本文主要是介绍一文读懂高通GPU驱动渲染流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. gpu command分析
1.1 gpu command概述
SM8650平台上,GLES发送给KMD(GPU驱动)的GPU命令有两种类型:同步命令和绘制命令。
绘制命令,一般都是一个个的drawcall组成的,是真正GPU程序指令,KMD会给GPU硬件进行处理。
同步命令,在KMD就能处理,无需GPU硬件参与。该指令主要是往KMD的任务队列塞同步点,用来阻塞绘制指令的处理。比如dequeueBuffer带的release fence,会被打包成一个同步命令,发送到KMD,KMD将其放到任务队列,UMD后续提给KMD的命令,就会排在该同步命令后面,就会被阻塞无法被处理,直到该同步命令的同步点被signal,同步命令从任务队列清除,排在该同步命令后面的命令才能继续被处理。
GLES给KMD发送命令时,会创建一个struct kgsl_gpu_command实例,然后把命令打包好,保存到该实例里,然后通过IOCTL_KGSL_GPU_COMMAND发送给KMD处理。
KMD把GPU命令抽象成struct kgsl_drawobj数据结构的子类。比如绘制命令抽象成struct kgsl_drawobj_cmd,同步命令抽象成struct kgsl_drawobj_sync,它们都继承于struct kgsl_drawobj。
故IOCTL_KGSL_GPU_COMMAND的实现函数kgsl_ioctl_gpu_command函数接收GLES发送的消息后,会把struct kgsl_gpu_command实例内保存的GPU命令转成struct kgsl_drawobj实例(这里的转成是指创建struct kgsl_drawobj实例,解析把struct kgsl_gpu_command内容并填充到struct kgsl_drawobj实例,而不是简单的类型强转)。