本文主要是介绍写一个程序,分析一个文本文件中各个词出现的频率,并且把频率最高的10个词打印出来。文本文件大约是30KB~300KB大小。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、解决思路
1、读取一个 txt 文本文件;
2、去掉停用词;
3、分词
4、统计文件里面每个词出现的次数;
5、进行排序,打印出频率最高的10个词。
二、编程语言:python;
三、测试文本:2.txt 大小:45.6 KB (45,582 字节)
四、程序代码, 放在rj1.py文件下
# -*- coding:utf-8 -*-import jieba
import sys
import jieba.analyse
from time import time
from operator import itemgetter
a = open('2.txt', 'r')
ss = a.read()
ss = ss.replace('\n','').replace(' ', '').replace('\t', '')
a.close()
stopwords = {}.fromkeys(['的', '在','我们','我','你们','你','和','这样','与','是','需要','可以','将','到','为','中',',','。','!','、',';',':','“','”','(',')','1','2','3','4','5','6','7','8','9','0','-',''])
segs = jieba.cut(ss,cut_all=False)
final = ''
for seg in segs:
seg = seg.encode('utf-8')
if seg not in stopwords:
final += seg
jieba.analyse.extract_tags(ss,20)
ff = jieba.cut(final,cut_all=False)
words = "/".join(ff)
#print words
def test():
iList = 10
count = {}
for word in words.split("/"):
if count.has_key(word):
count[word] = count[word] + 1
else:
count[word] = 1
aa = sorted(count.iteritems( ), key=itemgetter(1), reverse=True)[0:iList]
for a in aa:
print a[0],a[1]
# 调用
if __name__ == '__main__':
t1 = time()
test()
print time()-t1
五、运行结果如下:
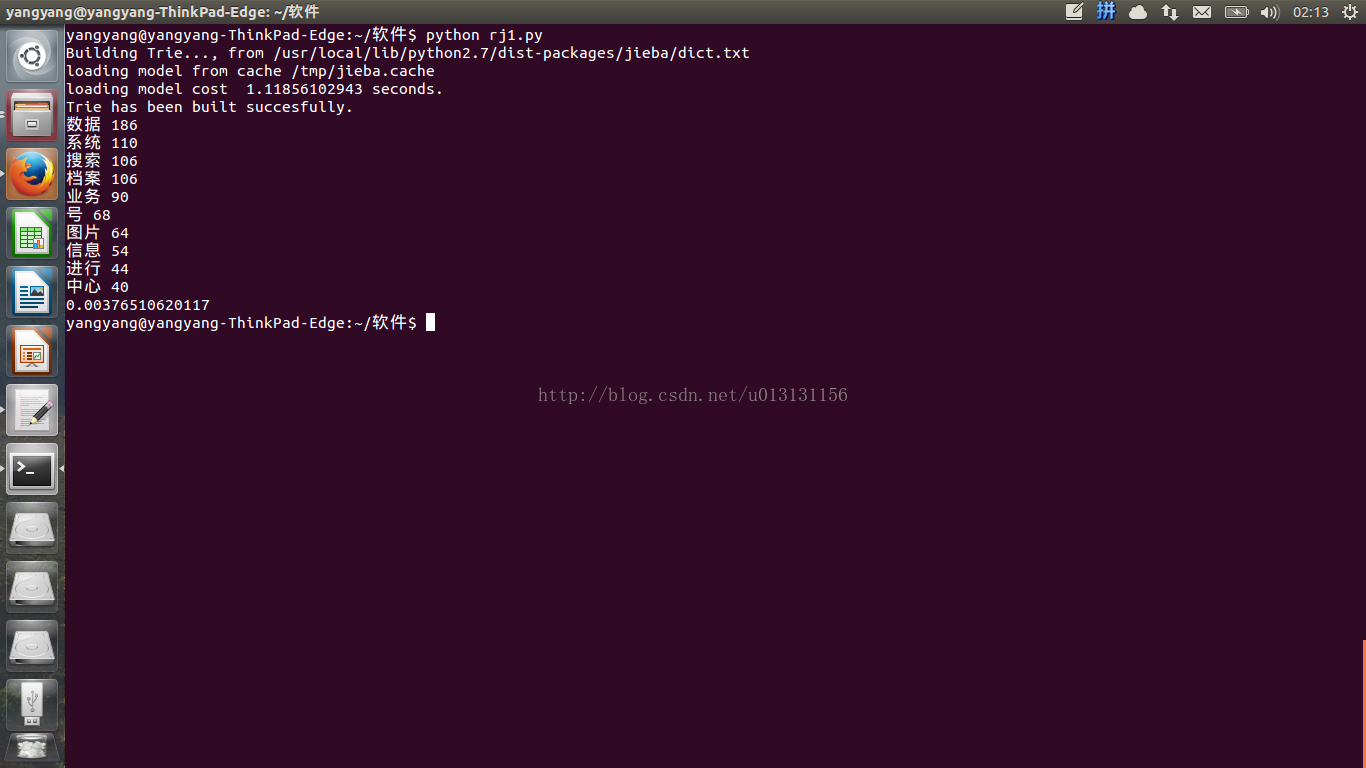
其中耗时:0.00376510620117秒。
其中耗时:0.00376510620117秒。
六、 改进
最开始我是把需要去掉的停用词一起写到python程序代码里了,后来我发现如果需要去掉的停用词很多,
那么就会影响程序的性能,于是我将需要去掉的停用词全部放在一个txt文本里面,并命名为zidian.txt。
改进后的代码如下, 放在rj2.py文件下:
# -*- coding:utf-8 -*-
import jieba
import sys
import jieba.analyse
from time import time
from operator import itemgetter
a = open('2.txt', 'r')
ss = a.read()
ss = ss.replace('\n','').replace(' ', '').replace('\t', '')
a.close()
b = open('zidian.txt', 'r')
stopwords = b.read()
b.close()
segs = jieba.cut(ss,cut_all=False)
final = ''
for seg in segs:
seg = seg.encode('utf-8')
if seg not in stopwords:
final += seg
jieba.analyse.extract_tags(ss,20)
ff = jieba.cut(final,cut_all=False)
words = "/".join(ff)
#print words
def test():
iList = 10
count = {}
for word in words.split("/"):
if count.has_key(word):
count[word] = count[word] + 1
else:
count[word] = 1
aa = sorted(count.iteritems( ), key=itemgetter(1), reverse=True)[0:iList]
for a in aa:
print a[0],a[1]
if __name__ == '__main__':
t1 = time()
test()
print time()-t1
运行结果如下:

其中耗时:0.0037579536438
这篇关于写一个程序,分析一个文本文件中各个词出现的频率,并且把频率最高的10个词打印出来。文本文件大约是30KB~300KB大小。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




