本文主要是介绍CMU15445 (Fall 2023) Project2 - EXTENDIBLE HASH INDEX 思路分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Task 1 - Read/Write Page Guards
- PageGuard函数实现
- 移动构造函数
- 移动赋值函数
- UpgradeRead/UpgradeWrite
- Drop
- 析构函数
- BufferPoolManager函数实现
- FetchPageBasic
- FetchPageRead/FetchPageWrite
- NewPageGuarded
- BUG调试
- Task2 - Hash Table Page
- Header Page
- Directory Page
- Bucket Page
- Task3 - Extendible Hashing Implementation
- GetValue
- Insert
- 分裂过程
- Remove
- 合并过程
- 写在最后
Task 1 - Read/Write Page Guards
这个task需要实现三个类,分别是BasicPageGuard、ReadPageGuard与WritePageGuard。看名字似乎BasicPageGuard是基类,但这里没有使用继承。它们之间只是has-a的关系,即:BasicPageGuard是ReadPageGuard与WritePageGuard的成员。
同时ReadPageGuard与WritePageGuard是BasciPageGuard的友元类,可以访问BasicPageGuard的任意成员。
为什么要实现这三个类?在Project1中,我们实现了Buffer Pool,DBMS想要获取内存资源必须经过Buffer Pool。Buffer Pool以页为基本单位,对外提供内存资源。页被封装为Page,Page具有一个十分重要的属性:pin_count_,表示正在使用该Page的线程数量。
pin_count_非0时,Buffer Pool无法驱逐该Page,也就是无法从磁盘加载数据到内存。显而易见的是:如果程序出现意外,某个Page的pin_count_永不为0,轻则降低DBMS的运行速度,重则使系统崩溃,无法加载数据。也可以说,这是一种资源泄漏。
C++如何解决资源泄漏?一个经典的例子:使用智能指针解决内存泄漏。智能指针依赖于RAII机制:利用对象的生命周期,在构造函数中获取资源,在析构函数中释放资源。而我们要实现的PageGuard只使用了RAII的一部分:在析构函数中释放资源。同时还提供了手动释放资源的接口,以提高DBMS在并发环境下的运行效率。
回到Task1中,对于每个类,我们需要实现以下接口:
- 移动构造函数
- 移动赋值函数
Drop():手动释放资源,并放弃对资源的管理权- 析构函数
而对于BasicPageGuard,我们还需要实现UpgradeRead()与UpgradeWrite(),分别用来将BasicPageGuard对象转换成ReadPageGuard与WritePageGuard对象。
PageGuard函数实现
移动构造函数
BasicPageGuard:将每个成员变量的值与被移动对象that交换(std::swap)即可。
ReadPageGuard/WritePageGuard:同上。将guard_成员的每个成员与被移动对象that的guard_成员的每个成员交换即可(不确定使用std::swap直接交换guard_成员是否会发生意外,懒得查文档就直接交换guard_的每个成员了)。
移动赋值函数
BasicPageGuard:与移动构造类似,需要注意的是:调用移动赋值时,当前对象可能已经守护(guard)了其他资源,所以需要先调用this->Drop(),放弃guard对象的所有权,再执行移动构造函数的逻辑。
ReadPageGuard/WritePageGuard:同上。
最后返回*this以支持连等,不过需要注意的是:只有在this != &that(不能自己等于自己)的情况下,才能执行移动赋值操作,否则this->Drop()将导致悬空指针以及pin_count_的提前释放。
UpgradeRead/UpgradeWrite
获取page_的read/write锁,再默认构造ReadPageGuard/WritePageGuard对象,用this->page, this->bpm_字段初始化ReadPageGuard/WritePageGuard对象的guard_成员,最后记得使this->page, this->bpm_无效。
需要注意的是:如果this->page_为nullptr,那么直接抛出异常。所有的操作都必须建立在this->page_不为nullptr的情况下。
Drop
BasicPageGuard:
- 调用bpm_->UnpinPage(page_id, is_dirty)——减少pin_count_以释放资源
- 将bpm_与page_指针置空——放弃对资源的管理权
ReadPageGuard/WritePageGuard:先释放read/write锁资源,再调用this->guard_.Drop()
需要注意的是:先检查this->page_/this->guard_.page_是否为nullptr,不为nullptr的情况下,再执行上面的操作。
同时,WritePageGuard的Drop()应该先设置脏位(this->is_dirty_ = true),再解写锁。因为这里默认获取了写锁就会修改Page的数据,所以需要设置脏位。
析构函数
直接复用Drop()即可。
BufferPoolManager函数实现
基于BasicPageGuard, ReadPageGuard, WritePageGuard,我们需要实现BufferPoolManager中的四个成员函数
- FetchPageBasic(page_id_t page_id)
- FetchPageRead(page_id_t page_id)
- FetchPageWrite(page_id_t page_id)
- NewPageGuarded(page_id_t *page_id)
FetchPageBasic
调用this->FetchPage(),从BufferPool中获取page资源。如果FetchPage成功,返回{this, page_ptr}即可。否则返回无效对象{nullptr, nullptr}.
