和论文查重等。
百度学术的目标是优化学术资源生态,引导学术价值创新,并为科研工作者提供全面的学术资源检索和优质的科研服务体验。通过百度学术,用户可以更高效地进行学术研究和文献管理。
5. BASE
网址:http://www.base-search.net/
BASE(Bielefeld Academic Search Engine)是一个多学科的学术搜索引擎,由德国比勒费尔德大学图书馆开发。它提供对全球异构学术资源的集成检索服务,整合了大约160个开放资源的数据,超过200万个文档。BASE专注于学术开放获取网络资源,随着开放获取运动的发展,越来越多的机构知识库服务器采用“开放存储元数据收割协议”(OAI-PMH)的方式提供内容,BASE采集、标准化和索引化这些数据。
BASE的特点包括:
-
智能化选取资源,只收录符合学术质量和相关性等特殊要求的文件服务。
-
提供用户搜索的透明性。
-
深入“底层网页”的网络资源,这些资源可能被商业搜索引擎忽视。
-
搜索结果会显示之前的文献数据。
-
具有多个选项来排序搜索结果列表。
-
具有“再定您的搜索结果(经过作者、主题、杜威分类法、出版年、出版类型、语言和文件类型)”的选项。
-
能够以杜威十进分类法(DDC)和文件类型进行浏览。
BASE提供超过来自6000个信息源的1.4亿文献,用户能获取60%经过索引后的文件全文。它作为“欧洲科研的数字知识库基础设施愿景(DRIVER)”欧洲项目的一部分,是注册OAI服务提供者和贡献者。数据库管理者可以通过插件接口整合BASE的索引到本地基础设施,例如元搜索引擎、图书馆目录等。
总的来说,BASE是一个强大的学术搜索引擎,为研究人员、学生和学术界提供了一个宝贵的资源,以便于他们能够访问和利用大量的学术文献和数据
6. Cnpiec LINK service

网址:http://cnplinker.cnpeak.com/
cnpLINKer,即中图链接服务,是由中国图书进出口(集团)总公司开发并提供的国外期刊网络检索平台。该平台旨在为用户提供一个统一的检索、获取国外期刊的网络信息服务平台。
cnpLINKer的主要特点和功能包括:
-
广泛的期刊收录:平台收录了50多个国家和地区的3000多家期刊出版公司出版的30000多种期刊信息,包括1200多万条目次文摘数据和全文链接资源。
-
实时更新:系统与国外出版社的目次文摘数据保持实时更新,确保用户获取最新的学术信息。
-
开放获取期刊:平台开发了国外开放获取期刊查询和检索功能,增加了18000多种开放获取期刊供用户免费浏览和下载。
-
电子期刊导航服务:推出了eJnavor (Electronic Journals Navigator) 电子期刊导航服务,为图书馆整合其通过各种渠道订购的海外期刊和数据库等产品信息,实现一站式的电子期刊导航服务。
-
国内馆藏查询:平台收录了国内众多图书馆的期刊订阅信息,提供基于Web的国内图书馆OPAC系统馆藏资源链接。
-
多语言支持:支持中文和英文等多种语言的文献检索。
-
个性化服务:提供个性化的检索及推送服务,满足不同用户的特定需求。
cnpLINKer利用数字化网络化技术,为国内用户提供了一个检索国外电子期刊的统一平台,促进了期刊业务的运行体系和管理机制的发展。用户可以通过统一的查询检索界面和快速的全文检索引擎,便捷地检索到所需文献资料,并通过平台提供的电子全文链接获取到国外期刊的全文内容。
7. PMC(PubMed Cenral)
