本文主要是介绍实战分享:利用两大在线平台实现自动化数据采集的技巧,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文将深入探讨如何运用两大主流在线平台,通过实战案例分享,揭示自动化数据采集的高效技巧。无需编程基础,也能快速掌握跨平台数据抓取秘籍,助力企业和个人提升市场竞争力与决策效率。
正文
在大数据时代背景下,信息的获取速度与质量直接影响着企业决策的效率与准确性。自动化数据采集,作为数据驱动策略的核心一环,正逐渐成为企业与个人的必备技能。本文将揭秘两大高效在线平台,助你轻松掌握数据采集的实战技巧,实现信息收集的自动化与智能化。
一、为什么选择在线平台实现自动化数据采集?
随着技术的发展,在线平台以其易用性、灵活性和强大的功能,成为数据采集的新宠。它们不仅支持海量任务调度,还能无缝对接各种三方应用集成,为用户提供从数据抓取到存储、分析的一站式解决方案。更重要的是,这些平台通常配备有直观的界面和详细的运行日志查看功能,即便是数据采集新手也能迅速上手。
二、实战平台一:全能型数据捕手
特色功能
智能爬虫构建:通过拖拽式界面,即便是非技术人员也能快速搭建复杂的数据抓取任务。
数据清洗与转换:内置的数据处理工具,让脏数据瞬间焕然一新,直接适配各类分析需求。
实时监控告警:任务执行状态一目了然,任何异常都能即时通知,确保数据采集不间断。
实战案例
某电商企业利用该平台,自动抓取竞争对手的商品价格与库存信息,结合自家数据进行动态调价,显著提升了市场竞争力。
三、实战平台二:开发者友好型数据挖掘工具
特色功能
API接口调用:丰富的API资源库,方便开发者根据特定需求定制数据抓取方案。
代码编辑器:支持多种编程语言,满足高级用户对数据采集逻辑的个性化定制。
数据可视化:采集后的数据可直接在平台上进行初步分析,图表展示一目了然。
实战案例
一家数据分析公司,利用该平台的API接口和代码编辑功能,构建了一套自动化报告系统,大大缩短了从数据采集到报告产出的周期。
四、技巧合辑:优化你的数据采集流程
明确目标:在开始之前,清晰定义你需要哪些数据,以及它们的来源。
定时调度:利用平台的计划任务功能,设定数据抓取频率,保持数据新鲜度。
数据验证:设置数据质量检查点,确保采集的数据准确无误。
安全合规:遵守目标网站的robots.txt规则,尊重数据隐私和版权。
五、推荐工具:集蜂云平台
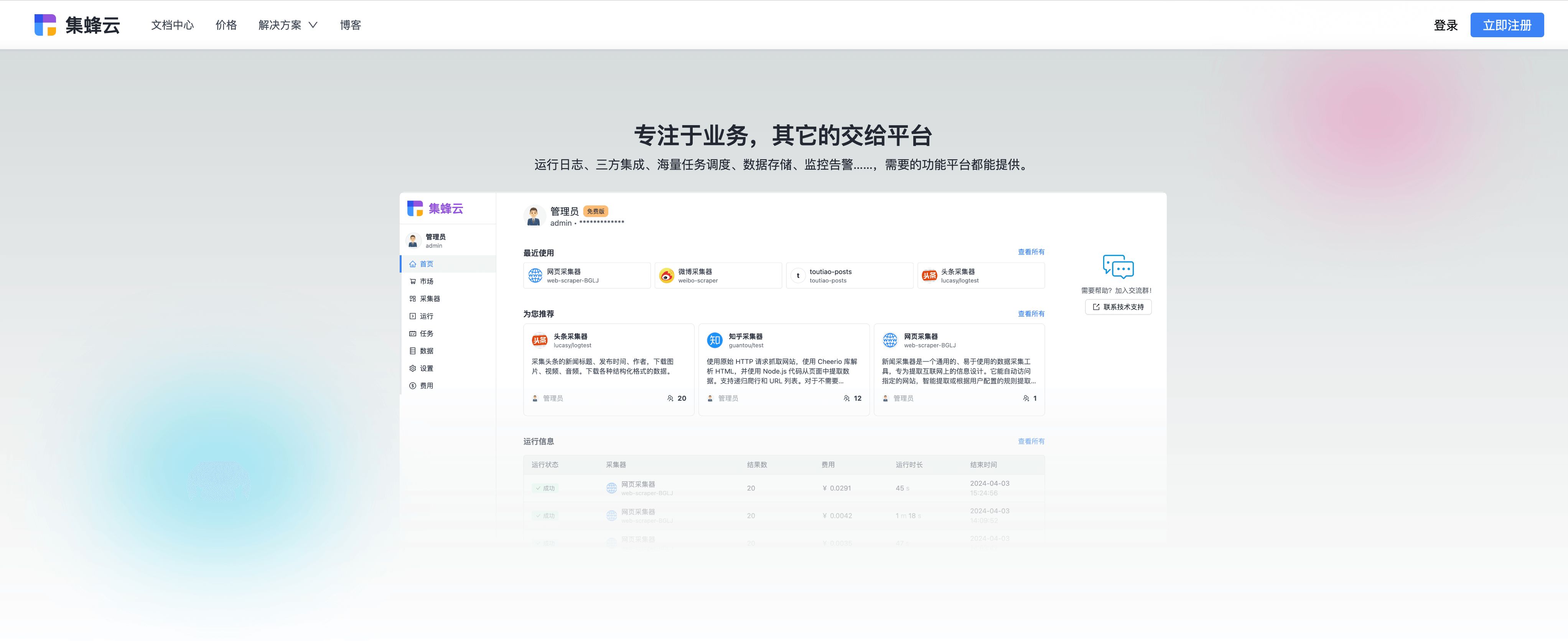
虽然本文未直接深入介绍集蜂云,但它是一个值得推荐的平台,能够提供高效、稳定的数据采集解决方案,特别是对于有海量任务调度需求的企业来说,其强大的功能和易用性不容忽视。
常见问题与解答
Q: 数据采集是否合法? A: 是的,只要遵守相关法律法规和网站政策(如robots协议),数据采集是合法的。
Q: 如何保证数据的安全性? A: 选择有加密传输、数据隔离措施的平台,并定期检查数据访问权限。
Q: 数据采集速度受限怎么办? Q: 调整采集频率,分散请求时间,或升级至更高级的服务套餐。
Q: 数据如何进行有效管理? A: 利用平台提供的数据分类、标签化功能,便于检索与分析。
Q: 如何处理数据更新频繁的问题? A: 设置自动化的数据更新任务,结合实时监控,确保数据时效性。
引用与推荐
“数据是新时代的石油。”——Clive Humby,英国数据科学家
结语
掌握正确的工具与技巧,自动化数据采集将不再是难题。上述两个平台及其实战案例,仅为冰山一角,探索更多可能性,还需实践出真知。不妨即刻行动,开启你的数据采集自动化之旅,用数据洞察未来,引领行业潮流。
这篇关于实战分享:利用两大在线平台实现自动化数据采集的技巧的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