FetchPageRead/FetchPageWrite
调用FetchPageBasic(),这里需要检查返回的BasicPageGuard对象是否有效,所以我实现了operator bool,根据guard的page_指针是否为空来判断对象是否有效。
这里涉及到一个编程规范:为operator bool添加explicit标记,防止无意的隐式转换。比如:
BasicPageGuard bpg;
/** 以下语句进行了无意的隐式转换 */
bool isValid = bag;
如果BasicPageGuard有效,返回其UpgradeRead()/UpgradeWrite()函数。如果BasicPageGuard无效,返回无效对象{nullptr, nullptr}即可。
NewPageGuarded
调用BufferPool的NewPage函数,根据其返回值page_ptr是否为空判断调用是否成功。若成功,返回{this, page_ptr}, 否则返回{this, this}.
BUG调试
调用GetData()后出现了空指针访问错误,说明获取了无效Page。但是上层函数都进行了指针合法性判断,GDB调试后发现:operator bool的实现逻辑存在问题,正确逻辑如下:

之前写成了this->bmp_ == nullptr,存在两个问题:
- 应该对page_进行判断,因为Guard对象是Page
- 需要判断指针不为空,不为空才是有效page
GradeScope测试时,出现死锁错误。我寻思着测试用例是单线程,哪来的死锁?最后在热心网友分享的测试用例帮助下找出了bug. 测试用例来自:CMU15-445 2023 Spring <Project 1 Task 3> “Read/WritePageGuards“ 死锁测试样例。
原因是:WritePageGuard/ReadPageGuard的移动构造函数中,需要先释放当前guard对象的资源,我是怎么释放的呢?this->guard_.Drop(),显然这样只会放弃成员guard_的所有权,并释放pin_count_资源。但是锁资源却没有释放,在已经持有锁资源的情况下,获取相同锁资源,将导致死锁错误。
正确做法应该是调用this->Drop(), 再调用this->guard_.Drop(),因为this->Drop()会先释放锁资源。
Task2 - Hash Table Page
在Task2中,我们需要实现Extendible Hash Table的三个基础组件,分别是:
- Header Page
- Directory Page
- Bucket Page
每个Extendible Hash Table有且仅有一张Header Page,根据hash值的高位,指向不同Directory Page。Directory Page将根据hash值的低位,指向不同的Bucket Page。Bucket Page则是实际存储数据的结构。
需要注意:
- 在Fall 2023中,我们实现的
Extendible Hash Table不允许插入相同key值的k-v - 为了解决hash冲突,Bucket Page存储k-v, 不只是存储value