网址:http://www.ncbi.nlm.nih.gov/pmc/
PubMed Central(PMC)是由美国国立卫生研究院(National Institutes of Health, NIH)提供的一项服务,它是一个存档生物医学和生命科学领域科研文献的数字仓库。PMC由美国国家医学图书馆(National Library of Medicine, NLM)授权,由NLM的国家生物技术信息中心(National Center for Biotechnology Information, NCBI)负责开发和维护,自2000年2月启动以来,已经成为一个重要的免费获取生物医学文献资源的平台。
PMC的核心原则是免费提供文献资源,它永久保存了这些内容,并且不断更新以适应技术进步。尽管PMC免费提供文献,但版权仍归作者和出版商所有,使用PMC的用户必须遵守版权声明。PMC不仅是一个数据仓库,存储合作杂志的文献和作者手稿,而且是一个资源整合中心,它将各种来源的交叉引用数据以通用格式存储在一个数据库中,便于科研工作者进行研究和知识扩展。
PMC与PubMed的关系密切,PubMed是一个基于互联网的文献检索系统,收录了大量生命科学期刊的目次和文摘,而PMC则提供了这些文献的全文链接。PubMed Central的所有论文在PubMed中都有相应的记录,两者共同为科研人员提供了一个强大的文献检索和获取工具。
总的来说,PubMed Central是一个宝贵的资源,它为全球的研究人员、学生、医疗专业人员和公众提供了免费访问生物医学和生命科学领域文献的途径。通过这个平台,用户可以迅速获取免费的全文及相关材料,促进了科学研究和教育的发展。
8.中国知网
网址:http://www.cnki.net/
中国知网(CNKI,China National Knowledge Infrastructure)是中国最大的学术文献数据库之一,由清华大学和清华同方发起,始建于1999年。它是一个集期刊、学位论文、会议论文、专利、标准等各类文献资源为一体的大型综合性知识服务平台。
中国知网的主要特点包括:
-
丰富的资源:收录了大量的中文学术期刊、学位论文、会议论文、专利、标准等文献资源。
-
广泛的学科覆盖:涵盖自然科学、工程技术、农业、医药卫生、经济管理、教育、文学、艺术、法律、哲学、历史等多个学科领域。
-
便捷的检索功能:提供了强大的检索工具,用户可以通过关键词、作者、标题等多种方式进行文献检索。
-
全文获取:用户可以通过知网获取文献的全文,包括PDF和CAJ格式的文件。
-
个性化服务:提供个性化的订阅、收藏、引用跟踪等服务。
-
学术评价工具:知网还提供了学术期刊的影响因子、被引频次等评价指标,帮助用户评估文献的学术价值。
-
国际合作:中国知网与多个国际数据库和出版机构建立了合作关系,推动了中外学术交流。
-
版权保护:知网注重版权保护,确保所有文献的合法使用。
中国知网对于中国的学术研究、教育和科研工作具有重要意义,它不仅为研究人员提供了丰富的学术资源,也为学术成果的传播和交流提供了平台。通过中国知网,用户可以方便地获取到所需的学术信息,促进了知识的积累和创新。
我建议国内客户可以多关注知网,可以获取大量有价值信息。例如搜索机器学习,获取相应论文信息。当然知网下载是要收费的。
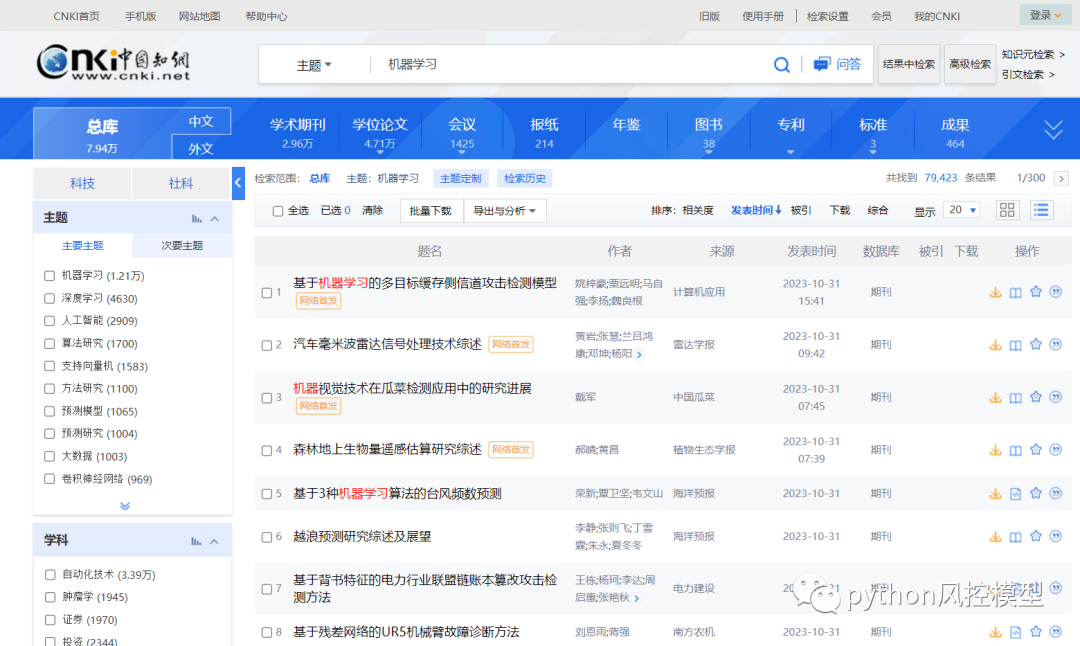
左侧有类目,可以勾选感兴趣的内容,缩小搜索范围。