绘制命令转成struct kgsl_drawobj_cmd实例, 同步命令转成struct kgsl_drawobj_sync类型的实例,然后再把这些drawobj实例,保存到context的drawqueue里面。如图:
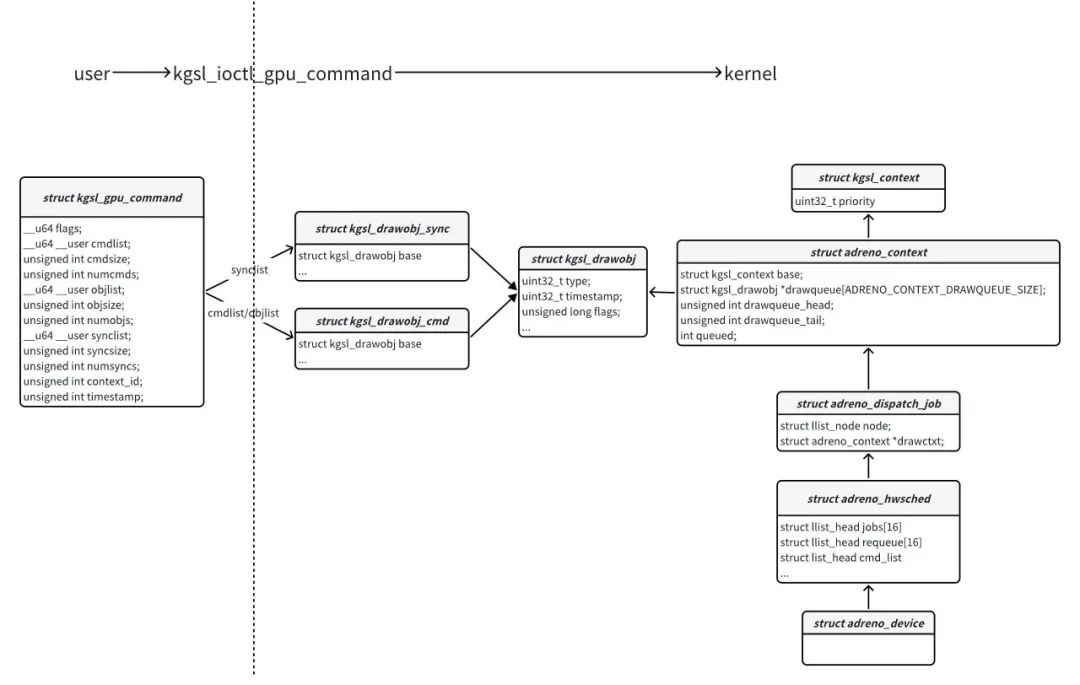
KMD初始化时,会为每个GPU设备创建一个struct adreno_device实例,每个struct adreno_device实例会有一个struct adreno_hwsched实例,每个struct adreno_hwsched实例会有16条struct adreno_dispatch_job类型的链表,每个struct adreno_dispatch_job会关联一个context,如图:
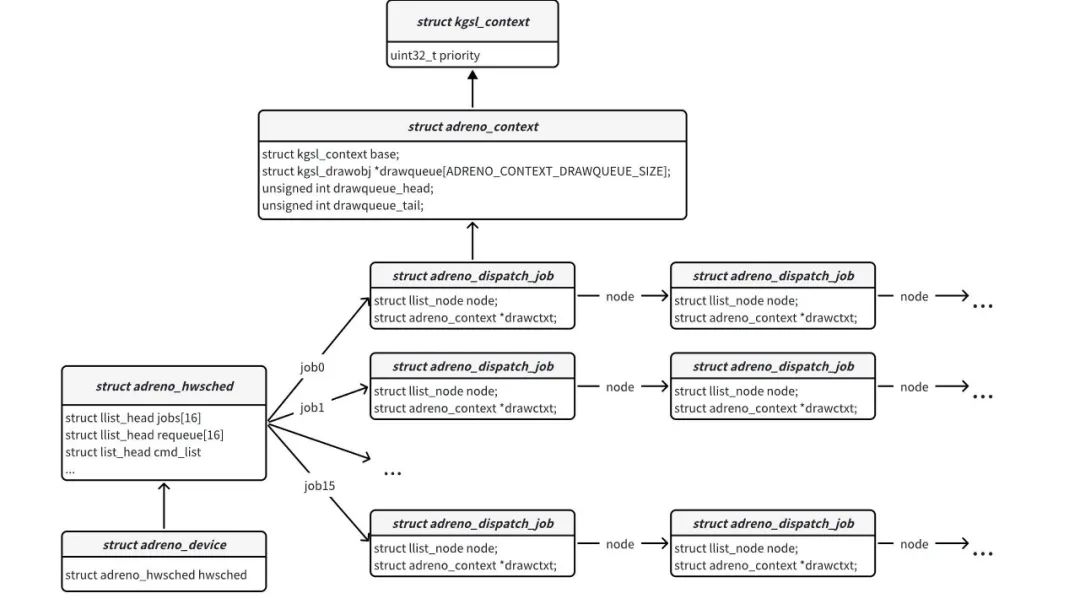
kgsl_ioctl_gpu_command函数将struct kgsl_gpu_command实例保存的GPU命令转成struct kgsl_drawobj实例,并保存到context的drawqueue里面;同时还会创建一个struct adreno_dispatch_job实例,然后根据context的priority,将创建的struct adreno_dispatch_job实例加入到struct adreno_hwsched实例对应链表的尾部(如priority为0,则加入第0条链表尾部)。
KMD初始化时,会创建一个名为kgsl_hwsched内核线程。该线程专门负责处理struct adreno_dispatch_job实例关联的context的drawqueue里面的drawobj。