关于成员函数:Task2需要实现的所有Hash Table Page结构,都禁止了构造,拷贝与移动相关成员函数。只暴露了Init接口用来对成员进行初始化,显然,我们无法正常地创建Hash Table Page的对象,所以在调用Init函数前,我们需要先获取一块大小足够的内存资源。
那么如何获取内存资源?在Project 1中,我们实现了BufferPool,用来管理数据在内存和磁盘之间的移动。在Task1中,我们实现了Page对象的Guard类,为Page添加了RAII机制。这些实现都将在Task2中使用。
在阅读Task2的测试用例后,你就能得到创建Hash Table Page的方法:
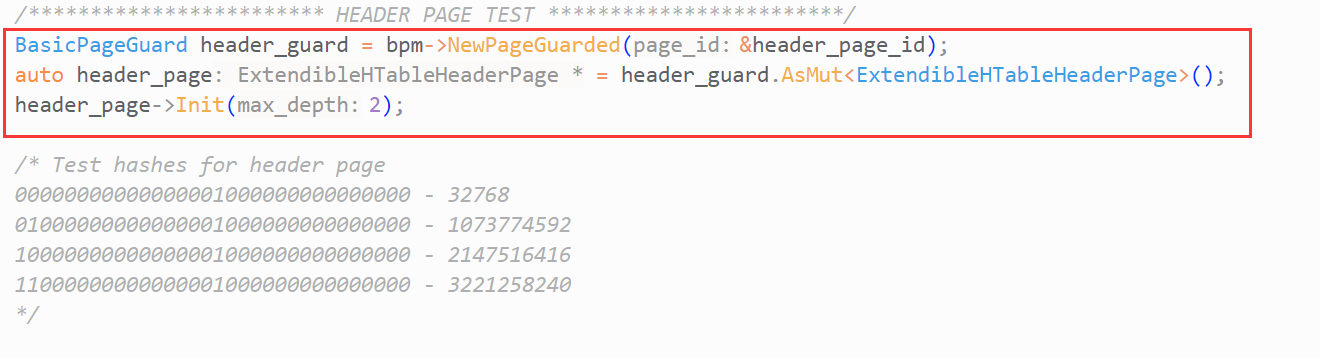
- 通过BufferPool的
NewPageGuarded获取Page的Guard对象 - 通过Guard对象的
As()/AsMut()方法获取Page对象的data_指针(data_指针指向存储数据的数组),并对其进行强转 - 调用Hash Table Page的
Init函数,对Page的成员变量进行初始化
以上,你可以看出:每个Hash Table Page都对应着一个Page. Hash Table Page实际使用的资源为Page.data_.
关于第2步中的As()/AsMut():以下其具体实现,你可以在BasicPageGuard的.h文件中找到:
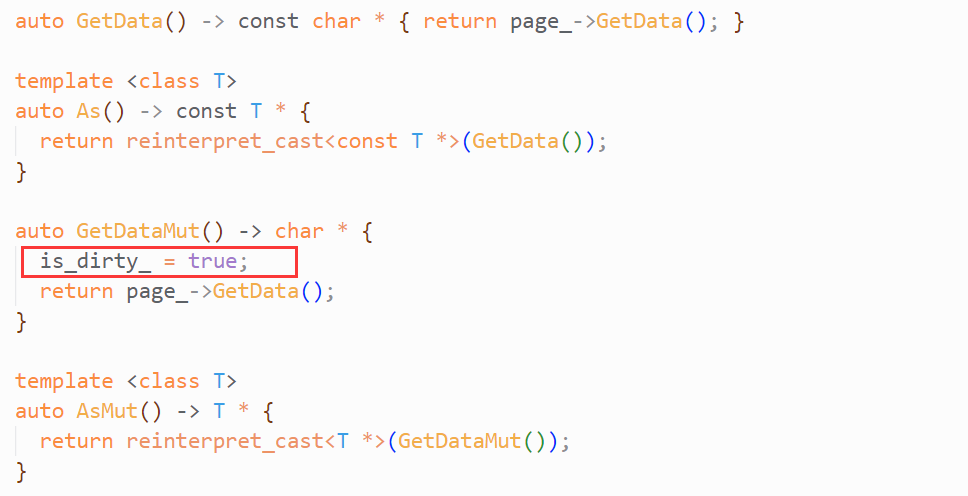
ReadPageGuard/WritePageGuard的As()/AsMut()都对其进行了复用(但ReadPageGuard只有As函数,你可以将Mut理解为可变的意思,显然ReadPage不可变,所以没有AsMut()方法)。
以及一个知识点:C++的四种强转之一——reinterpret_cast, 用于重新解释一个对象,相当于C语言的类型转换。转换将在编译时完成,这是一个危险的行为,极易引发内存的非法访问。
可以看到:As()/AsMut函数将获取Page的data_指针(page_->GetData()),并对其进行强转。调用As()/AsMut()函数时,在模板参数中填入类名,函数将返回该类型的指针。同时,AsMut()将设置this->is_dirty_ = true.
一般情况下,我们不会直接使用BasicPageGuard的As/AsMut,而是使用WritePageGuard/ReadPageGuard的As/AsMut.
而BufferPool提供的Page资源只能使用4096B的内存,所以Hash Table Page的大小也不会超过4096B, 否则将造成内存的非法访问。在相关头文件中,我们可以看到这样的断言:

这些断言都是为了确保Hash Table Page的大小不超过4096B.
Header Page
具体的类名是ExtendibleHTableHeaderPage,仅有两个成员:
directory_page_ids_数组:存储Directory Page的id值max_depth_:数组的最大深度,数组的实际长度为1 << max_depth_
也就是说Header Page的大小是固定的,它最多只能存储(1 << max_depth_)个Directory Page.