知网是一个知名的学术资源检索平台,提供了丰富的学术文献资源和查重服务,因此在中国的许多高校和科研机构中被广泛使用。
但由于知网价格较高,并不是所有高校都选择使用知网进行论文查重,具体情况可能因地区、学科领域和学校政策等因素而有所不同。
一些高校可能选择使用知网或其他类似的查重工具,而另一些高校可能使用其他在线查重服务或自行开发的查重系统。
如果您想了解某所高校的具体查重工具选择,建议向该高校的教务处或研究生院进行咨询。
Toby老师可复现知网上大部分金融风控和生物医药建模的论文。
相关案例:
论文复现和点评《基于随机森林模型的个人信用风险评估研究》
(捷信违约风险)机器学习模型复现(论文_毕业设计_毕设)
四川省大学生金融科技建模大赛
中文核心周刊复现-基于逻辑回归的金融风投评分卡模型实现
金融风控实战-Python信用评分卡建模全流程
python风控建模实战lendingClub
论文复现机器学习建模案例-汽车消费金融申请评分卡和数据挖掘
汽车金融申请评分卡模型-论文毕设复现
论文复现金融风控案例-give me some credit
论文复现-金融风控模型案例
供应链金融机器学习模型
机器学习股票崩盘预测模型
人工智能助力银行提升放贷效率—基于Python语言开发信用评分卡
python机器学习-糖尿病数据挖掘
15大经典案例-Python生物信息学SCI案例复现
Home Credit捷信数据集个人信贷违约风险预测
机器学习:银行贷款违约预测模型
9. DOAJ
网址:https://doaj.org/
DOAJ(Directory of Open Access Journals)是一个国际知名的开放获取期刊目录,它提供了一个广泛的、多样化的开放获取(OA)期刊索引。DOAJ由瑞典隆德大学图书馆(Lund University Libraries)于2003年5月创建和维护,旨在推动全球范围内的学术交流和知识共享。
9.BookSC
BookSC(Booksc.org)是一个提供大量电子书籍和科学文章的在线平台,它允许用户免费下载各种格式的文献资料。以下是BookSC的一些概述信息:
-
丰富的资源:BookSC网站拥有超过250万本书籍,覆盖了广泛的学科领域,包括科学、技术、医学、人文和社会科学等。
-
多种文件格式:平台提供的电子书格式多样,主要包括PDF、DJVU、EPUB等,满足不同用户的阅读需求。
-
免费访问:BookSC致力于让文献资源对所有人开放,用户可以免费下载所需的书籍和文章。
-
便捷的下载:用户可以通过搜索论文或文章的标题直接找到所需内容,并进行下载。
-
用户体验:BookSC网站提供了良好的用户体验,搜索和下载过程简单直观。
-
地区设置:用户可以选择地区并设置为中国,以便获得更好的本地化服务。
-
持续更新:BookSC不断更新其数据库,以包含最新的出版物和研究成果。
-
学术价值:对于研究人员、学生和广大读者来说,BookSC是一个宝贵的学术资源库。
请注意,尽管BookSC提供了大量的免费资源,但在使用时应确保遵守版权法规和合理使用原则。此外,由于版权和法律问题,某些地区的用户可能会遇到访问限制。在这种情况下,用户应考虑使用其他合法的学术资源平台或图书馆资源。
10. arXiv
网址:http://arXiv.org e-Print archive