kgsl_ioctl_gpu_command函数末尾,或者GPU HW处理完任务后,或者同步命令的同步点signal后,都会唤醒kgsl_hwsched线程,kgsl_hwsched线程依次遍历struct adreno_hwsched实例的16条链接,取出struct adreno_dispatch_job实例关联的context的drawqueue里面的drawobj进行处理。如果是同步命令drawobj,就直接从drawqueue里面移除。如果是绘制命令drawobj就发送GPU HW处理。
KMD初始化时,还会创建一个名为kgsl-events的内核线程。该线程专门负责GPU同步点signal,如acquire fence signal,EGLSync/GLSync的signal。
每个context都间接拥有一个struct kgsl_event类型的链表。该链表是用来保存GPU同步点的,如acquire fence,EGLSync/GLSync等。struct kgsl_event实例有两个很关键成员变量:timestamp和func。timestamp用来判断一个该event是否signal,func是事件处理函数。
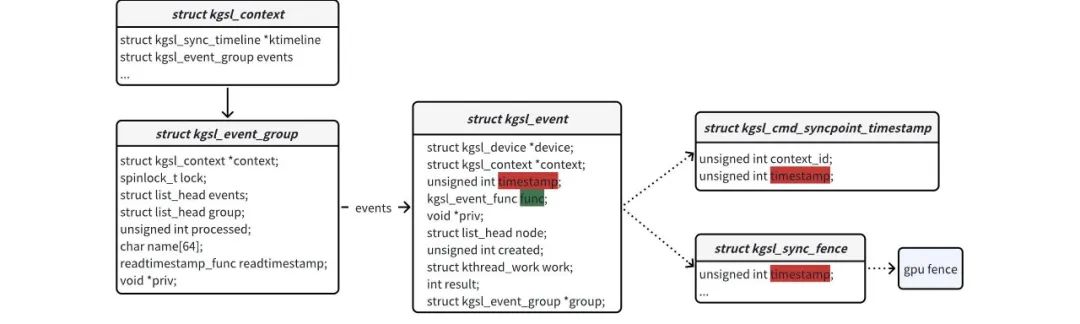
GPU HW硬件有个retire timestamp寄存器,专门用来记录GPU HW完成任务时的时间,GPU HW每完成一次计算任务就会更新这个retire timestamp寄存器。
每次GPU HW处理完任务后,KMD就会遍历比较context的events链表的event的timestamp和retire timestamp寄存器的时间戳,如果timestamp小于hw的retire timestamp时,KMD就会在kgsl_events线程执行event的func函数,func函数就会signal同步点。
1.2 同步命令处理分析
1.2.1 同步命令类型
KMD根据同步点的实现差异,将同步命令分为三种类型:
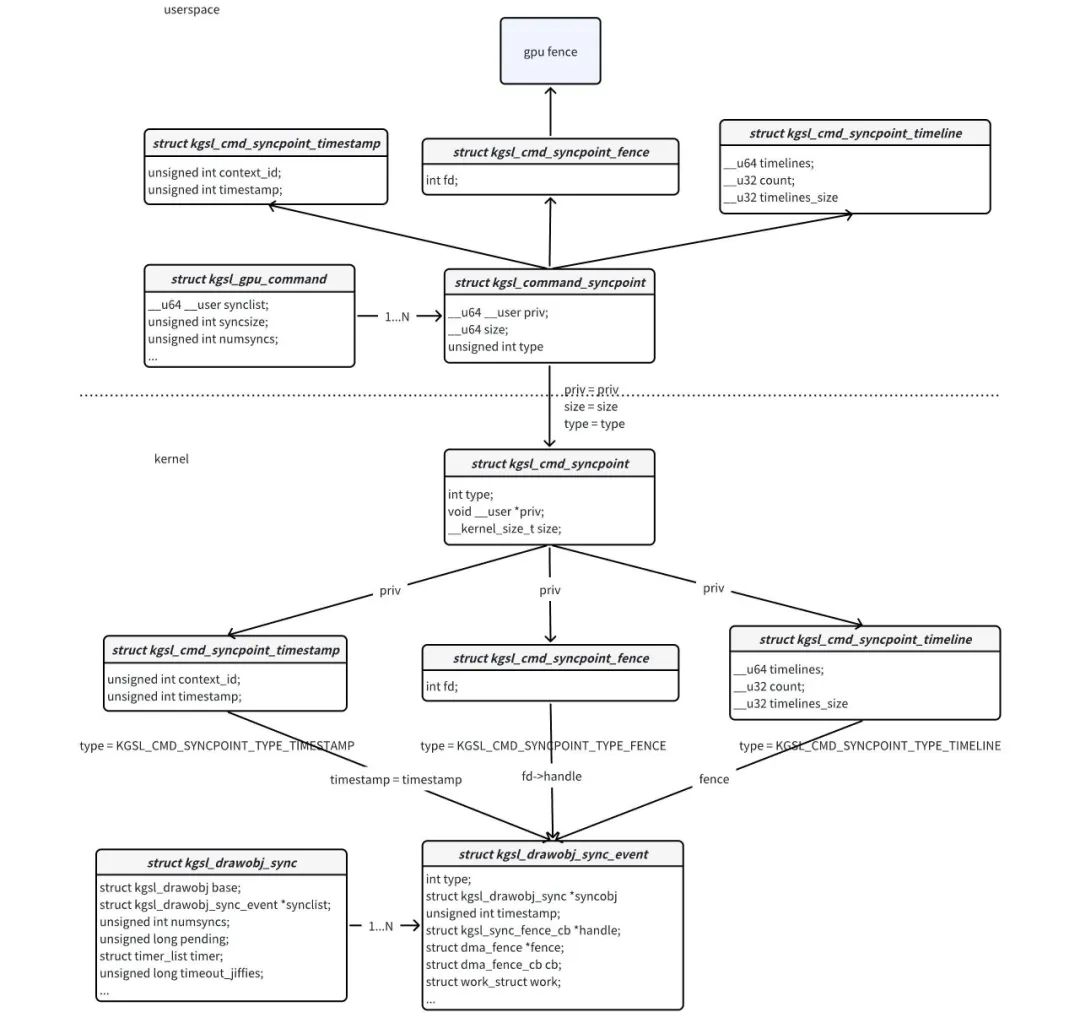