Init():对成员变量进行初始化。将directory_page_ids_的所有值初始化为INVALID_PAGE_ID,再将形参max_depth的值赋给this->max_depth_即可。
此外,你应该对max_depth进行合法性判断:max_depth <= HTABLE_HEADER_MAX_DEPTH,若不满足则抛出异常。
HashToDirectoryIndex():根据hash值的高位,获取hash值在directory_page_ids_中对应的下标。也可以将该函数理解为:应该在哪个Directory Page存储hash值?
关于“根据hash值的高位”:具体来说,是根据hash值的最高max_depth_位。假设hash值长度为8bit:0110 1011,max_depth_:4,那么HashToDirectoryIndex应该返回该hash值的最高4位:0110。
GetDirectoryPageId()/SetDirectoryPageId():根据传入的数组下标获取/设置相应元素,没啥好说的。但你应该对下标的合法性进行判断,这有助于后续的debug.
Directory Page
具体的类名是ExtendibleHTableDirectoryPage,有四个成员:
bucket_page_ids_数组:存储Bucket Page的id值local_depths_数组:存储以上Bucket的深度max_depth_:用1 << max_depth_表示以上两个数组的最大长度global_depth_:当前Directory的深度,用1 << global_depth_表示两个数组的长度
Init():初始化local_depths的所有元素为0,bucket_page_ids_的所有元素为INVALID_PAGE_ID. 根据形参max_depth赋值this->max_depth_. 设置global_depth_为0,表示两个成员数组的长度为1。
HashToBucketIndex():根据hash值的低位,获取hash值在两个数组中对应的下标,也可以将该函数理解为:应该在哪个Bucket Page中存储该hash值?
关于“根据hash值的低位”:具体来说,是根据hash值的最低global_depth_位。假设hash值长度为8bit:0110 1011,global_depth_:3,那么HashToDirectoryIndex应该返回hash值的最低3位:011。