arXiv(发音为"archive")是一个提供预印本(preprints)的开放获取(open-access)存储库,它允许研究人员分享和访问尚未经过同行评审的学术文章。arXiv最初专注于物理学,后来扩展到数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学、经济学等多个学科领域。
11 万方数据库
网址:http://www.wanfangdata.com.cn/index.html
万方数据库(Wanfang Database)是中国领先的学术文献服务平台之一,提供广泛的中文学术资源。以下是万方数据库的概述:
-
资源类型:万方数据库整合了期刊、学位论文、会议论文、科技成果、专利、标准、法规、地方志、视频等多种类型的文献资源。
-
学科覆盖:内容涵盖理学、工业技术、人文科学、社会科学、医药卫生、农业科学、交通运输、航空航天和环境科学等多个学科领域。
-
数据规模:拥有超过3亿条全球优质知识资源,包括5.4亿余条引文数据。
-
服务功能:提供文献检索、全文获取、文献分析、文献管理等服务,帮助用户精准发现和获取学术资源。
-
合作单位:与国内600余所高校、科研院所等学位授予单位合作,覆盖了85%以上的研究生学位授予单位。
-
更新频率:《中国企业、公司及产品数据库》的信息全年100%更新,确保数据的时效性。
-
访问方式:用户可以通过万方主站或校内镜像访问资源,部分资源可能需要特定的访问权限。
-
特色数据库:
-
万方期刊:集纳了理、工、农、医、人文五大类70多个类目共7600种科技类期刊全文。
-
万方学位论文库:收录了中国各学科领域的学位论文全文。
-
万方会议论文:收录了自1998年以来的国家级学术会议论文。
-
-
用户群体:服务于研究人员、学生、教师、专业人士以及广泛的学术界和公众。
-
国际合作:万方数据库还与国际知名的美国DIALOG联机系统合作,将CECDB(中国企业、公司及产品数据库)定为中国首选的经济信息数据库。
万方数据库是学术研究和教育工作的重要资源,它通过提供丰富的中文学术资源,支持了中国乃至全球的学术发展和知识传播。
12 中国科技论文在线
网址:http://www.paper.edu.cn/
中国科技论文在线(China Science Paper Online)是由中国教育部批准,教育部科技发展中心主办的一个公益性科技论文网站。它旨在为科研人员提供一个方便、快捷的交流平台,以便及时发表最新的科研成果和新观点,促进科研创新思想的交流。
以下是中国科技论文在线的一些主要特点和功能:
-
开放获取:中国科技论文在线支持开放获取(Open Access)运动,允许用户免费访问和下载网站上的论文。
-
多学科覆盖:网站收录了自然科学、工程技术、医药卫生、农业科学等多个学科领域的论文。
-
首发论文:提供“首发论文”栏目,科研人员可以在这里快速发表自己的研究成果。
-
优秀学者和自荐学者:网站设有“优秀学者”和“自荐学者”栏目,展示学者的研究成果和学术贡献。
-
科技期刊:提供与科技期刊相关的信息,包括期刊的影响因子、被引频次等评价指标。
-
热度视界:提供科技领域的热点话题和最新研究动态。
-
论文发表时间证明:网站可为发表论文的作者提供论文发表时间的证明,保护原创作者的知识产权。
-
与国际开放获取同步:作为中国首家与国际开放获取运动同步快速发展的OA仓储平台,中国科技论文在线促进了科研成果的跨国界传播。
-
发展历程:自2003年上线以来,中国科技论文在线不断进行内容组织、展现形式、技术应用、制度规范、平台升级等方面的探索和尝试,引领了学术出版领域的变革。