(1)fence syncpoint command:主要是fence类型的同步点,如release fence。对应的数据结构struct kgsl_cmd_syncpoint_fence
(2)timestamp syncpoint command:未知(没能通过gles api分析出什么情况下会下发该种同步点命令,应该是在不支持android fence机制的系统使用的)。对应的数据结构struct kgsl_cmd_syncpoint_timestamp
(3)timeline syncpoint command:未知(没能通过gles api分析出什么情况下会下发该种同步点命令)。对应的数据结构struct kgsl_cmd_syncpoint_timeline
但是这三种同步点最终都会换转成struct kgls_drawobj_sync_event实例,然后保存到struc kgsl_drawobj_sync实例的synclist变量内。看下图:
1.2.2 fence syncpoint command处理分析
根据第一章节的概述,我们可以把GPU命令处理一般分为二个步骤:
(1)预处理,该步骤主要解析用户空间传进来的GPU命令,然后转化成对应的drawobj实例并保存到context的drawqueque里面,同时创建一个struct adreno_dispatch_job实例加入到struct adreno_hwsched实例的链表内。
(2)ready后,kgsl_hwsched内核线程取出drawobj处理。
故对于fence syncpoint command处理分析。我们也分成这两个步骤:
(1)首先分析同步命令如何转成struc kgsl_drawobj_sync实例。上面小节的UML图已经很直观的展示这一个转化过程。这里我们再补一张这一流程的时序图:
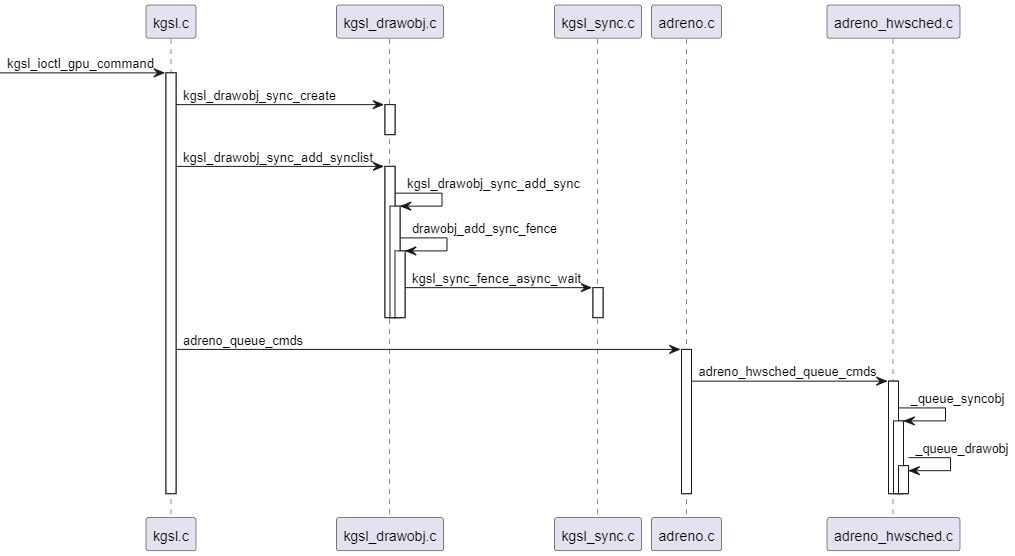