GetGlobalDepthMask():返回global_depth_的掩码,用来计算下标值。假设当前global_depth_:3,那么GetGlobalDepthMask应该返回最低三位为1的掩码
即:0000 0111。
GetSplitImageIndex():该函数需要在分裂Bucket(Task3中实现)时调用。
- 假设Bucket的local_depth:2,bucket_idx:01
- 分裂成两个Bucket后:old_bucket_idx:001 new_bucket_idx:101
所以这个函数需要先根据local_depths_[bucket_idx]获取Bucket的local_depth,再根据local_depth对bucket_idx用1做异或^运算。
你可能会感到疑惑:为什么不是或|运算,new_bucket_idx的最高位一定为1啊?在我的实现中,这个函数的功能不止是获取new_bucket_idx,也可以通过new_bucket_idx获取old_bucket_idx,所以我这里实现的是异或^运算。
需要注意的是:用来运算的local_depth是自增前的还是自增后的?应该是自增前的。如果不想清楚这一点,将导致Task3的bug.
CanShrink():遍历local_depths_数组,判断是否所有local_depth都小于global_depth_, 如果是则返回true,说明Directory可以缩容,即global_depth可以自减。
IncrGlobalDepth():该函数需要在分裂Bucket(Task3中实现)时调用。global_depth_的增加将导致数组增大到原来的两倍,而新空间存储着无效数据。我们需要遍历两个数组的旧空间,使新旧空间存储的数据相同。
IncrLocalDepth():这里不需要判断local_depth与global_depth的大小关系,应该由上层确保LD <= GD。所以你不应该在LD == GD时抛出异常,这将导致你无法通过本地测试。
剩下的其他函数没有什么需要注意的地方,根据函数名实现功能即可,都是一些简单的操作。
这里解释下用来测试的VerifyIntergrity():

根据local_depth和global_depth的概念,我们可以得到两个限制条件:
- LD <= GD
- 每个Bucket有 2 G D − L D 2^{GD-LD} 2GD−LD个指针指向
根据我们对Directory的实现:
- 对于
条件1,我们需要遍历local_depths_数组,检查每个元素小于GD - 对于