-
用户服务:网站提供新手帮助、常见问题解答等服务,帮助用户更好地使用平台资源。
中国科技论文在线的建立和发展,为科研人员提供了一个重要的学术交流渠道,有助于推动中国乃至全球的科学研究和知识共享。
13.专利全文下载

网址:https://www.drugfuture.com/cnpat/cn_patent.asp
tent.asp
提供下载号,就能下载你需要的专利。
https://www.drugfuture.com/cnpat/cn_patent.asp 是一个提供中国专利全文下载服务的网站。以下是该网站的一些概述:
-
服务内容:
-
网站提供中国专利全文的打包下载服务,包括申请号和公开(公告)号的查询。
-
-
下载格式:
-
支持PDF和TIF图片格式的下载,通常打包为ZIP格式压缩文件。
-
-
专利类型:
-
涵盖发明专利、实用新型专利和外观设计专利。
-
-
专利时间范围:
-
提供自1985年至今的所有中国专利说明书的下载。
-
-
用户体验:
-
专利全文自动打包并打开下载,无需一页页保存。
-
支持全文在线查看功能。
-
服务器处理查询后自动打开下载页,如果专利全文页数较多,可能需要较长时间等待。
-
-
下载速度:
-
网站提到中国专利全文PDF格式下载已升级为极速版,以提升下载速度。
-
-
查看软件:
-
提供了推荐使用的查看软件,如Adobe Acrobat Reader查看PDF格式文件,以及ACDSEE查看TIF或JPG格式文件。
-
-
更新频率:
-
网站承诺专利数据每周更新,以保持信息的时效性。
-
-
其他服务:
-
除了中国专利下载,网站还提供欧洲专利和美国专利的下载服务。
-
-
联系方式:
-
用户可以通过提供的电子邮件地址(drugfuture@163.com)提出意见和建议。
-
-
一站式服务:
-
网站提供一站式的专利下载服务,包括中国、欧洲和美国的专利。
-
这个网站对于需要获取中国专利全文的用户来说是一个有用的资源,尤其是对于研究人员、法律专家和技术开发者。用户在使用时应确保遵守相关的版权法规和使用条款。
14.OA图书馆
网址:http://www.oalib.com/
OA图书馆(Open Access Library)通常指的是提供开放获取(Open Access, OA)学术资源的平台,这些资源通常是合法的,因为它们遵循开放获取出版的原则,允许用户免费访问和下载学术文章。开放获取是一种旨在提高研究成果可及性的运动,它鼓励作者将他们的研究成果公开发布,以便任何人都可以免费阅读、使用和分享。
15.PublicLibrary of Science
网址:https://www.plos.org/
Public Library of Science(PLOS,简称PLoS)是一家非营利性的出版机构,致力于推动科学和医学领域的知识开放获取。PLOS成立于2000年,由一群诺贝尔奖获得者和科学领袖发起,目的是改变传统学术出版模式,使科学研究结果对所有人免费开放。
16 Socolar
网址:http://www.socolar.com/
Socolar(Social Science Library)是一个专注于社会科学领域的开放获取(Open Access)学术资源平台。它旨在为研究人员、学生、教育工作者和公众提供广泛、便捷的社会科学文献资源。以下是Socolar的一些关键特点:
-
开放获取资源:
-