(2)当fence signal后,触发drawobj_sync_expire执行,drawobj_sync_expire函数会再次创建一个struct adreno_dispatch_job实例,并根据context的priority,将创建的struct adreno_dispatch_job实例加入到struct adreno_hwsched实例对应链表的尾部(个人认为这个步骤是多余的,因为上面已经做了这个动作),然后唤醒kgsl_hwsched线程进行处理。时序如下:
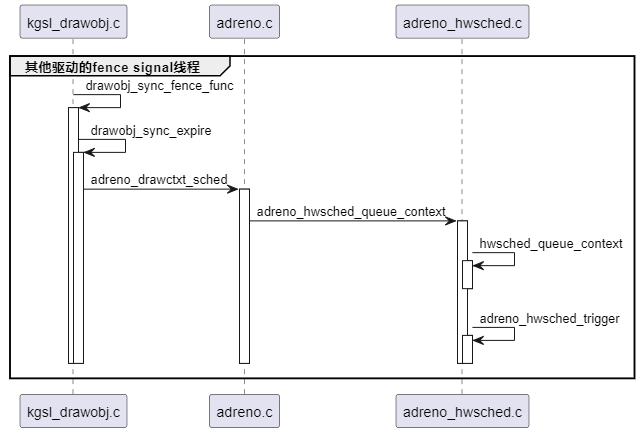
kgsl_hwsched线程取出drawobj处理,对于fence sync drawobj而言,kgsl_hwsched线程不做任何特殊处理,仅仅移出drawqueue,避免阻塞后面的drawobj:

下图是一次处理过程中的ftrace打印:
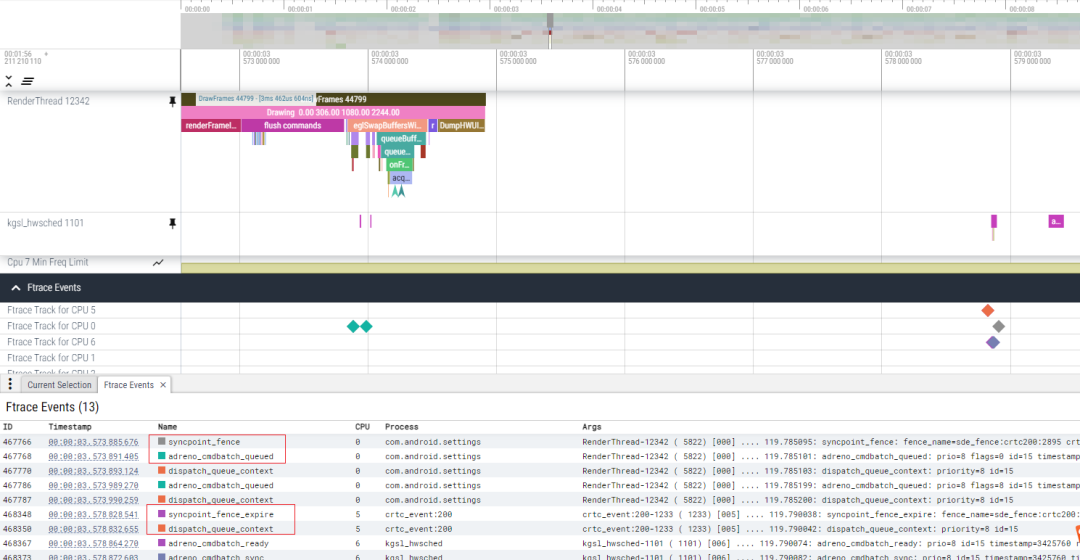
1.2.3 timestamp syncpoint command处理分析
timestamp syncpoint的处理流程和fence syncpoint处理流程类似,同样分为两个步骤。区别一个使用的是kgsl events框架,一个使用的dma fence框架。
(1)首先解析用户空间传进来的同步命令,转成struct kgsl_drawobj_sync实例,然后把实例保存到context的drawqueque里面,同时也会创建一个struc kgsl_event实例,并保存到context的events链表里。时序图如下:
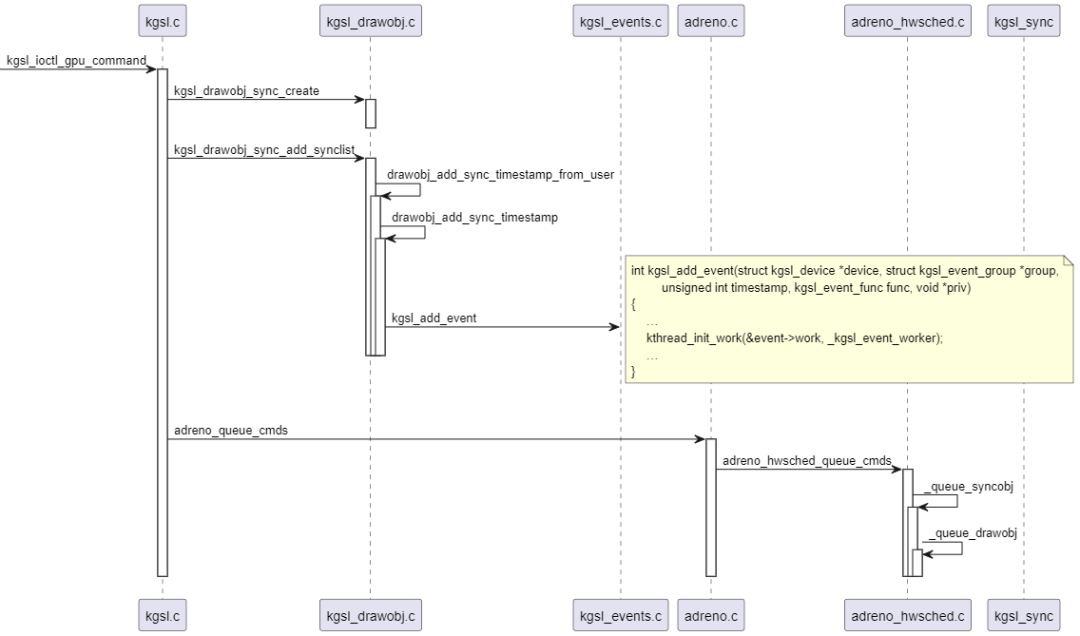
(2)当event的timestamp小于hw的retire timestamp时,唤醒ksgl_events线程执行event的事件处理函数
