本文主要是介绍Transformer直接预测完整数学表达式,推理速度提高多个数量级,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
来自 Mata AI、法国索邦大学、巴黎高师的研究者成功让 Transformer 直接预测出完整的数学表达式。
转载自丨机器之心
符号回归,即根据观察函数值来预测函数数学表达式的任务,通常涉及两步过程:预测表达式的「主干」并选择数值常数,然后通过优化非凸损失函数来拟合常数。其中用到的方法主要是遗传编程,通过多次迭代子程序实现算法进化。神经网络最近曾在一次尝试中预测出正确的表达式主干,但仍然没有那么强大。
在近期的一项研究中,来自 Meta AI(Facebook)、法国索邦大学、巴黎高师的研究者提出了一种 E2E 模型,尝试一步完成预测,让 Transformer 直接预测完整的数学表达式,包括其中的常数。随后通过将预测常数作为已知初始化提供给非凸优化器来更新预测常数。

论文地址:https://arxiv.org/abs/2204.10532
该研究进行消融实验以表明这种端到端方法产生了更好的结果,有时甚至不需要更新步骤。研究者针对 SRBench 基准测试中的问题评估了该模型,并表明该模型接近 SOTA 遗传编程的性能,推理速度提高了几个数量级。
方法
Embedder
该模型提供了 N 个输入点 (x, y) ∈ R^(D+1),每个输入点被表征为 d_emb 维度的 3(D + 1) 个 token。随着 D 和 N 变大,这会导致输入序列很长(例如,D = 10 和 N = 200 时有 6600 个 token),这对 Transformer 的二次复杂度提出了挑战。
为了缓解这种情况,该研究提出了一个嵌入器( embedder )来将每个输入点映射成单一嵌入。嵌入器将空输入维度填充(pad)到 D_max,然后将 3(D_max+1)d_emb 维向量馈入具有 ReLU 激活的 2 层全连接前馈网络 (FFN) 中,该网络向下投影到 d_emb 维度,得到的 d_emb 维的 N 个嵌入被馈送到 Transformer。