Socolar提供了一系列社会科学领域的学术文献,包括期刊文章、会议论文、学位论文、研究报告等。
-
-
多学科覆盖:
-
平台涵盖了经济学、政治学、社会学、法学、教育学、心理学等多个社会科学学科。
-
-
丰富的数据库:
-
Socolar整合了多个开放获取数据库和资源,提供了一个统一的检索和访问接口。
-
-
免费访问:
-
用户可以免费访问和下载Socolar上的学术资源,无需支付费用或通过订阅。
-
-
便捷的检索功能:
-
Socolar提供了强大的检索工具,用户可以通过关键词、作者、标题、出版年份等多种方式进行文献检索。
-
-
学术社区支持:
-
Socolar支持学术社区的交流和合作,鼓励研究人员分享和传播他们的研究成果。
-
-
国际化内容:
-
平台收录了来自世界各地的社会科学研究成果,促进了全球学术交流和知识共享。
-
-
数据更新和维护:
-
Socolar定期更新其数据库,以确保提供最新的学术资源和信息。
-
-
用户友好的界面:
-
Socolar提供了一个用户友好的界面,使得检索和访问学术资源变得简单直观。
-
-
遵守版权法规:
-
Socolar遵守相关的版权法规和开放获取政策,确保所有提供的资源都是合法的。
-
Socolar作为一个开放获取平台,对于推动社会科学领域的知识传播和学术交流具有重要意义。它为全球的研究人员和学术工作者提供了一个宝贵的资源,帮助他们获取和利用社会科学领域的最新研究成果。更多信息可以访问Socolar的官方网站。
17. Scientific Research Publishing
网址:http://www.scirp.org/
Scientific Research Publishing(SCIRP)是一个全球性的学术出版平台,致力于为科学研究者和学术界提供高质量的开放获取期刊和会议论文集。
18.NCBI
国家生物技术信息中心(National Center for Biotechnology Information, 简称NCBI) 是美国国家医学图书馆(NLM)的一部分(该图书馆是美国国家卫生研究所的一部分).
许多受尊敬的研究者在NCBI工作, 如比较基因组学领域的一位多产的科学家Eugene Koonin和BLAST序列数据库搜索算法的作者Stephen Altschul.

随着SARS和COVID-19病毒爆发,基因已经不是一个简单科研项目,而是上升到国家安全高度。基因数据库关系国家和民族生存。
19.SEER
SEER数据库是美国国家癌症研究所(National Cancer Institute)维护的一个重要的癌症流行病学数据库,全称为Surveillance, Epidemiology, and End Results Program。该数据库收集了美国各地的癌症患者的诊断、治疗和预后数据,旨在帮助研究人员和决策者了解癌症的发病率、治疗效果和生存率等信息。
SEER数据库包含了多种类型的数据,包括人口统计学数据、癌症登记数据、病理学数据、治疗数据等,涵盖了多种癌症类型和各个年龄段的患者。研究人员可以通过SEER数据库进行流行病学研究、生存分析、治疗效果评估等工作。
SEER数据库的数据对于癌症研究和公共卫生政策制定具有重要的意义,被广泛应用于学术研究、临床实践和卫生政策制定等领域。
目前在SEER发生物信息或医学类的AI机器学习相关论文越来越多。
SEER 相关案例-乳腺癌生存分析
20.NCHS