_kgsl_event_worker。_kgsl_event_worker执行drawobj_sync_func,drawobj_sync_func执行drawobj_sync_expire:

drawobj_sync_expire函数唤醒kgsl_hwsched线程进行处理。流程和fence syncpoint command处理流程一样,这里就不赘述了。
1.3 绘制命令处理分析
和上面一样,绘制命令处理,我们同样分为两个步骤进行分析。
(1)解析用户空间传进来的绘制命令,然后转化成struct kgsl_drawobj_cmd实例并保存到context的drawqueque里面,同时创建一个struct adreno_dispatch_job实例加入到struct adreno_hwsched实例的链表内。
同样,在讲解struct kgsl_drawobj_cmd生成过程前,先梳理出其相关的数据结构关系:
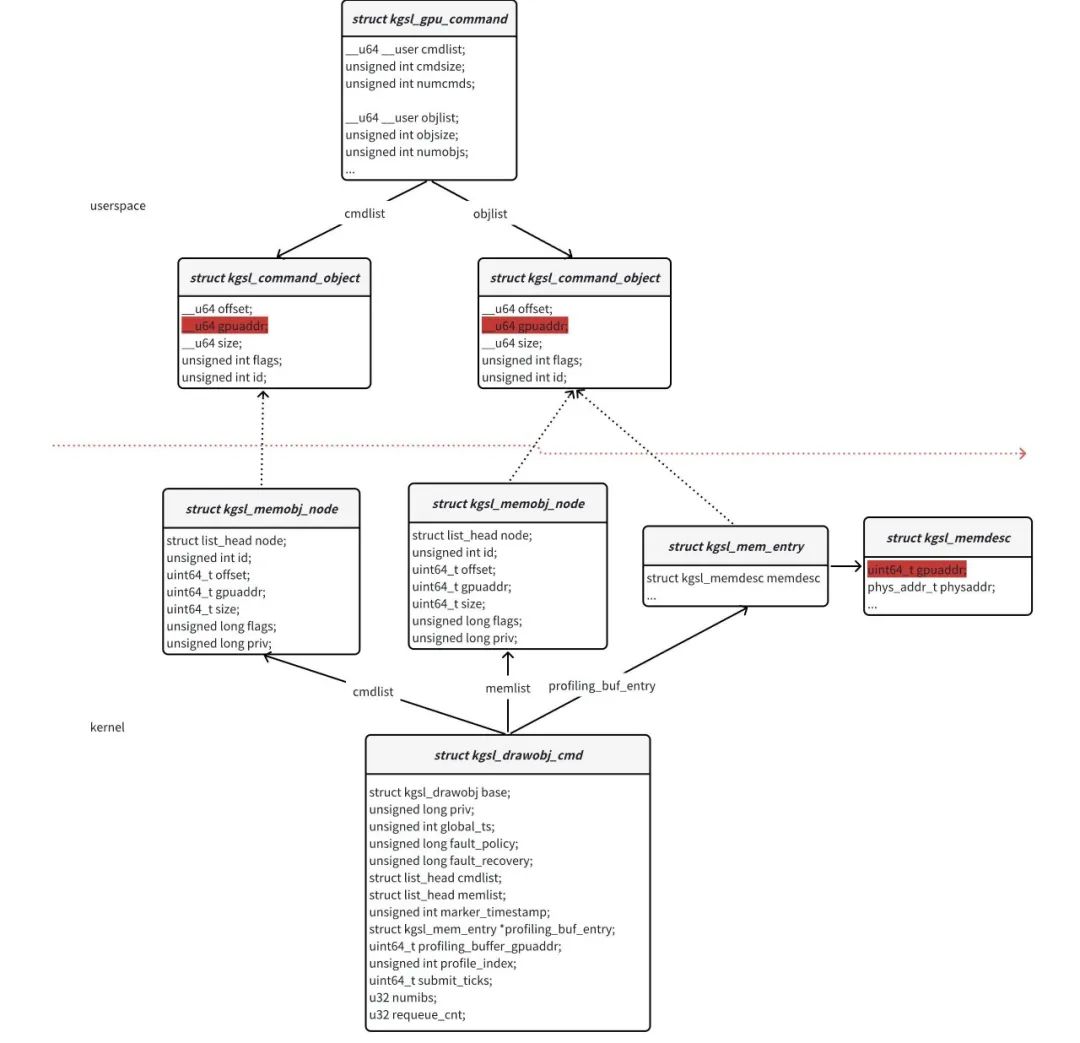
struct kgsl_drawobj_cmd里面保存了两种类型的数据:
(i)一个是指令数据,保存在cmlist变量里。由struct kgsl_gpu_command的cmdlist解析获得。
(ii)一个是对象数据,是输入给指令处理的,保存在memlist变量里和profiling_buf_entry变量里。由struct kgsl_gpu_command的objlist解析获得。SM8650基本上都是profiling_buf_entry。
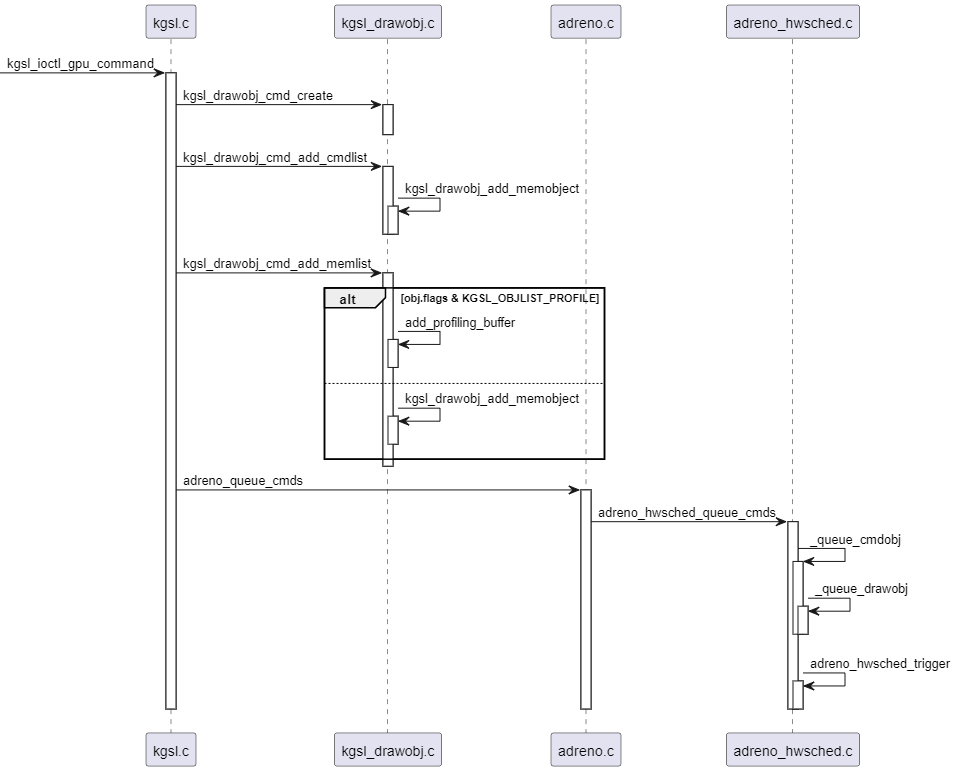
生成struct kgsl_drawobj_cmd实例的时序图如下:
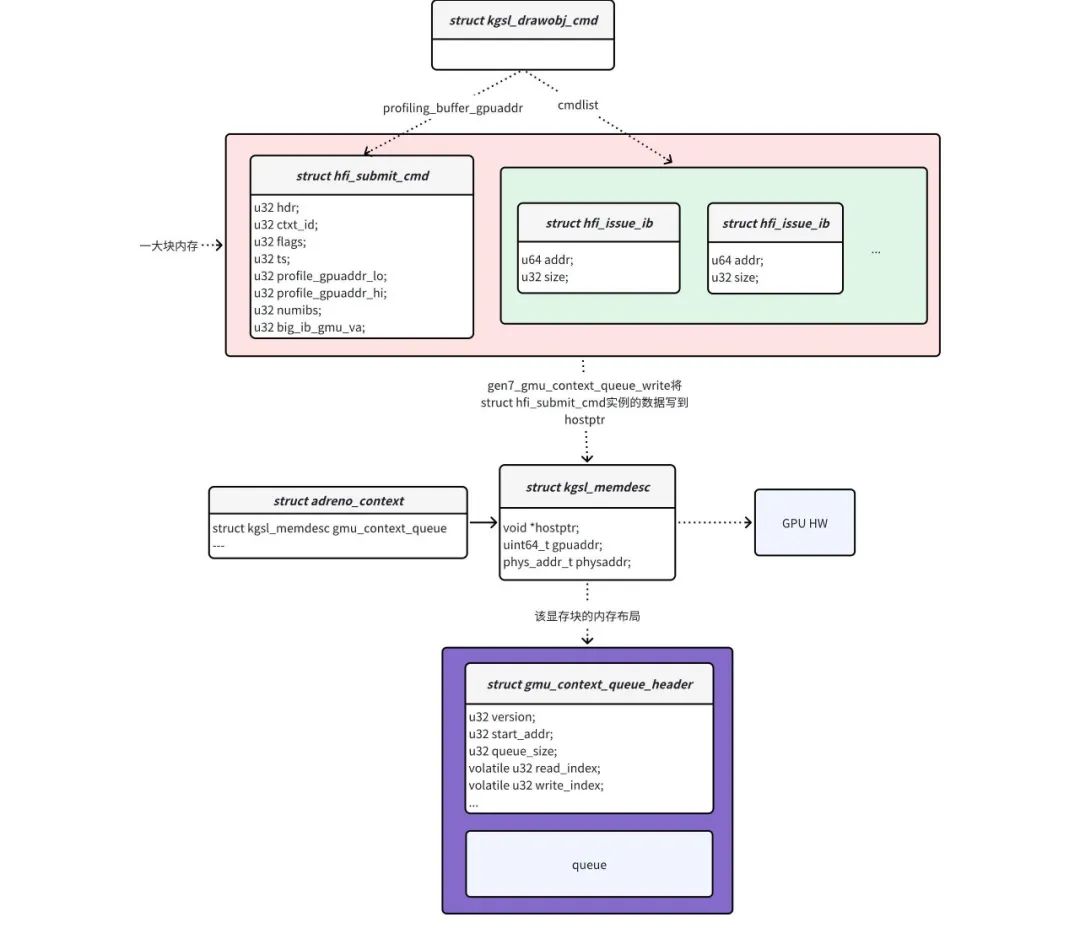
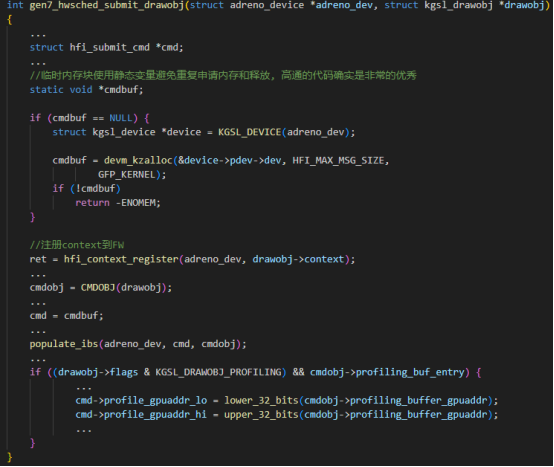
