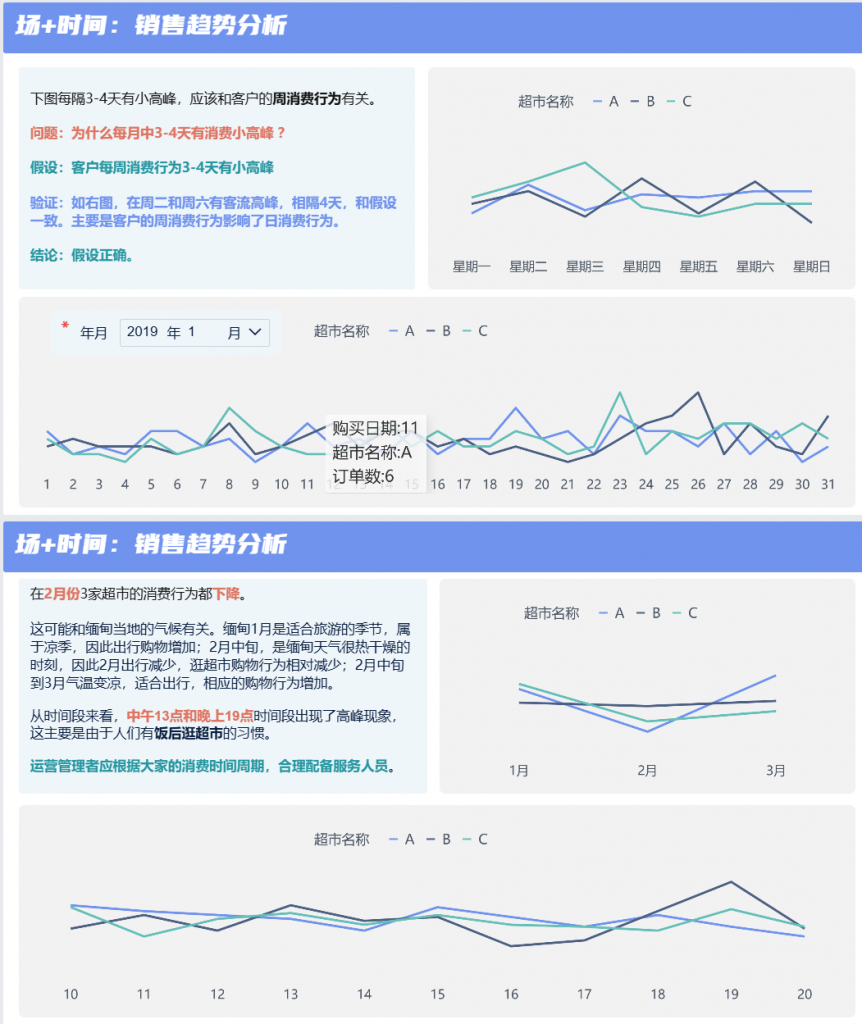
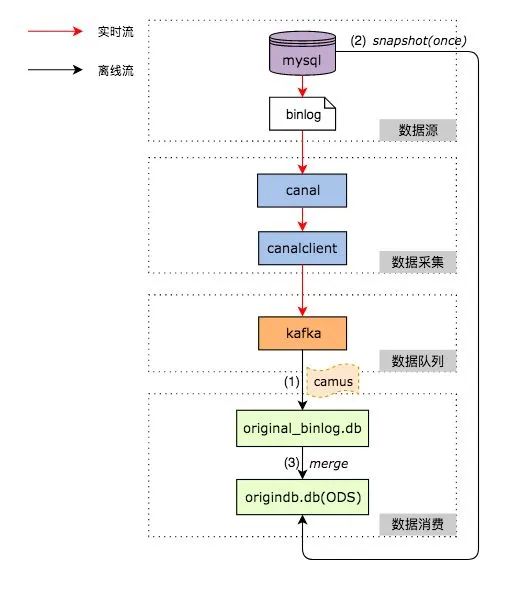
本文主要是介绍mq_消费者,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
添加依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-activemq</artifactId></dependency>json包:
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.38</version>
</dependency>application.properties:
spring.activemq.broker-url=tcp://127.0.0.1:61616
spring.activemq.user=admin
spring.activemq.password=admin
queue=mytest
server.port=8081调用如下:
import org.springframework.jms.annotation.JmsListener;
import org.springframework.stereotype.Component;import com.alibaba.fastjson.JSONObject;
import com.itmayiedu.entity.UserEntity;@Component
public class Consumer {@JmsListener(destination = "${queue}")public void receive(String msg) {System.out.println(msg);JSONObject jsonObject = new JSONObject();UserEntity userEntity = jsonObject.parseObject(msg, UserEntity.class);System.out.println(userEntity.getName() + "---" + userEntity.getId());}}
这篇关于mq_消费者的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!