条件2,我们需要遍历bucket_ids_数组,统计每个元素(bucket_page_id)的出现次数,也就是每个bucket被几个指针指向。同时也遍历local_depths_数组,记录该bucket的local_depth
最后遍历统计表,检查是否每个Bucket都满足条件2,如下:
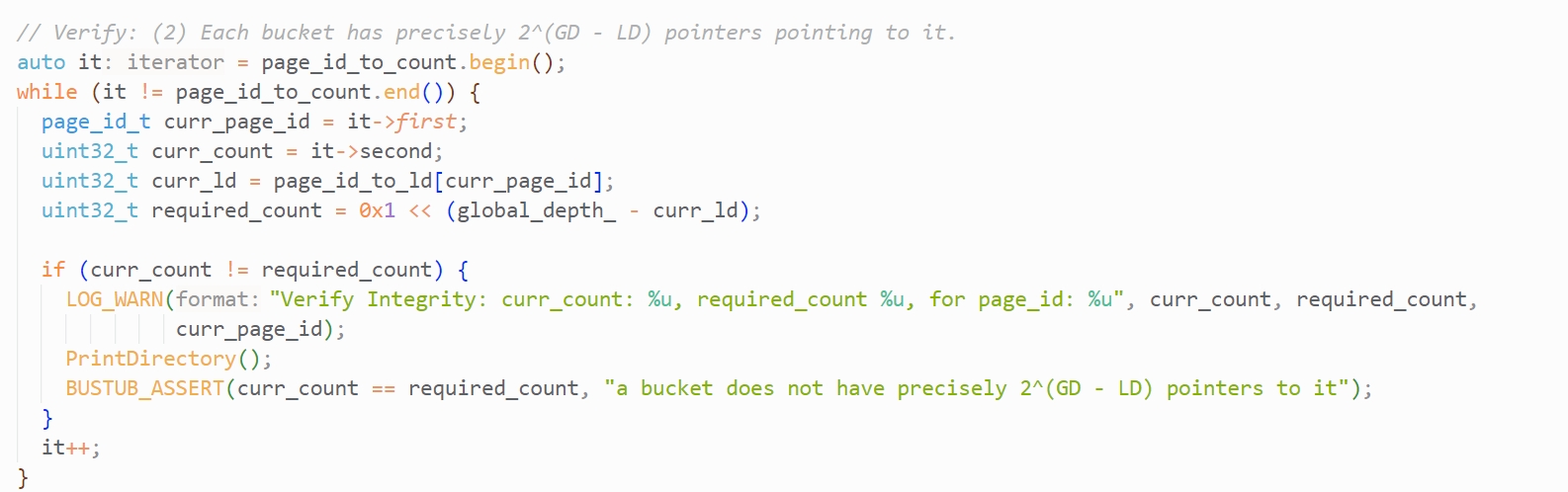
根据我们对Directory的实现:如果在bucket_page_ids_数组中,有多个指针指向了同一bucket,那么在local_depths_数组中,相应位置的元素应该是相同的。即,不同位置保存了相同bucket的LD, 这些LD需要相同。
这是条件3,与我们的代码实现强相关,相关测试代码如下:
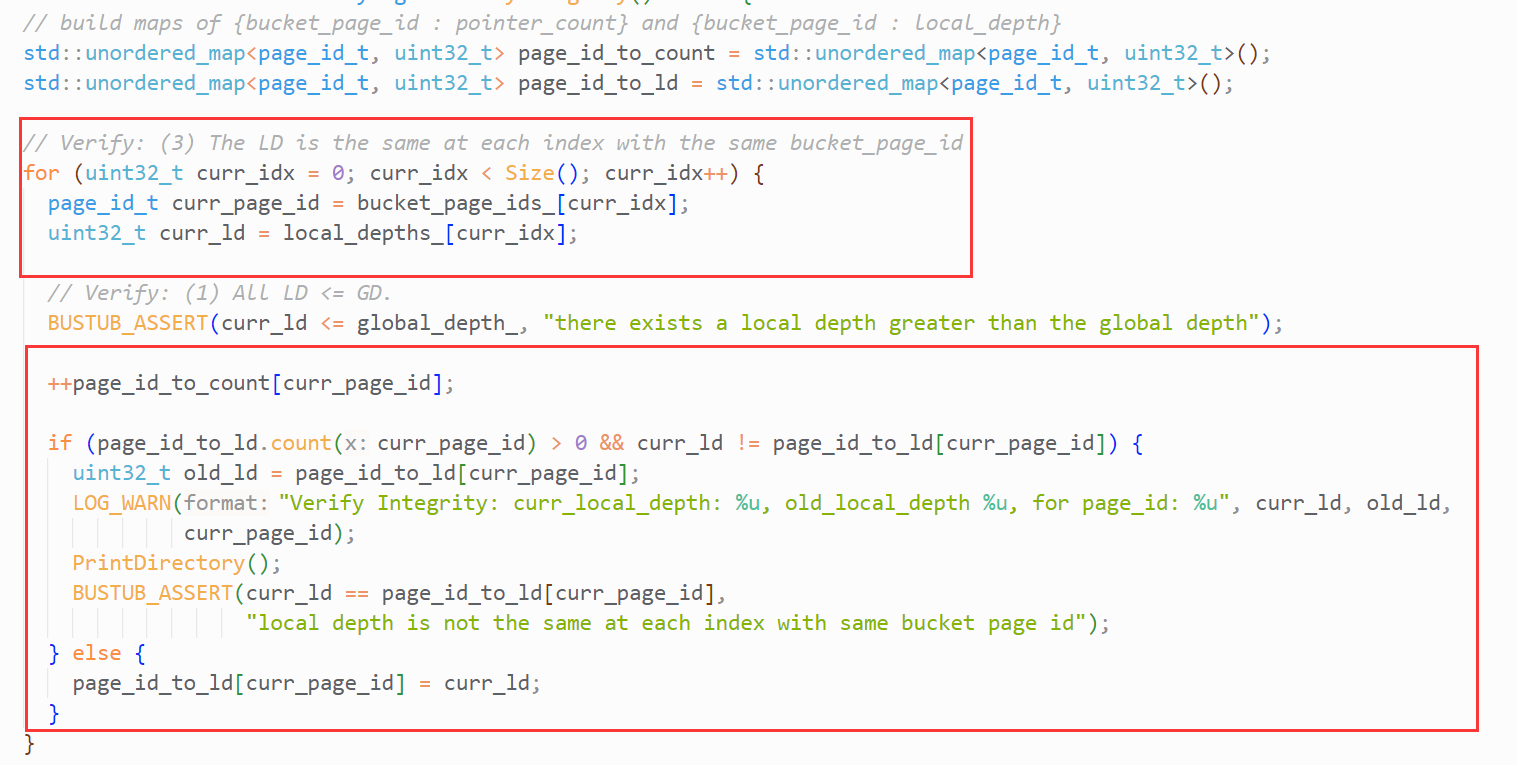
只需要判断当前bucket_page_id的LD是否已经被记录。如果是,则比较记录中的LD和当前LD是否相等。如果不是,则记录当前ID.
Bucket Page
具体的类名是ExtendibleHTableBucketPage,有三个成员:
size_:用来表示array_数组的大小max_size_:用来表示array_数组的最大大小,即容量array_数组:实际存储数据的地方,元素的类型为pair<KeyType, ValueType>
需要注意:ExtendibleHTableBucketPage是一个类模板:

其中,第三个模板参数为比较器,即重载了operator()的类,比如:

你需要注意比较器的规则:返回值类型不是bool,而是int
- -1:小于
- 0:等于
- 1:大于
(一开始我认为比较器返回bool值,相等为true,不等为false,最后自然地产生了bug)
LookUp():遍历array_数组,使用比较器挨个比较每个k-v的key。将对应value通过输出型参数返回即可。
Insert():由于key值唯一这个约束条件,所以先调用LookUp判断是否存在相同key。因为size_表示数组的大小,同时也指向了下一个可用位置,所以将k-v存到array_[size_]这个位置上即可,最后别忘了size_++.
需要注意的是,需要检查Bucket是否为满,满了则不允许插入(分裂桶是上层需要做的逻辑)。
Remove():和LookUp逻辑相同,找到相同key后,将其与最后一个元素交换,size_--即可。这里有点像堆的删除。
RemoveAt():直接将bucket_idx上的元素与最后一个元素交换,size_--.