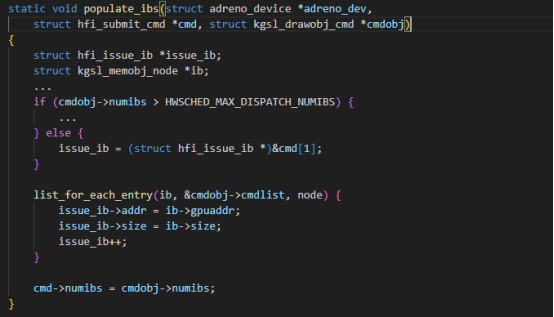
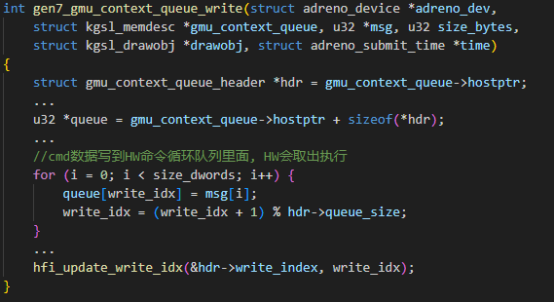
(2)struct kgsl_drawobj_cmd实例处理的关键从gen7_hwsched_submit_drawobj函数开始。gen7_hwsched_submit_drawobj函数先把struct kgsl_drawobj_cmd转成struct hfi_submit_cmd实例和struct hfi_submit_cmd实例,struct hfi_submit_cmd实例和struct hfi_submit_cmd实例都是在一块内存里面。然后在调用gen7_gmu_context_queue_write函数将该内存的数据写到显存里面,GPU FW就会取出送给GPU HW处理。
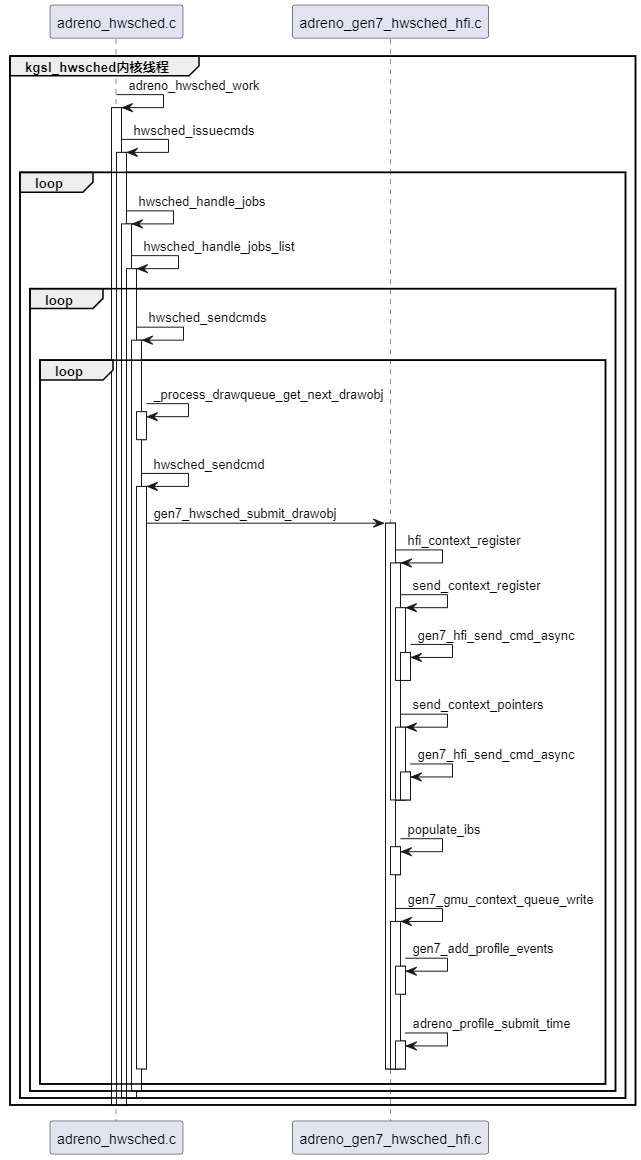
代码时序和详细如下图:
2. gpu fence分析
gpu fence,即gpu创建的fence,由gpu进行signal。queuebuffer代入的fence就是gpu fence,EGLSync/GLsync等也是一个gpu fence。
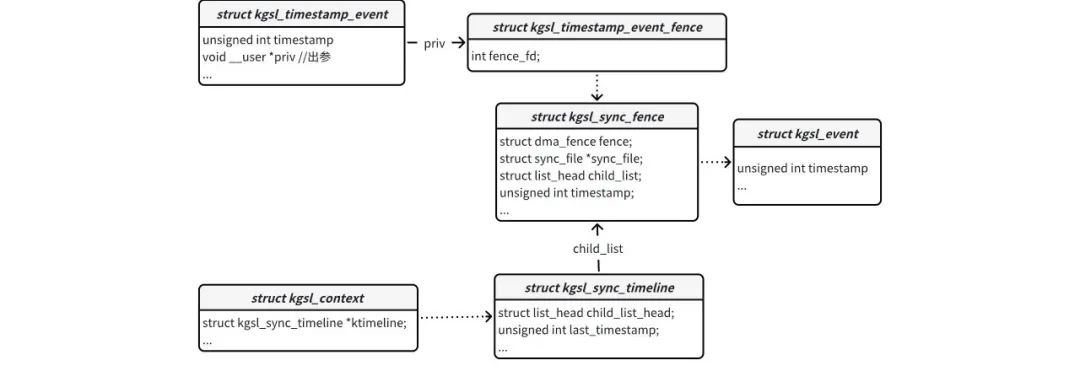
gpu fence在KMD的数据结构为struct kgsl_sync_fence,每个struct kgsl_sync_fence实例会间接关联一个struct kgsl_event实例。
每个context都有个struct kgsl_sync_timeline实例,struct kgsl_sync_timeline实例有一个struct kgsl_sync_fence链表。context创建的gpu fence都保存在这个链表内。