该研究使用一个序列到序列的 Transformer 架构,它有 16 个 attention head,嵌入维度为 512,总共包含 86M 个参数。像《 ‘Linear algebra with transformers 》研究中一样,研究者观察到解决这个问题的最佳架构是不对称的,解码器更深:在编码器中使用 4 层,在解码器中使用 16 层。该任务的一个显著特性是 N 个输入点的排列不变性。为了解释这种不变性,研究者从编码器中删除了位置嵌入。
如下图 3 所示,编码器捕获所考虑函数的最显著特征,例如临界点和周期性,并将专注于局部细节的短程 head 与捕获函数全局的长程 head 混合在一起。
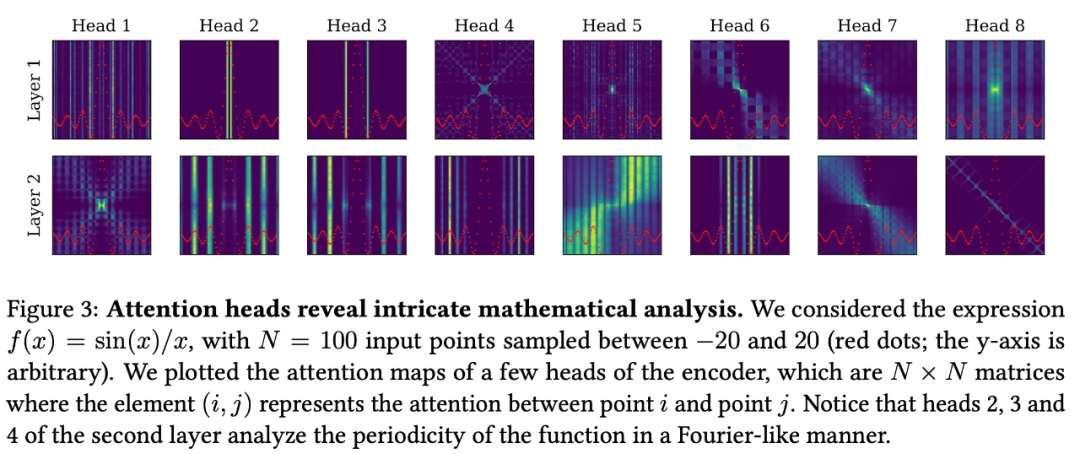
训练
该研究使用 Adam 优化器优化交叉熵损失,在前 10000 步中将学习率从 10^(-7) 提升到 2.10^(-4),然后按照论文《 Attention is all you need 》中的方法将其衰减为步数的平方根倒数(inverse square root)。该研究提供了包含来自同一生成器的 10^4 个样本的验证集,并训练模型,直到验证集的准确率达到饱和(大约 50 个 epoch 的 3M 个样本)。
输入序列长度随点数 N 显著变化;为了避免浪费填充,该研究将相似长度的样本一起批处理,确保一个完整的批处理包含至少 10000 个 token。
实验结果
该研究不仅评估了域内准确性,也展示了在域外数据集上的结果。
域内性能
表 2 给出了该模型的平均域内结果。如果不进行修正,E2E 模型在低精度预测(R^2 和 Acc_0.1 指标)方面优于在相同协议下训练的 skeleton 模型,但常数预测中存在的错误会导致在高精度(Acc_0.001)下的性能较低。
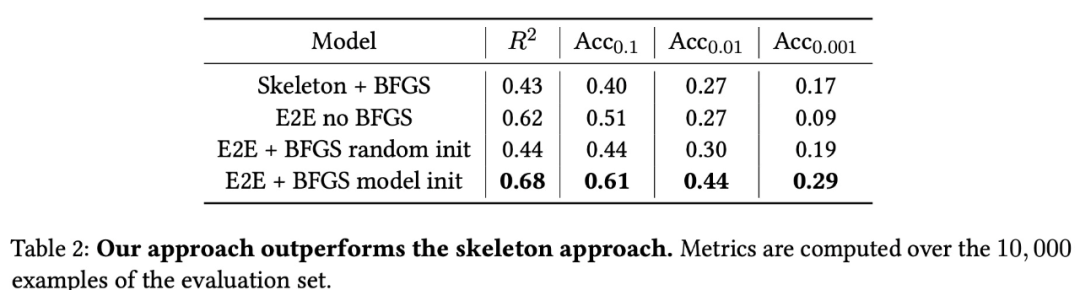