剩下的其他函数没有什么需要注意的地方,根据函数名实现功能即可,都是一些简单的操作。
Task3 - Extendible Hashing Implementation
这个Task将实现完整的Hash Table,以下的讲解也包括了Task4的并发控制。
Init():每个Hash Table有且仅有一张Header Page,所以在初始化所有成员变量后,还应该获取一张Page(bpm_->NewPageGuard()),用来存储Header Page,同时保存将page_id保存到this->header_page_id_中。
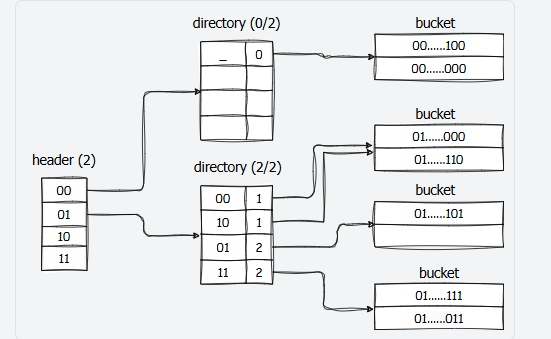
Hash Table的全名是:DiskExtendibleHashTable,同样是一个类模板,模板参数和Bucket Page相同。下面这张图是Hash Table的大致结构,分别使用了Task2中实现的三种Page,Page之间通过指针(也就是page_id)连接。实际的数据存储在Bucket Page中,所以不论是访问还是修改,想要获取数据就必须先获取到Bucket Page, 因此访问路径为:Header Page->Directory Page->Bucket Page.
我们需要根据不同函数,决定访问Page前要加的锁。
Hash(K key):这是一个已经实现好的函数,内置Murmur3 Hash算法。由于key的类型不一定是整数,所以需要先调用Hash函数,获取一个32位整数,作为key的hash值。
GetValue
因为是读取,所以只用加读锁,逻辑如下:
- 给Header Page加读锁,以获取directory_page_id
- 若id无效,返回false
- 给Header Page解锁,fetch Directory Page并加读锁,以获取bucket_page_id
- 若id无效,返回false
- 给Directory Page解锁,fetch bucket page并加读锁,调用Lookup()遍历page
- 若key存在,返回true,否则返回false
Insert
无论是Header Page,还是Directory Page,都有可能被修改,所以获取Page时要加写锁。
你可能会感到疑惑:为什么我不能先加读锁,真的需要修改时再加写锁?Header Page和Directory Page的修改频率比Bucket Page低很多,加写锁岂不是加剧线程竞争?我是这么理解的,假设线程T1加了Header Page的读锁,然后发现要修改Header Page,就去获取其写锁。拿到写锁后再进行修改,但是T1的修改逻辑是基于之前读取的情况进行的。有没有可能之前读取的情况是错误的?比如释放了读锁后,无法立即获取写锁,T2获取写锁修改了Header Page。那么T1的修改可能会覆盖T2的修改,产生数据不一致。
为了防止上面复杂情况的发生,干脆直接上写锁(其实我是懒得继续想了)。
Insert()的逻辑如下:
- GetValue()判断是否Insert重复值,如果重复,直接返回false
- fetch Header Page并加写锁,以获取directory_page_id
- 若id无效,调用InsertToNewDirectory()
- 给Header Page解写锁,fetch Directory Page并加写锁,以获取bucket_page_id
- 若id无效,调用InsertToNewBucket()
- 给Directory Page解写锁,fetch bucket page并加写锁
- IsFull()判断bucket page是否为满
- 如果满了,则分裂(这个后面细说)
- 如果不满,则直接插入,并返回true
其中涉及到了InsertToNewDirectory()与InsertToNewBucket():
InsertToNewDirectory():
- 获取新的Page,作为Directory Page,记得调用
Init() - 调用SetDirectoryPageId(), 修改Header Page的directory_ids_数组,存入新页id
- 给Directory Page加写锁,调用
HashToBucketIndex函数,获取当前k-v在Directory Page中bucket_ids_数组的下标,作为接下来要使用的参数 - 由于Directory Page是新的,所以一定没有Bucket Page,调用
InsertToNewBucket即可
InsertToNewBucket():
- 获取新的Page,作为Bucket Page,记得调用
Init() - 调用SetBucketPageId()修改Directory Page的bucket_ids_数组,存入新页id
- 给Bucket Page上写锁,调用Insert()函数即可
分裂过程
如果Bucket Page满了(IsFull()),我们就要进行分裂,将Bucket Page中的数据挪走一部分到新的Bucket Page中。如何分裂?
