本文主要是介绍告别复杂编程,低代码平台如何简化列表页多模型数据配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在现代企业管理和信息系统建设中,随着业务复杂度的不断提升,单一数据模型往往难以满足复杂的数据展示需求。特别是在构建企业级应用或管理平台时,经常需要在一个界面上综合展示来自多个数据模型的信息,以便用户能够更全面地理解业务状态,快速做出决策。这种需求在客户关系管理(CRM)、企业资源规划(ERP)、供应链管理(SCM)等系统中尤为常见。
如何在列表页显示多个模型数据
这里我以JVS低代码平台为例来做个详细的介绍。
当我们需要在列表页中显示多个模型的字段数据时,可以在列表页中字段进行关联模型配置。
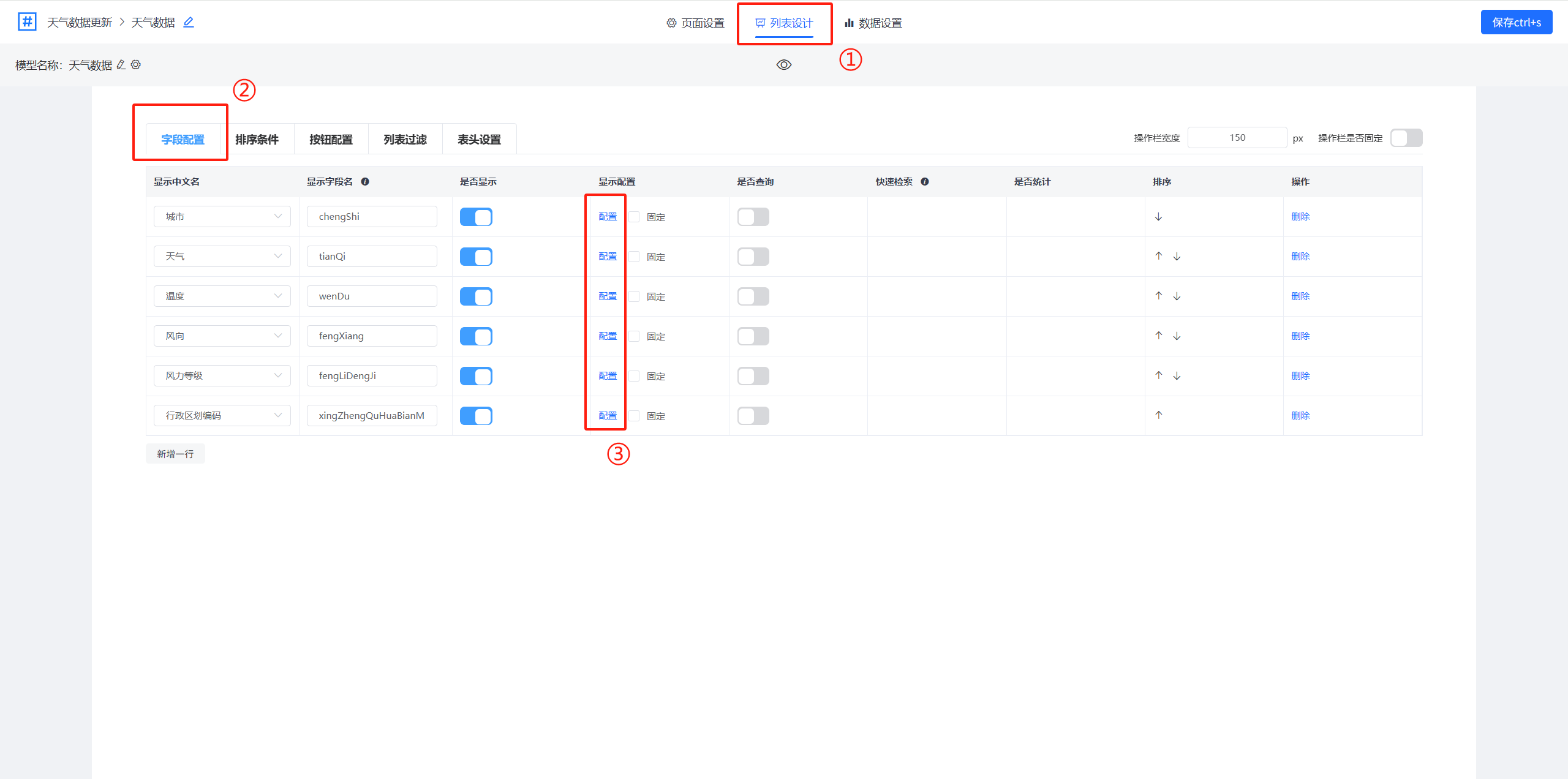
①第一步:进入列表页设计,切换到列表设计中。
