本文主要是介绍24最新Stable Diffusion入门指南(看完必会)超全面,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
今天写这个帖子是带大家了解一款强大的 AI 绘画工具——Stable Diffusion,可以帮你解决很多应用层面的[AI控图]问题。
关于 Stable Diffusion 的内容很多,在本篇教程里,我会先为你介绍 Stable Diffusion 模型的运行原理、发展历程和相较于其他 AI 绘图应用的区别。
一、关于 Stable Diffusion 的几个名词
相信大家或多或少有看到过以下几个名词,因此有必要先给大家做个区分,以便你更好理解后续教程的内容。
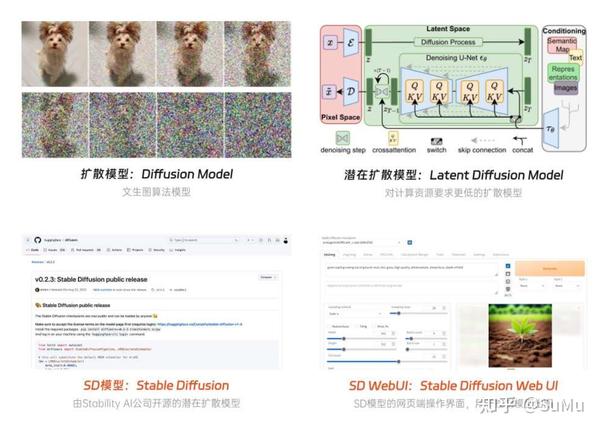
Stable Diffusion的几个名词
- Diffusion Model:[扩散模型],一款支持文本生成图像的算法模型,目前市面上主流的 DALL E、Midjourney、Stable Diffusion 等 AI 绘画工具都是基于此底层模型开发的
- Latent Diffusion Model:即[潜在扩散模型,基于上面扩散模型基础上研制出的更高级模型,升级点在于图像图形生成速度更快,而且对计算资源和内存消耗需求更低
- Stable Diffusion:简称SD模型,其底层模型就是上面的潜在扩散模型,之所以叫这个名字是因为其研发公司名叫Stability AI,相当于品牌冠名了
- Stable Diffusion Web Ul:简称SD WebUI,用于操作上面Stable Diffusion模型的[网页端]界面,通过该操作系统就能控制模型出图,而无需学习代码
在本系列的教程中,我们需要学习的内容就是使用 SD WebUI 来调用 Stable Diffusion 模型生成图像。
本次教程将使用AI绘画工具 Stable Diffusion 进行讲解,如还未安装SD的小伙伴可以扫描免费获取哦~
二、Stable Diffusion 模型的运行原理
在上面介绍的几个概念中,你会发现都包含了 Diffusion 扩散模型这个词,所以我们先从它开始讲起。
Diffusion 模型是图像生成领域中应用最广的生成式模型之一,除此之外市面上还有生成对抗模型(GAN)、[变分自动编码器](VAE)、流模型(Flow based Model)等其他模型,它们都是基于深度学习为训练方式的模型。

运行原理
扩散模型之所以用 Diffusion 来命名,因为它的运作过程就是向训练图像不断地添加噪声,直到变为一张无意义的纯噪声图,再逐步恢复的过程。
其中加噪的过程就像在干净的水中滴了一滴墨汁,颜料会逐渐向整个水体扩散,直至整个水体变浑。如果你之前有尝试过 AI 绘画,会发现整个绘图过程就是从一张模糊的噪声图,逐渐变为清晰的图像,而这就是逆向降噪的过程。

逆向降噪过程
以上是潜在扩散模型的工作原理,但 Stable Diffusion 模型并不是单一的文生[图模型],而是多个模型组成的运作系统,其中的技术可以拆解为 3 个结构来看:

SD结构
- ClipText [文本编码器]:用于解析提示词的 Clip 模型
- Diffusion 扩散模型:用于生成图像的 U-Net 和 Scheduler
- VAE 模型:用于压缩和恢复的图像[解码器]
是不是看到这里已经有点头晕了,别担心,这里只需简单了解每一部分的功能即可,在后续 WebUI 的功能介绍中我们还和他们有更深的接触,到时候就更容易理解每一部分的概念了。
三、Stable Diffusion背景介绍
1. Stable Diffusion 是如何诞生的
下面,我再为大家介绍下 Stable Diffusion 的发展历程,有助于你更深层次的了解这款 AI 绘画工具。
如今提到 Stable Diffusion,就不得不提 Stability AI,这家[独角兽公司]在去年以十亿美元的估值一跃成为这过去半年中 AIGC 行业的黑马。 Stable 这个词其实是源于其背后的赞助公司 Stability。相较于 Latent Diffusion 模型,改进后的 Stable Diffusion 采用了更多的数据来训练模型,用于训练的图像尺寸也更大,包括文本编码也采用了更好的 CLIP 编码器。在实际应用上来说,Stable Diffusion [生成模型]会更加准确,且支持的图像分辨率也更高,比单一的 Latent Diffusion 模型更加强大。
在 Discord 上进行短期内测后,Stable Diffusion 于 8 月 22 日正式开源。后面的事情大家都知道了,就在推出的短短几天后,Stability 拿到了 1 亿美元的融资,让这家年轻企业直接获得了约 10 亿美元的估值,可谓是名利双收。
2. 从开源到百花齐放
对于 Stability 的商业行为我们不做过多点评,但他们在开源这条路上确实践行的很好,正如他们官网首页所说:AI by the people, for the people—AI取之于民,用之于民。

Stability官网
起初,Stable Diffusion 和 Midjourney 一样先是在 Discord 上进行了小范围的免费公测。随后在 22 年的 8 月 22 日,关于 Stable Diffusion 的代码、模型和权重参数库在 Huggingface 的 Github 上全面开源,至此所有人都可以在本地部署并免费运行 Stable Diffusion。
有朋友可能对开源这个词比较陌生,这里简单介绍下:开源指的是[开放源代码],即所有用户都可以自由学习、修改以及传播该软件的代码信息,并且不用支付任何费用。举个不太恰当的比喻,就像是一家餐厅把自己辛苦研究的[秘制菜谱],向全社会公布,任何人都可以拿去自由使用,不管是自己制作品尝,还是由此开一家新餐厅都可以。但这里有个问题,并不是每个人都是厨师,更不用说做这种需要繁琐环境部署和基础设施搭建的“秘制菜”。
开源后的 Stable Diffusion 文件,起初只是一串你我这样小白都看不懂的源代码,更不用说上手体验。但伴随着越来越多开发者的介入,Stable Diffusion 的上手门槛逐渐降低,开始走向群众视野,它的生态圈逐渐发展为商业和社区 2 个方向。
这些应用在很大程度上都进行了简化和设计,即使是小白用户也可以快速上手,当然缺点就是基本都要付费才能使用,而且很难针对个人做到[功能定制化]。
另一方面,开源的 Stable Diffusion 社区受到了广泛民间开发者大力支持,众多为爱发电的程序员自告奋勇的为其制作方便操控的 GUI 图形化界面(Graphical User Interface)。其中流传最广也是被公认最为方便的,就是由越南超人 AUTOMATIC1111 (下文统一用 A41 代称)开发的 WebUI,而这正是前面提到的 Stable Diffusion WebUI,后面的教程内容都是基于该程序展开的。

AUTOMATIC1111研发的webui,是目前最火的SD界面之一
它集成了大量代码层面的繁琐应用,将 Stable Diffusion 的各项绘图参数转化成可视化的选项数值和操控按钮。如今各类开源社区里 90%以上的拓展应用都是基于它而研发的。
当然,除了 WebUI 还有一些其他的 GUI 应用,比如 Comfy UI 和 Vlad Diffusion 等,不过它们的应用场景更为专业和小众
四、Stable Diffusion 的特点
目前,市面上绝大多数商业级 AI 绘画应用都是采用开源的 Stable Diffusion 作为研发基础,当然也有一些其他被大众熟知的 AI 绘画工具,比如最受欢迎的 Midjourney 和 OpenAI 公司发布的 [DALL·E2]。但不可否认的是,开源后的 Stable Diffusion 在实际应用上相较其他 AI 绘画工具存在巨大优势:
1. 可拓展性强
首先最关键的一点就是极其丰富的拓展性。得益于官方免费公开的论文和模型代码,任何人都可以使用它来进行学习和创作且不用支付任何费用。光是在 A41 WebUI 的说明文档中,目前就已经集成了 110 多个[扩展插件]的功能介绍。
从局部重绘到人物姿势控制,从图像高清修复和到线稿提取,如今的 Stable Diffusion 社区中有大量不断迭代优化的图像调整插件以及免费分享的模型可以使用。而对于专业团队来说,即使社区里没有自己满意的,也可以通过自行训练来定制专属的绘图模型。
在 Midjourney 等其他商用绘画应用中,无法精准控图和图像分辨率低等问题都是其普遍痛点,但这些在 Stable Diffusion 中通过 ControlNet 和 UpScale 等插件都能完美解决。如果单从工业化应用角度考虑,如今的 Stable Diffusion 在 AI 绘画领域毫无疑问是首选工具。