NCHS stands for the National Center for Health Statistics, which is a part of the Centers for Disease Control and Prevention (CDC). The NCHS is responsible for collecting, analyzing, and disseminating health data to inform public health policy and decision-making. They conduct surveys, research, and data analysis on a wide range of health topics to help monitor and improve the health of the population.
NCHS代表美国国家卫生统计中心,是疾病控制和预防中心(CDC)的一部分。NCHS负责收集、分析和传播健康数据,以指导公共卫生政策和决策。他们进行调查、研究和数据分析,涉及广泛的健康主题,以帮助监测和改善人口的健康。NCHS积累大量居民疾病防控基础数据库,近年来大量生物医药相关AI,机器学习,统计和数据挖掘论文的数据源来自NCHS。
21.Science
《Science》是全球最顶尖的科学期刊之一,由美国科学促进会(AAAS)于1880年创刊。它涵盖广泛的科学领域,发表高质量的原创研究文章、评论和新闻。以下是《Science》期刊的一些关键特点:
-
跨学科:《Science》期刊关注生命科学、物理科学、化学、地球科学、材料科学、社会科学等多个学科,致力于促进不同学科之间的跨界交流。
-
高影响力:作为科学界最具声望的期刊之一,《Science》在科学研究的传播与影响方面有着重要地位。期刊的影响因子通常较高,反映出其发表的研究被广泛引用。
-
严格的同行评审:所有提交的文章都经过严格的同行评审程序,以确保研究的原创性、质量和科学性。
-
原创研究和综合性评论:除了原创研究论文外,《Science》还发布综合性评论文章、技术报告和科学新闻,帮助读者了解最新的科学发现和研究趋势。
-
全球覆盖:《Science》拥有广泛的国际读者群,吸引了来自世界各地的研究人员和科学家,促进全球科学交流与合作。
-
数字化和开放获取:《Science》提供数字版,并在一些情况下提供开放获取选项,使得研究成果能够更广泛地传播。
-
特色部分:期刊内设有不同的特色栏目,诸如“要闻”、“观点”和“简讯”等,带给读者多样化的科学视角和研究动态。
-
科学教育和公众参与:除了专业的研究文献,《Science》也关注科学教育和公共理解科学的问题,推动科学知识的社会传播。
总之,《Science》作为一个具有深远影响的科学期刊,为科研人员提供一个重要的平台,促进科学知识的分享、讨论和发展。

22.Nature
《Nature》是世界上历史悠久的、最有名望的科学杂志之一,首版于1869年11月4日。与当今大多数科学论文杂志专一于一个特殊的领域不同,其是少数依然发表来自很多科学领域的一手研究论文的杂志(其它类似的杂志有《科学》和《美国科学院学报》等)。在许多科学研究领域中,很多最重要、最前沿的研究结果都是以短讯的形式发表在《自然》上。《自然》是一份在英国发表的周刊,其出版商为自然出版集团,这个集团属于麦克米伦出版有限公司,而它则属于格奥尔格·冯·霍茨布林克出版集团。《自然》在伦敦、纽约、旧金山、华盛顿哥伦比亚特区、东京、巴黎、慕尼黑和贝辛斯托克设有办公室。自然出版集团还出版其它专业杂志如《自然神经科学》、《自然生物学技术》、《自然方法》、《自然临床实践》、《自然结构和分子生物学》和《自然评论》系列等。