②第二步:选择字段配置选项卡。
③第三步:选择字段的显示配置,在字段的显示配置中可以配置其他模型显示在此字段后。
在弹出的显示设置中需要对以下选项进行配置。
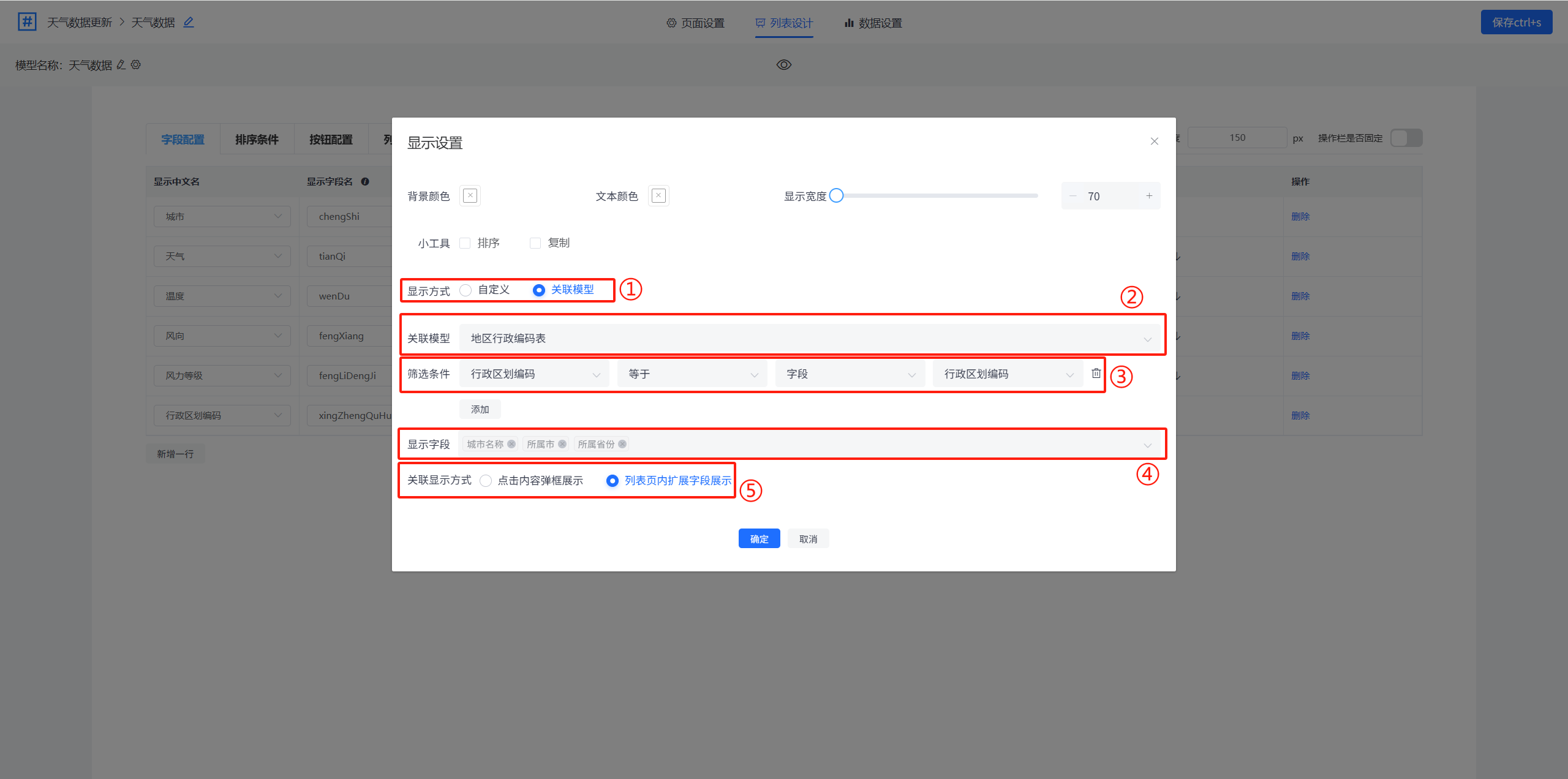
①显示方式:选择“关联模型”方式
②关联模型:选择要显示的数据模型
③筛选条件:设置筛选出的数据的条件
第一个下拉框选择关联模型的字段