SD精准控图
2. 出图效率高
其次是其高效的出图模式。使用过 Midjourney 的朋友应该都有体验过排队等了几分钟才出一张图的情况,而要得到一张合适的目标图我们往往需要试验多次才能得到,这个试错成本就被进一步拉长。其主要原因还是由于商业级的 AI 应用都是通过访问云服务器进行操作,除了排队等候服务器响应外,网络延迟和资源过载都会导致绘图效率的降低。
而部署在本地的 Stable Diffusion 绘图效率完全由硬件设备决定,只要显卡算力跟得上,甚至能够实现 3s 一张的超高出图效率。
3. 数据安全保障
同样是因为部署在本地,Stable Diffusion 在数据安全性上是其他[在线绘画]工具无法比拟的。商业化的绘画应用为了运营和丰富数据,会主动将用户的绘图结果作为案例进行传播。但 Stable Diffusion 所有的绘图过程完全在本地进行,基本不用担心信息泄漏的情况。
总结来说,Stable Diffusion 是一款图像生产+调控的集合工具,通过调用各类模型和插件工具,可以实现更加精准的商业出图,加上数据安全性和可扩展性强等优点,Stable Diffusion 非常适合 AI 绘图进阶用户和专业团队使用。
而对于具备极客精神的 AI 绘画爱好者来说,使用 Stable Diffusion 过程中可以学到很多关于模型技术的知识,理解了 Stable Diffusion 等于就掌握了 AI 绘画的精髓,可以更好的[向下兼容]其他任意一款低门槛的绘画工具。
五、最后想说
AIGC(AI Generated Content)技术,即人工智能生成内容的技术,具有非常广阔的发展前景。随着技术的不断进步,AIGC的应用范围和影响力都将显著扩大。以下是一些关于AIGC技术发展前景的预测和展望:
1、AIGC技术将使得内容创造过程更加自动化,包括文章、报告、音乐、艺术作品等。这将极大地提高内容生产的效率,降低成本。2、在游戏、电影和虚拟现实等领域,AIGC技术将能够创造更加丰富和沉浸式的体验,推动娱乐产业的创新。3、AIGC技术可以帮助设计师和创意工作者快速生成和迭代设计理念,提高创意过程的效率。
未来,AIGC技术将持续提升,同时也将与人工智能技术深度融合,在更多领域得到广泛应用。感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程。
对于从来没有接触过AI绘画的同学,我已经帮你们准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
AIGC学习必备工具和学习步骤
工具都帮大家整理好了,安装就可直接上手
现在AI绘画还是发展初期,大家都在摸索前进。
但新事物就意味着新机会,我们普通人要做的就是抢先进场,先学会技能,这样当真正的机会来了,你才能抓得住。
如果你对AI绘画感兴趣,我可以分享我在学习过程中收集的各种教程和资料。

学完后,可以毫无问题地应对市场上绝大部分的需求。
这份AI绘画资料包整理了Stable Diffusion入门学习思维导图、Stable Diffusion安装包、120000+提示词库,800+骨骼姿势图,Stable Diffusion学习书籍手册、AI绘画视频教程、AIGC实战等等。
【Stable Diffusion安装包(含常用插件、模型)】
【AI绘画12000+提示词库】
【AI绘画800+骨骼姿势图】

【AI绘画视频合集】
还有一些已经总结好的学习笔记,可以学到不一样的思路。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这篇关于24最新Stable Diffusion入门指南(看完必会)超全面的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