修正之后的程序显著缓解了这个问题,让 Acc_0.001 提升了三倍,同时其他指标也有所改进。
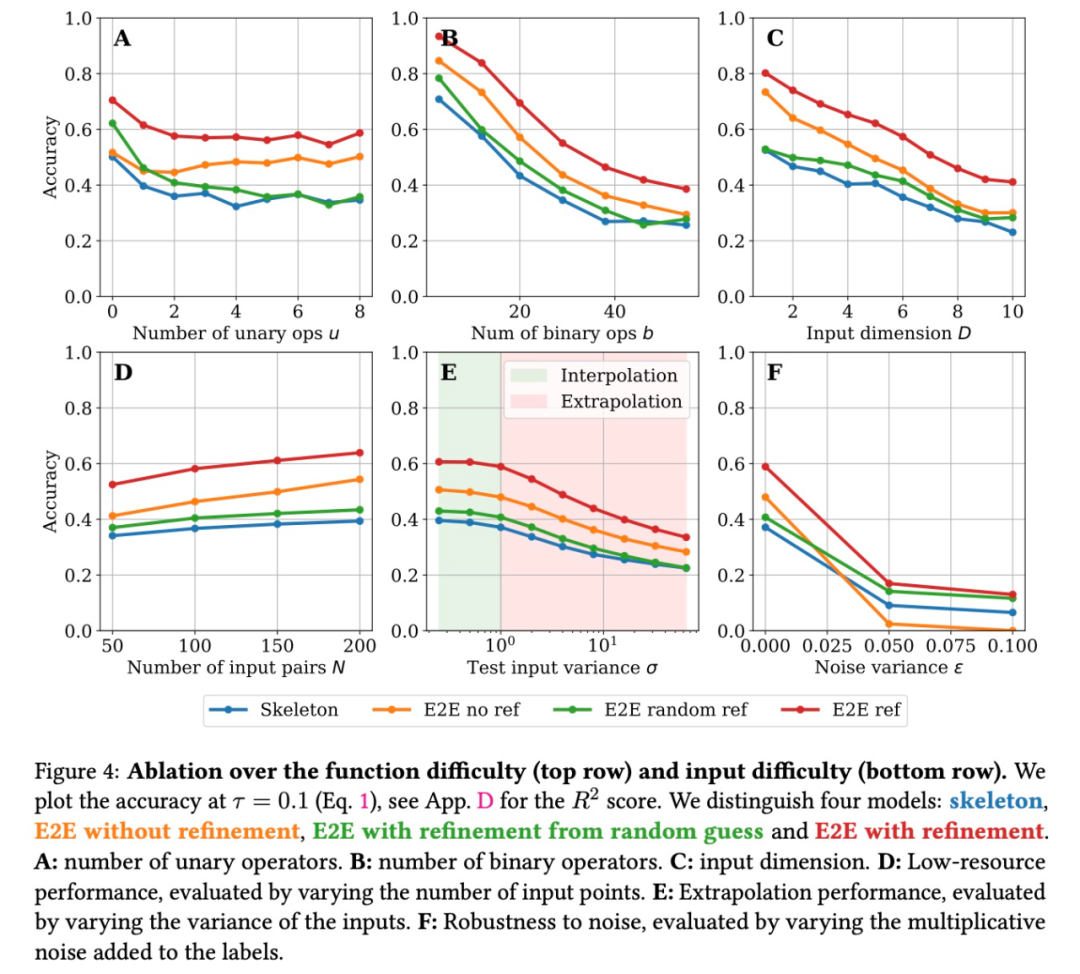
图 4A、B、C 给出了 3 个公式难度指标的消融实验结果(从左到右):一元算子的数量、二元算子的数量和输入维数。正如人们所预料的那样,在所有情况下,增加难度系数会降低性能。这可能会让人认为该模型在输入维度上不能很好地扩展,但实验表明,与并发方法相比,该模型在域外数据集上的扩展性能非常好,如下图所示。
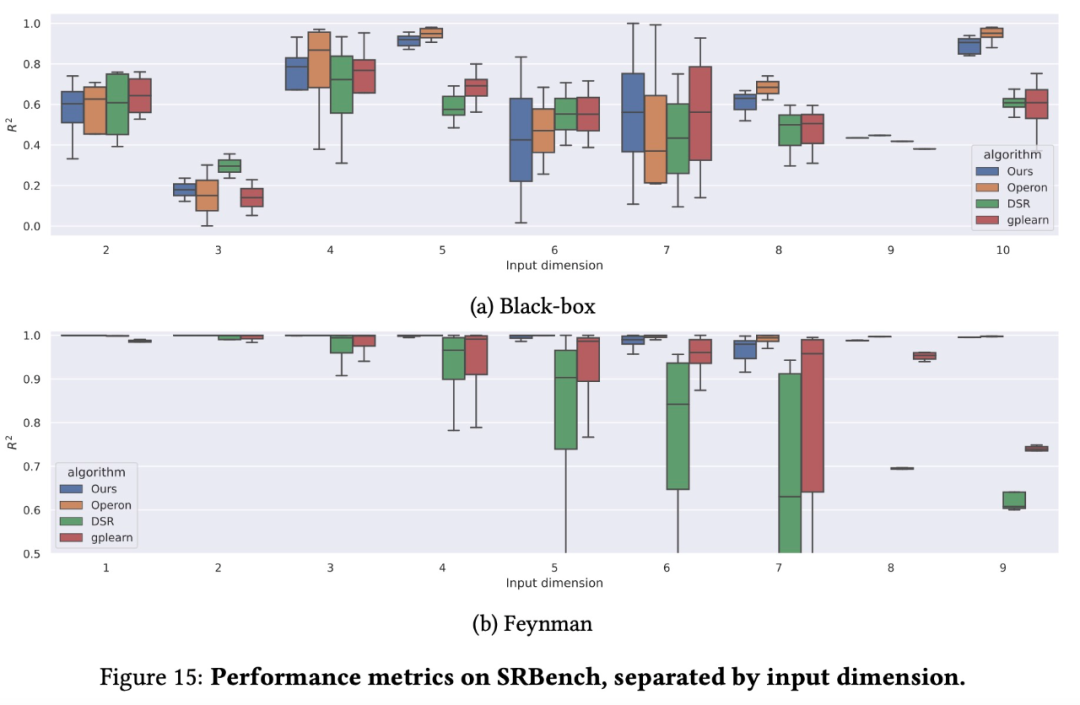
图 4D 显示了性能与输入模型的点数 N 之间的关系。在所有情况下,性能都会提高,但 E2E 模型比 skeleton 模型更显著,这证明大量数据对于准确预测表达式中的常数是非常重要的。
外推和稳健性。如图 4E 所示,该研究通过改变测试点的规模来检查模型内插 / 外推的能力:该研究没有将测试点归一化为单位方差,而是将它们归一化为 σ。随着 σ 的增加,性能会下降,但是即使远离输入(σ = 32),外推性能仍然不错。
最后,如图 4F 所示,研究者检查了使用方差 σ 的乘性噪声(multiplicative noise)对目标 y 的影响:y → y(1 + ξ), ξ ∼ N (0, ε)。这个结果揭示了一些有趣的事情:如果不进行修正,E2E 模型对噪声的稳健性不强,实际上在高噪声下性能比 skeleton 模型差。这显示了 Transformer 在预测常数时对输入的敏感程度。修正之后 E2E 模型的稳健性显著提高,但将常数初始化为估计值的影响较小,因为常数的预测被噪声破坏了。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
这篇关于Transformer直接预测完整数学表达式,推理速度提高多个数量级的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