- 增加local_depth
- 调用SetBucketPageId()更新Directory Page的数组
- 迁移原桶数据到新桶
- 递归调用自己
详细过程如下:
首先增加桶的local_depth,如果增加前的local_depth == global_depth,那么global_depth也需要增加。如果无法增加GD,说明Directory Page已满,无法存储更多的Bucket Page. 此时直接返回false即可。
接着调用GetSplitImageIndex(),获取当前桶对应的分裂桶idx。NewPageGuarded()获取新的Page,以存储Bucket Page,记得调用Init()。然后调用UpdateDirectoryMapping(),对Directory Page的bucket_ids_与local_depths_进行更新。
UpdateDirectoryMapping:Directory Page的数组可能有多个位置指向原桶,这些位置的local_depth需要更新。也有多个位置指向了新桶,这些位置保存的local_depth与page_id都需要更新。说的很难懂,看实例:
假设原桶的idx:101,分裂后其idx:0101,新桶idx:1101。那么Directory Page有哪些idx指向了原桶?5位bit:00101,10101。6位bit:000101(与00101相同),100101,110101。7为bit: …
可以发现,这些idx的后local_depth位都等于0101,也就是原桶的idx。我们从0101开始,不断累加1 << local_depth,直到idx超过数组范围,就能得到所有指向原桶的idx. 同理,我们也能得到指向新桶的所有idx. 我们分别需要在local_depths_与bucket_page_ids_对这些idx进行更新。
回到分裂,调用完UpdateDirectoryMapping()后,我们需要将原桶的数据挪到新桶,此时先对新桶上写锁。我实现的是空间复杂度 O ( 1 ) O(1) O(1)的算法:遍历原桶的array_数组,获取k-v,调用Directory Page的HashToBucketIndex()。如果得到的idx为新桶idx,调用RemoveAt,删除该数据。再调用新桶的Insert(),将之前保存的k-v插入到新桶。
需要注意的是:RemoveAt后,末尾数据被移动到当前位置,如果继续往后遍历,将漏掉这个曾经是末尾的数据。以及,Directory Page的HashToBucketIndex()要么返回原桶idx,要么返回新桶idx,如果返回了其他idx,说明出现了意外k-v。你需要特判这种情况,防止程序出现了逻辑错误。
那么有没有一种可能:分裂后的重新hash没有迁移一个数据,导致数据依然无法插入。所以我们应该递归调用Insert,直到能够插入,或者Directory Page无法存储更多的Bucket Page。
需要注意的是:递归调用并不会触发Guard的析构函数,我们需要先将锁资源释放,否则你会触发死锁。
Remove
与Insert相同,我们需要获取Page的写锁,逻辑如下:
- fetch Header Page并加写锁,以获取directory_page_id
- 若page id无效,直接返回false
- 给Header Page解锁,fetch Directory Page并加写锁,以获取bucket_page_id
- 若page id无效,直接返回false
- 给Directory Page解锁,fetch Buckete Page并加写锁
- 遍历Bucket Page, 若key存在,删除。否则返回false
- 删除后,若Bucket Page为空,需要合并
合并过程
关于合并:文档说,如果删除后当前桶为空,且local_depth与split_bucket_depth相同,则进行合并。但是实际测试发现,存在当前桶非空,而split_bucket为空的情况,此时也要进行合并。聪明的你可以先想想这种情况是怎么发生的: )
因为(1)存在当前桶为空,但local_depth与split_bucket_depth不同的情况。虽然出现了空桶,但无法被合并。直到当前桶成为其他桶的split_bucket时,它才有可能被合并。
(2)分裂时,没有数据被挪到split_bucket,此时产生了一个空桶。二次分裂时,若还是没有数据被挪到split_bucket,又产生一个空桶… 直到有数据被移动到split_bucket, 分裂结束。此时有可能发生上述情况。
(如果你还是无法理解,可以将合并条件写为:当前桶为空,且与split_bucket的local_depth相同。然后跑下测试用例)
关于split_bucket:可以理解为上一次Insert时的新桶,调用GetSplitImageIndex()即可获取其idx(如果你的GetSplitImageIndex()实现的是异或^运算)。
所以合并的条件应该是:当前桶或split_bucket为空,且两者的local_depth相同。
如何合并?
- 释放空桶资源:先guard.Drop()再DeletePage()
- 维护Directory Page的local_depths_与bucket_ids_数组,修改保存空桶数据的idx,使其保存非空桶数据
- 只要CanShrink()为true(能减小global_depth),就DecrGlobalDepth()
不断执行以上过程,直到无法合并。
需要注意的是:我们因为bucket_idx触发合并操作,在不断合并的过程中,bucket_idx不变, 而bucket_idx对应的page_id可能发生变化。因此,我们需要根据bucket_idx获取page_id,再通过page_id获取实际的Bucket Page。
写在最后
如果你对文章的某些描述感到疑惑,或是发现了文章的错误,欢迎在评论区提出: )
这篇关于CMU15445 (Fall 2023) Project2 - EXTENDIBLE HASH INDEX 思路分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





