本文主要是介绍CDH安装配置zeppelin-0.7.3以及配置spark查询hive表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.下载zeppelin
http://zeppelin.apache.org/download.html
我下载的是796MB的那个已经编译好的,如果需要自己按照环境编译也可以,但是要很长时间编译,这个版本包含了很多插件,我虽然是CDH环境但是这个也可以使用。
2.修改配置文件
cd /zeppelin-0.7.3-bin-all/conf
cp zeppelin-env.sh.template zeppelin-env.sh
cp zeppelin-site.xml.template zeppelin-site.xml
vim zeppelin-env.sh
添加配置如下:我的是spark2用不了spark1.6版本这个版本的zeppelin
export HIVE_HOME=/opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/hive
export JAVA_HOME=/usr/java/jdk1.8.0_121
export MASTER=yarn-client
export ZEPPELIN_JAVA_OPTS="-Dmaster=yarn-client -Dspark.yarn.jar=/home/zeppelin-0.7.3-bin-all/interpreter/spark/zeppelin-spark_2.11-0.7.3.jar"
export DEFAULT_HADOOP_HOME=/opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/hadoop
export SPARK_HOME=/data/parcels/cloudera/parcels/SPARK2/lib/spark2
#export SPARK_HOME=/opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/spark
export HADOOP_HOME=${HADOOP_HOME:-$DEFAULT_HADOOP_HOME}
if [ -n "$HADOOP_HOME" ]; then
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/hadoop/conf}
export ZEPPELIN_LOG_DIR=/var/log/zeppelin
export ZEPPELIN_PID_DIR=/var/run/zeppelin
export ZEPPELIN_WAR_TEMPDIR=/var/tmp/zeppelin
3.配置这些其实已经足够了。
在启动
./zeppelin-daemon.sh start
4.在界面上配置就可以使用了hive的配置这个
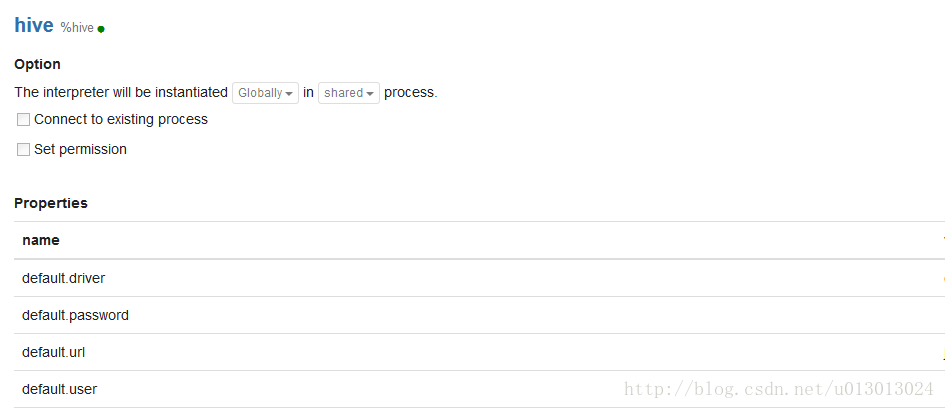
添加依赖:
这些就可以查询hive了
5.用spark读取hive表这个比直接查询hive表快十倍
我把hive的配置文件hive-site.xml拷贝到hadoop_home/conf
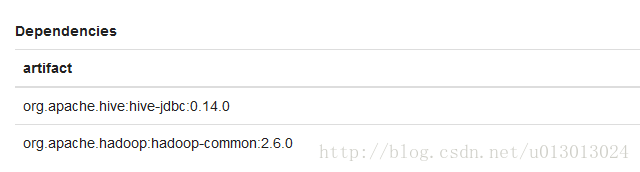
添加需要的依赖
%dep
z.load("org.apache.hive:hive-jdbc:0.14.0")
z.load("org.apache.hadoop:hadoop-common:2.6.0")
z.load("/home/gl/hive-hcatalog-core-1.1.0-cdh5.9.0.jar")
%spark
import java.util.Properties
import org.apache.spark.sql.SparkSession
import org.apache.spark.SparkConf
val sparkConf = new SparkConf().setAppName("hive")
val spark = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val connectionProperties = new Properties()
connectionProperties.put("user", "")
connectionProperties.put("password", "")
connectionProperties.put("driver", "org.apache.hive.jdbc.HiveDriver")
val jdbcDF2 = spark.read
.jdbc("jdbc:hive2://*******:****/test", "bbb", connectionProperties)//.createTempView("bbb")
spark.sql("select count(*) from pc_db.pc_txt group by responseset").show()

6.
.修改登陆zeeplin验证方式
禁止匿名访问
Zeppelin启动默认是匿名(anonymous)模式登录的.如果设置访问登录权限,需要设置conf/zeppelin-site.xml文件下的zeppelin.anonymous.allowed选项为false(默认为true).如果你还没有这个文件,只需将conf/zeppelin-site.xml.template复制为conf/zeppelin-site.xml
<property>
<name>zeppelin.anonymous.allowed</name>
<value>false</value>
<description>Anonymous user allowed by default</description>
</property>
a)开启Shiro
在刚安装完毕之后,默认情况下,在conf中,将找到shiro.ini.template,该文件是一个配置示例,建议你通过执行如下命令行创建shiro.ini文件:
cp conf/shiro.ini.template conf/shiro.ini
[users] #admin = password1, admin #user1 = password2, role1, role2 #user2 = password3, role3 #user3 = password4, role2hadoop = hadoop, admin # 用户名、密码都是hadoop,角色为admin
bin/zeppelin-daemon.sh restart
这篇关于CDH安装配置zeppelin-0.7.3以及配置spark查询hive表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