23.UCI数据库
UCI机器学习资料库目前维护着664个数据集,为机器学习社区提供服务。在这里,您可以捐赠并找到被全球数百万人使用的数据集!
UCI机器学习资料库是一个收集了数据库、领域理论和数据生成器的资源,被机器学习社区用于对机器学习算法进行经验分析。
该档案是由UCI博士生David Aha于1987年创建的ftp档案。从那时起,它已被广泛用于全球的学生、教育工作者和研究人员,作为机器学习数据集的主要来源。
许多人应该感谢使得这个资料库取得成功的人。其中首要的是数据库和数据生成器的捐赠者和创建者。特别感谢过去的资料库馆员:David Aha、Patrick Murphy、Christopher Merz、Eamonn Keogh、Cathy Blake、Seth Hettich、David Newman、Arthur Asuncion、Moshe Lichman、Dheeru Dua、Casey Graff。现任馆员是Kolby Nottingham、Rachel Longjohn、Markelle Kelly。该网站的当前版本于2023年发布。感谢美国国家科学基金会的资助支持。
2023年,中国和美国政府已经明确人工智能为重要发展方向,AI相关论文在各个期刊上也大受欢迎。
24.python金融风控评分卡模型和数据分析(针对初级或中级论文)
《python金融风控评分卡模型和数据分《python金融风控评分卡模型和数据分析》《python金融风控评分卡模型和数据分针对金融风控行业从业者应对工作建模项目需求,本科生,研究生毕业论文参考。《python金融风控评分卡模型和数据分析》提供逻辑回归评分卡/catboost/xgboost/lightgbm/神经网络/非平衡数据处理/贝叶斯智能调参等知识,并用Python代码实现。扫描下面二维码即可收藏课程,了解课程目录,文章和视频介绍。
25.Python风控建模实战案例数据库(针对高端论文)
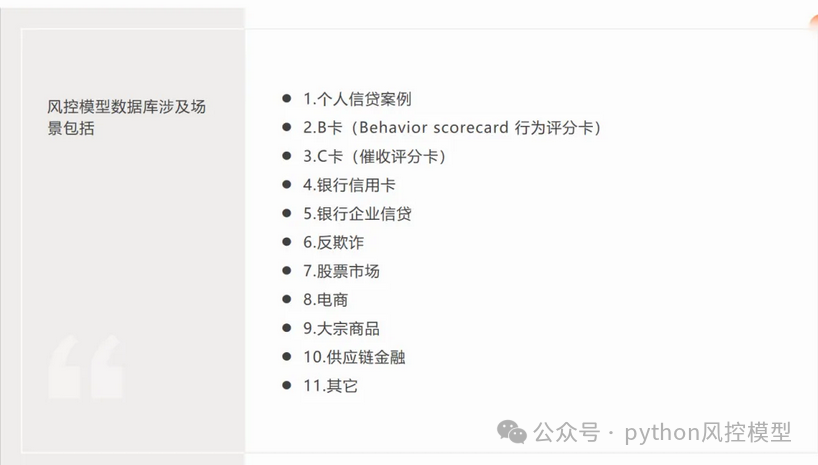
《Python风控建模实战案例数据库》2024年6月正式上线,目前包含至少50个数据集和上千万条真实业务数据,用于满足高端论文,研究生,博士生毕业论文,盲审,查重率低论文,小论文,核心期刊需求。该数据库还被大量金融企业,政府部门采购。这50个数据集均有全球流行的Python代码复现。该数据库弥补了国外学术网站难以和中国科研用户接地气的痛点,为中国国内用户提供优秀,真实案例和复现代码,用于发布各种核心期刊,小论文。
《Python风控建模实战案例数据库》由重庆未来之智信息技术咨询服务限公司的Toby老师建立。该数据库拥有大量私有数据库,专门用于规避查重,为985,211高校3-5%查重率的用户提供了福音。
《Python风控建模实战案例数据库》部分案例展示如下



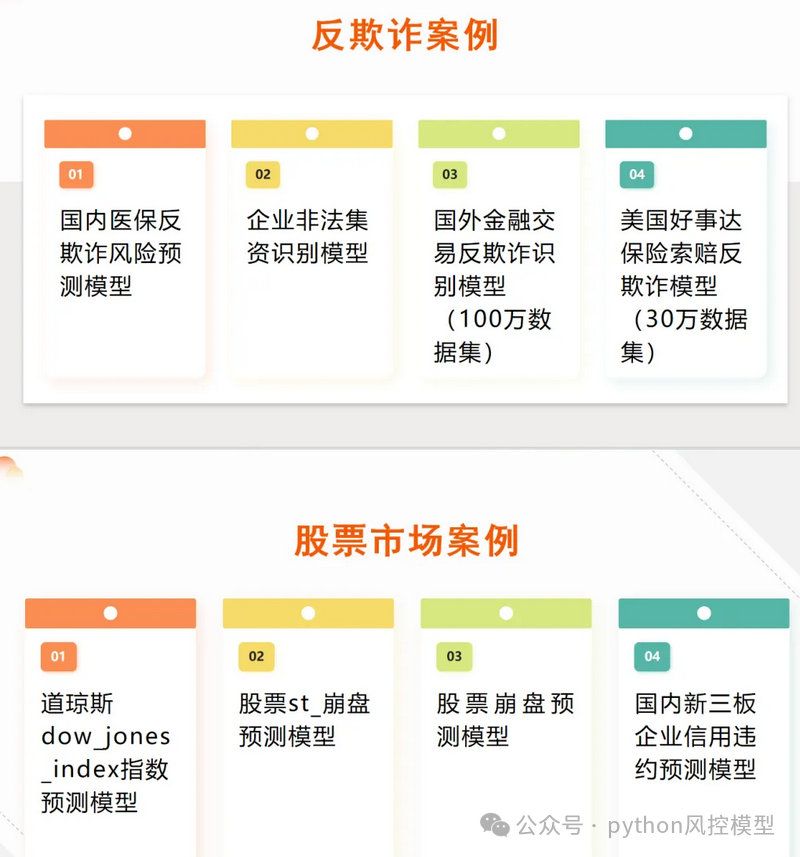

版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
这篇关于科研论文必须要了解的25个学术网址的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