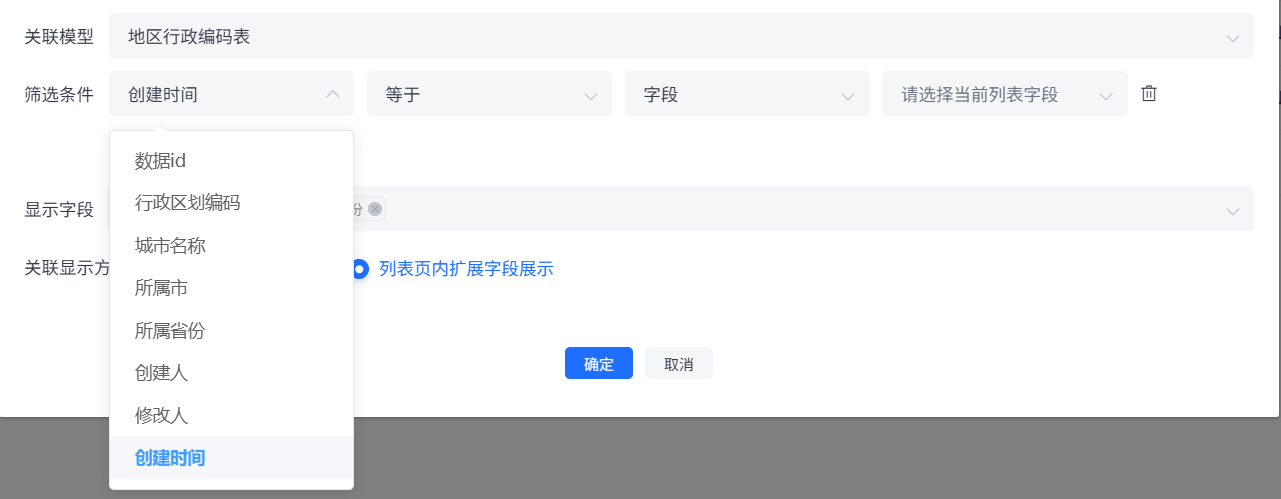
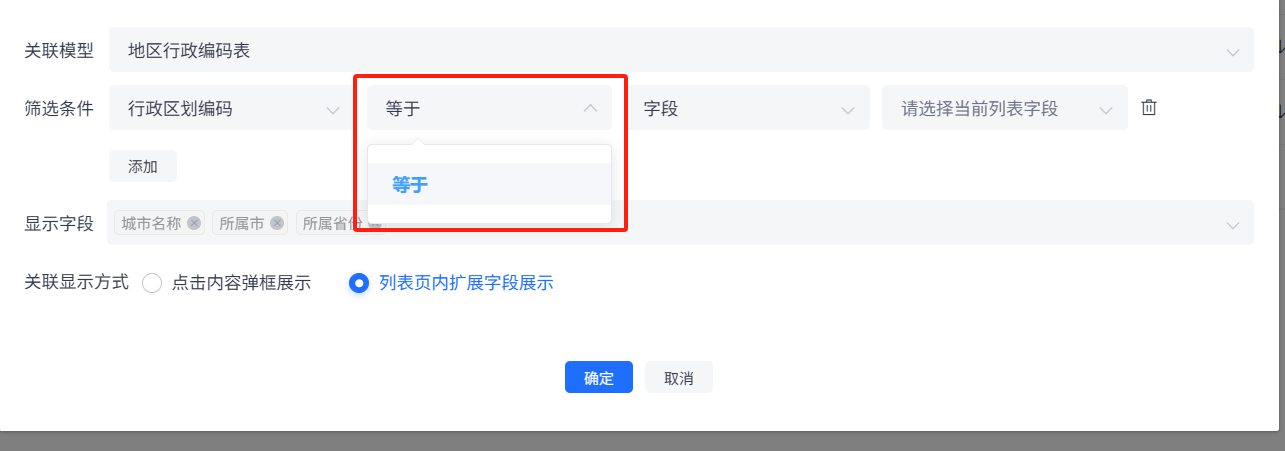
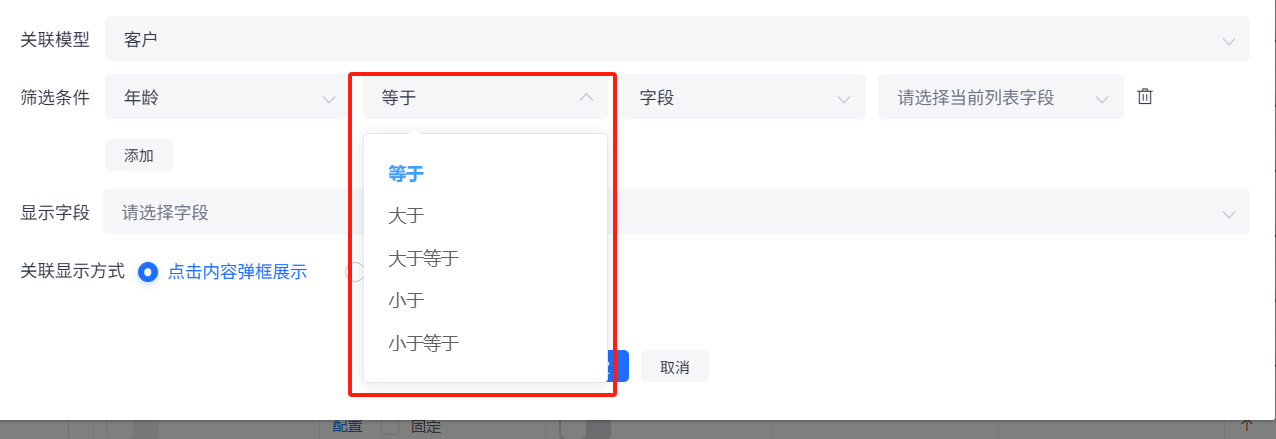
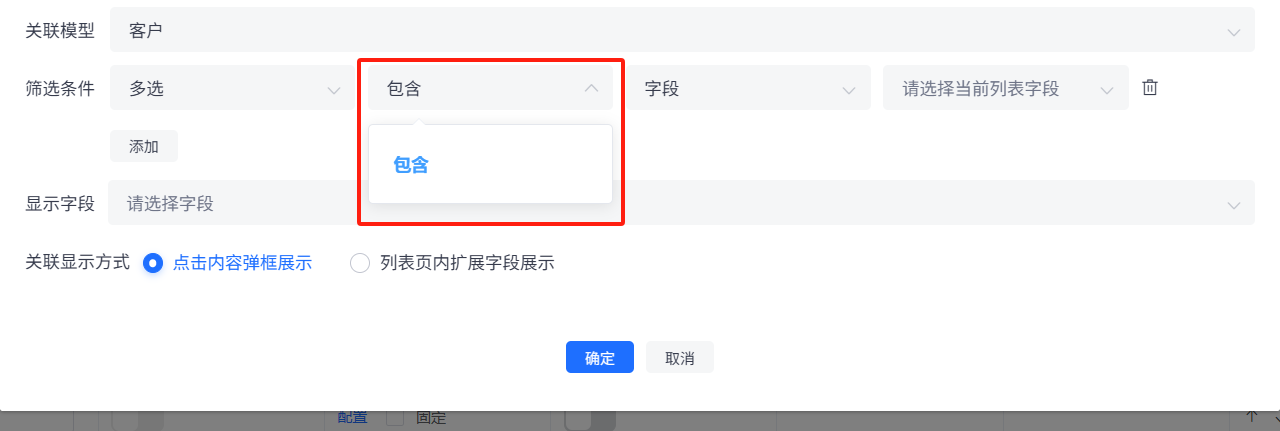
第二个判断条件根据前面字段的类型会有不同分为以下几种:
字符串:
数值、日期:
数组:
第三个和第四个下拉框联合使用,第三个选择的类型不同(字段或公式),会有不同的判断效果。
选择“字段”,那么最后一个下拉框需要选择当前列表模型(左上角查看当前列表模型)中的字段。
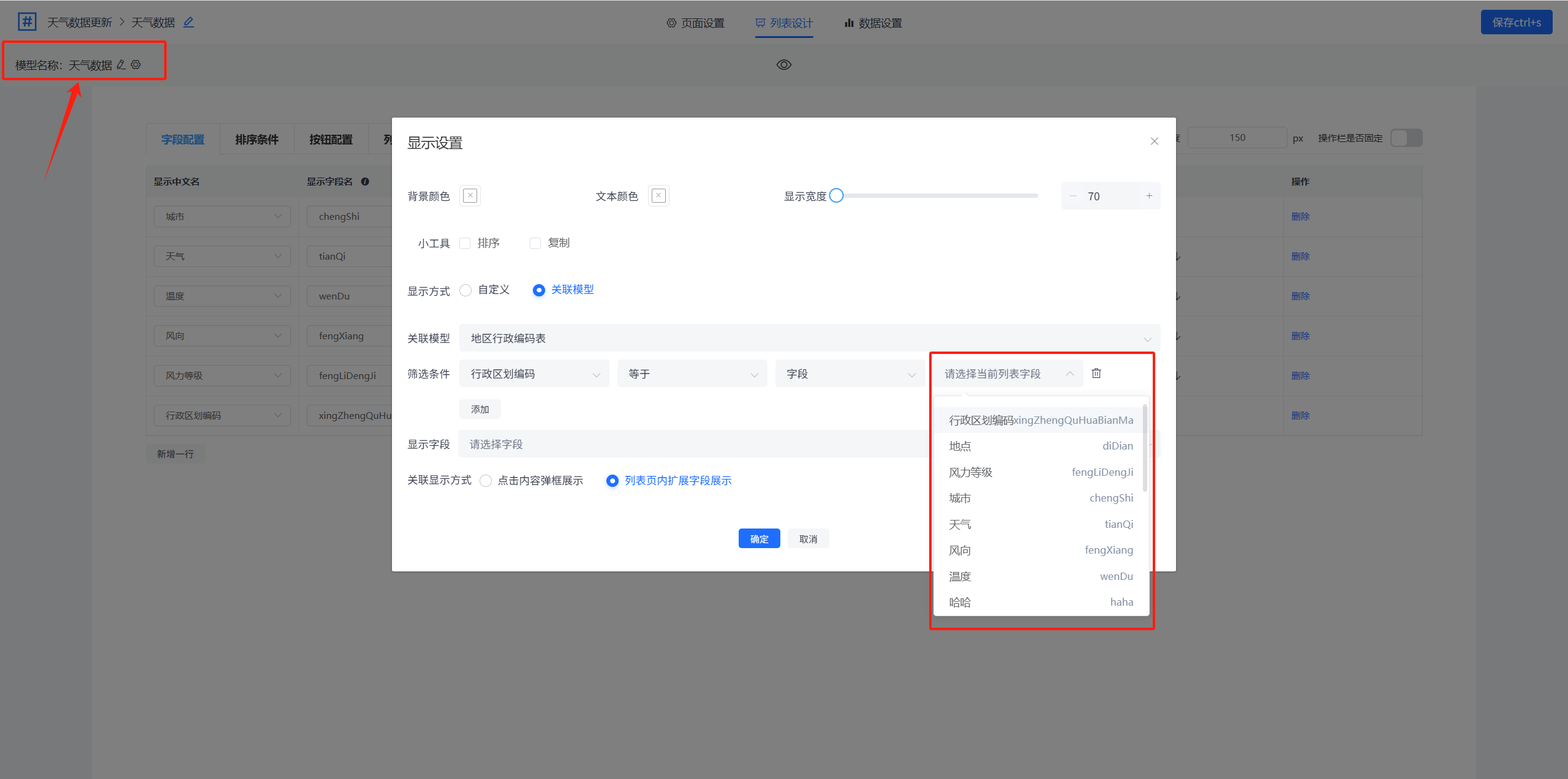
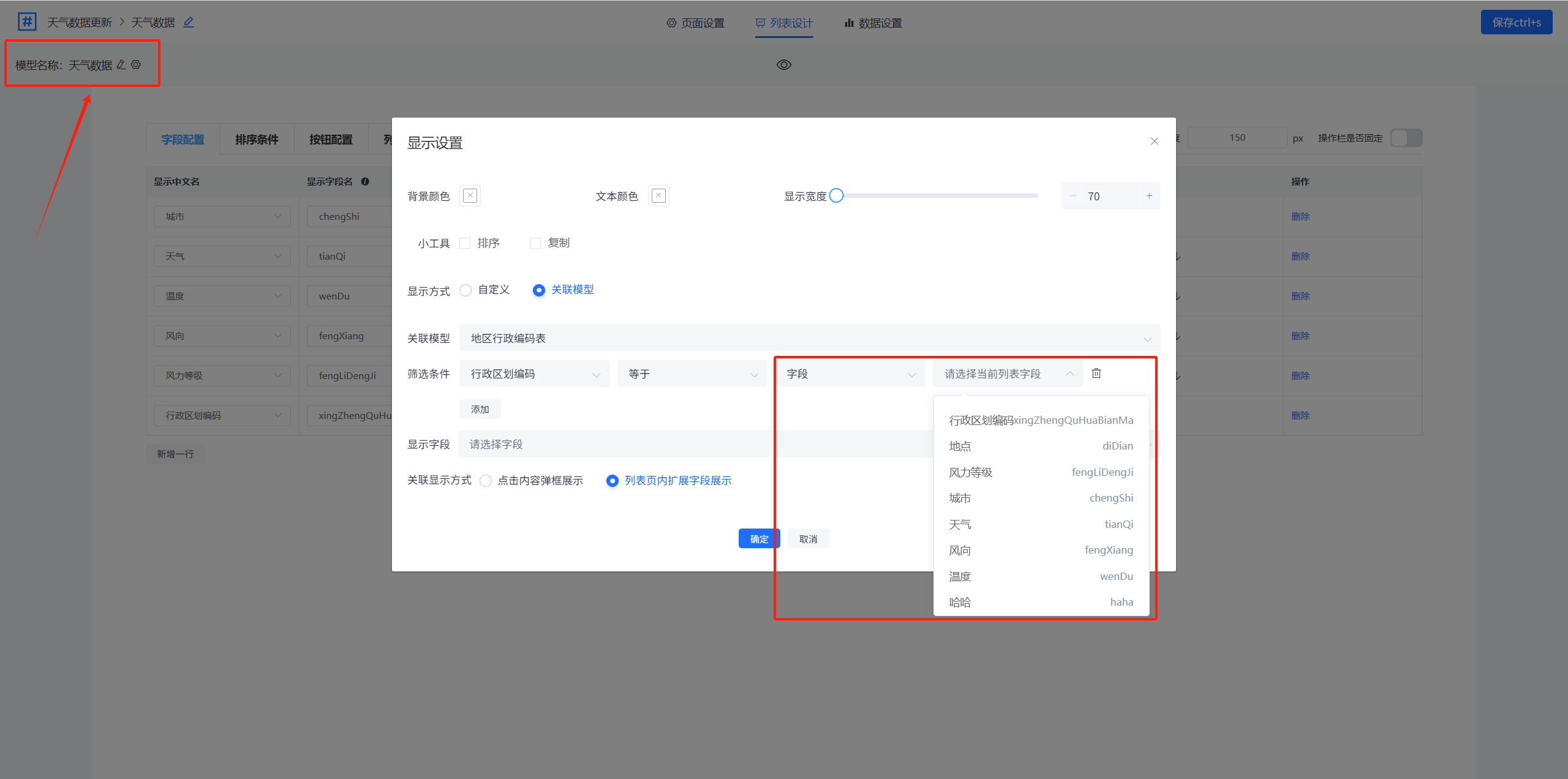
选择“公式”,那么可使用公式进行配置筛选条件值。
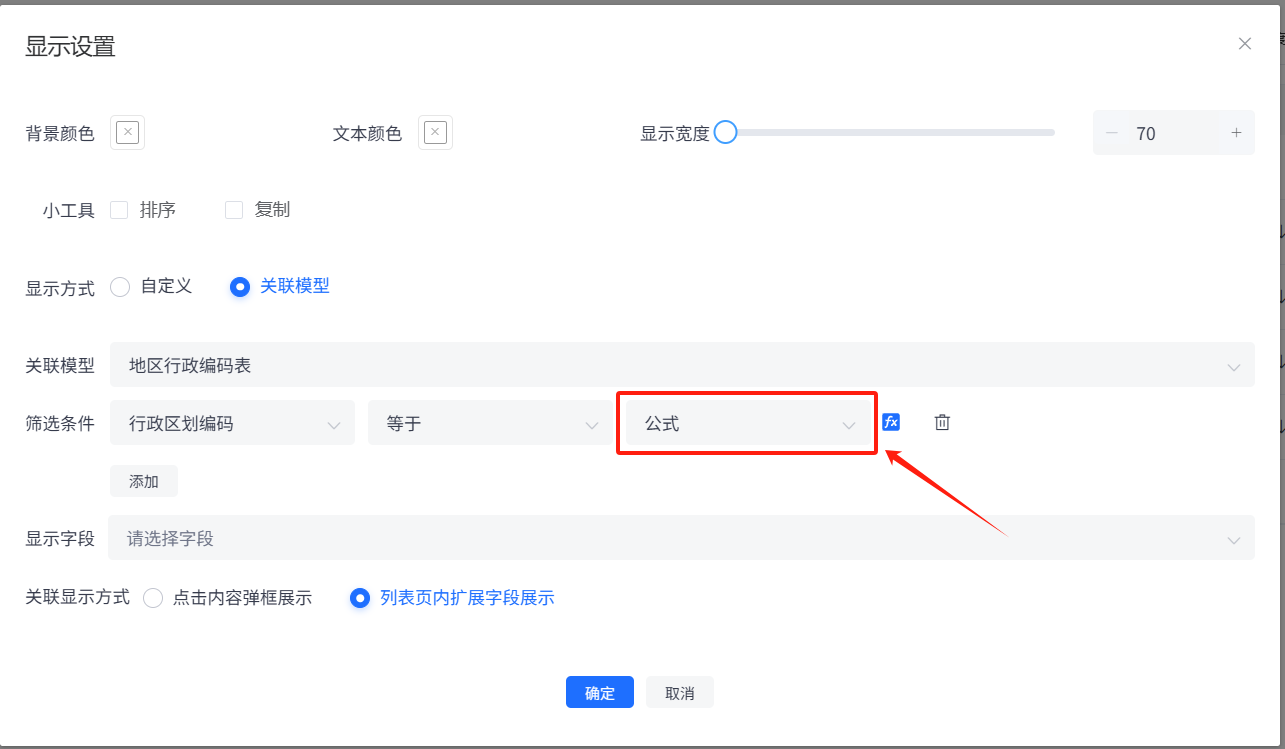
多个筛选条件联合筛选可点击“添加”继续新增筛选条件。
④显示字段:选择要显示的关联模型的字段
⑤关联显示方式:
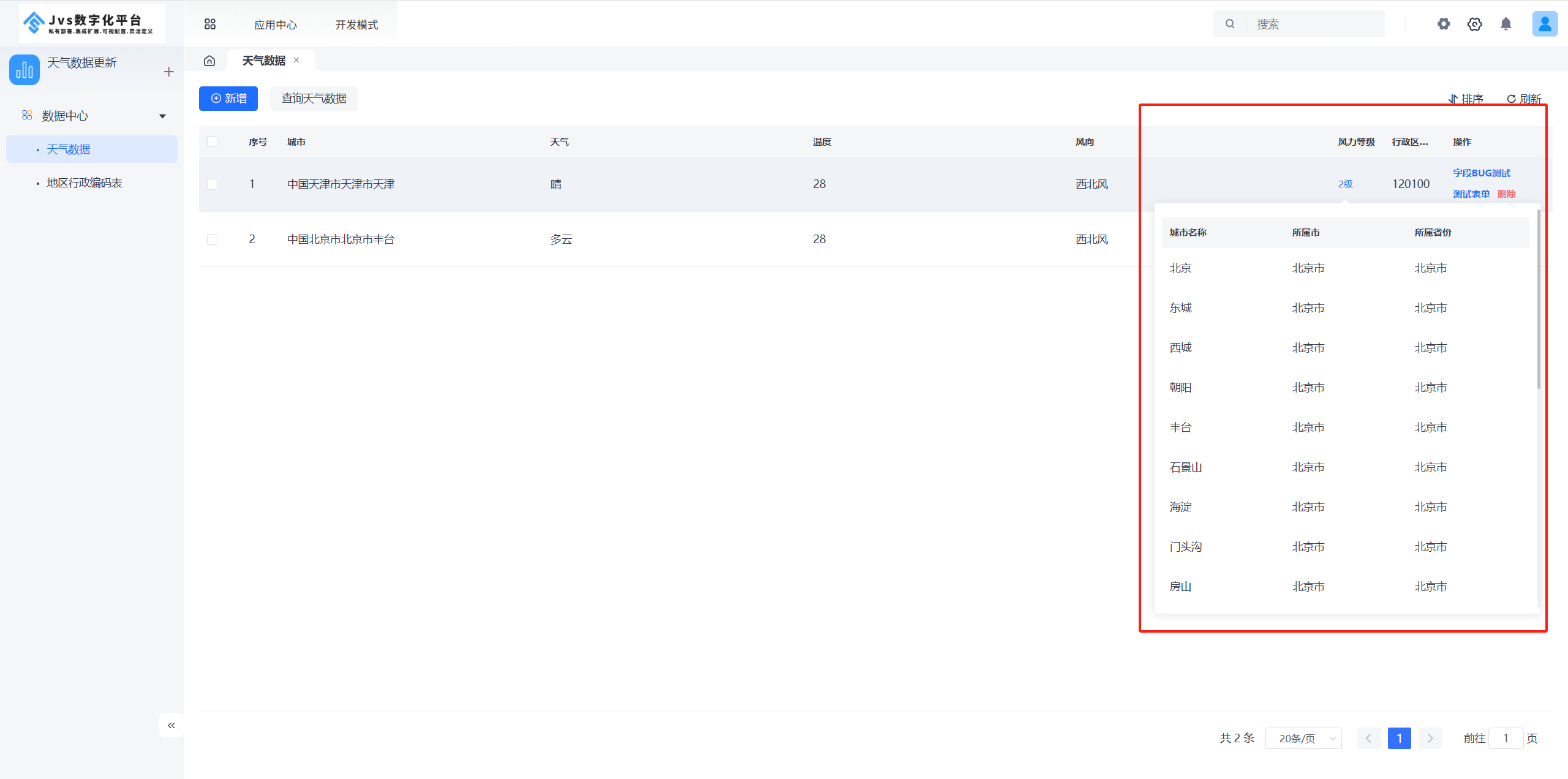
选择“点击内容弹框展示”,在列表页中点击字段值后弹框显示关联模型的多个数据:
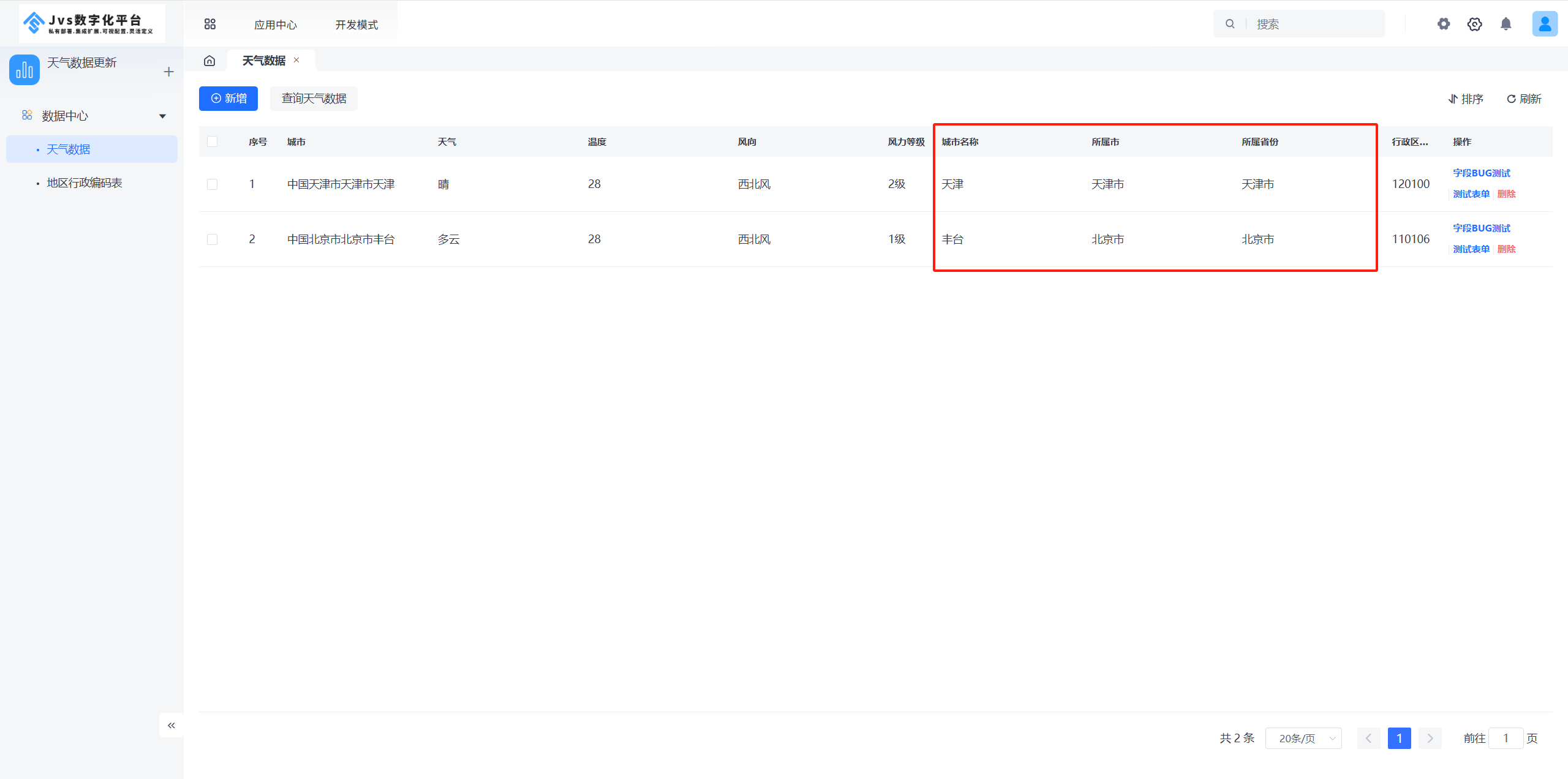
选择“列表页内扩展字段展示”,会将选择的其他模型字段直接展示在配置的字段后
无论是客户关系管理、企业资源规划还是供应链管理,这种跨模型的数据展示能力都为企业用户提供了更加全面、直观的业务视图,助力他们快速捕捉关键信息。在JVS低代码平台上灵活地在列表页中展示多个数据模型的信息,不仅简化了复杂业务系统的开发流程,还可以提升企业应用数据的整合能力。
在线demo:https://frame.bctools.cn
基础框架开源地址:https://gitee.com/software-minister/jvs
这篇关于告别复杂编程,低代码平台如何简化列表页多模型数据配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