gpu fence都是通过IOCTL_KGSL_TIMESTAMP_EVENT命令通知KMD创建的,该命令的实现函数为kgsl_ioctl_timestamp_event。kgsl_ioctl_timestamp_event创建gpu fence时,会生成一个fence fd,然后把这个fd保存到参数priv变量里带到用户空间。如图:
创建gpu fence的时序图:
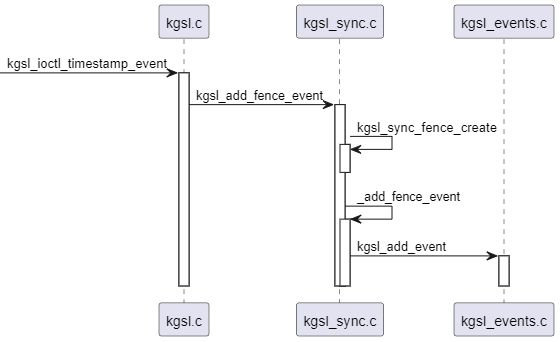
gpu fence借助kgsl events模块signal的,根据上面的分析,我们知道每个gpu fence会关联一个struct kgsl_event实例,该实例timestamp和gpu fence是同一个。该实例signal就是gpu fence signal。struct kgsl_event实例signal流程就不分析了,上面分析过。
struct kgsl_event实例signal,kgsl-events线程被唤醒,执行_kgsl_event_worker函数
执行kgsl_sync_fence_event_cb函数,kgsl_sync_fence_event_cb执行kgsl_sync_timeline_signal函数,kgsl_sync_timeline_signal函数在执行dma fence的回调函数,完成signal操作。时序图如下:
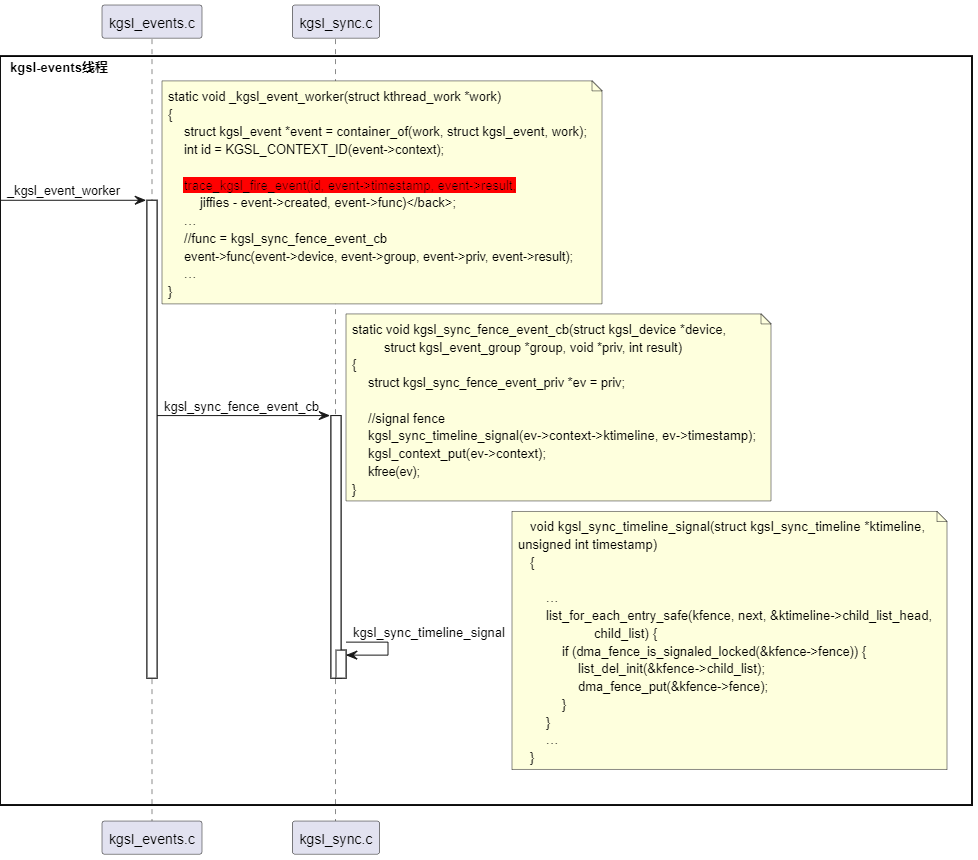
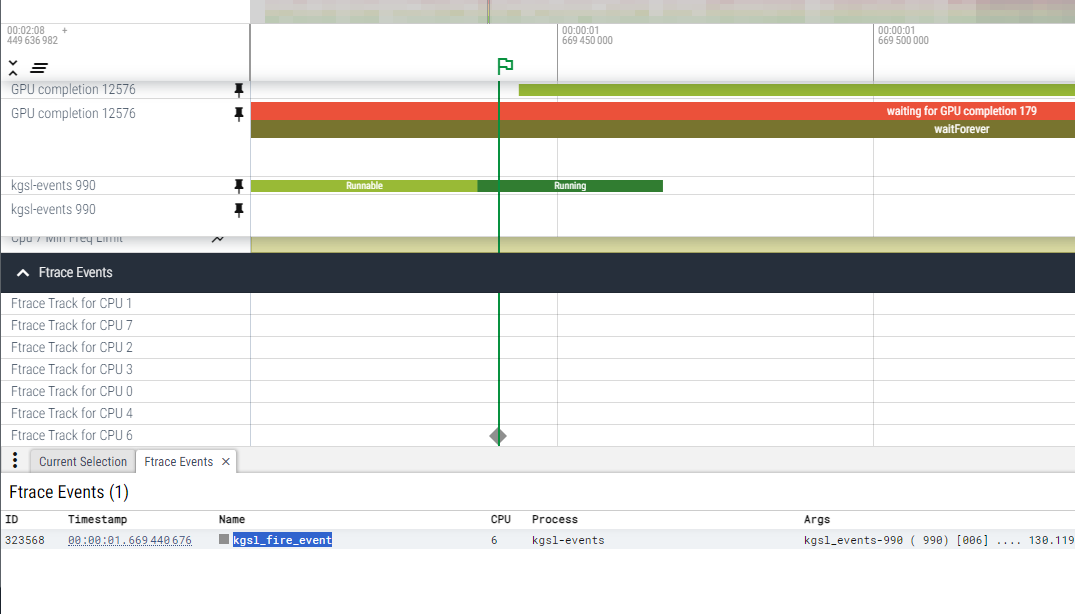
我们可以通过ftrace的kgsl_fire_event进行判断:
3. 一次完整渲染流程分析
在kgsl_ioctl函数加trace,一次eglSwapBuffers,会发起三次ioctl:

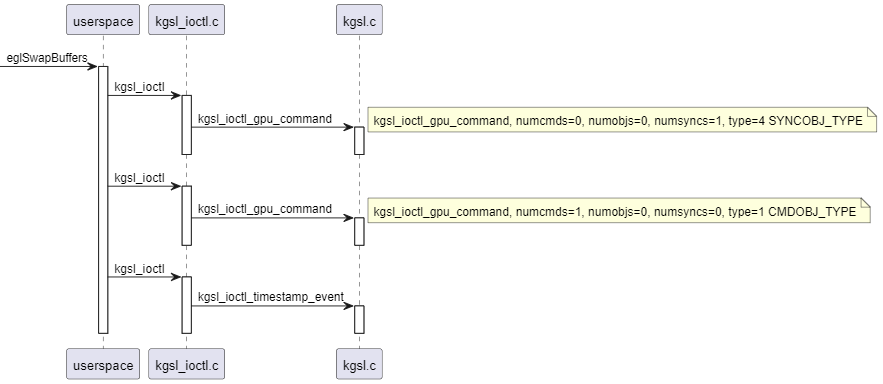
第一次ioctl,fence syncpoint command
第二次ioctl,绘制命令
第三次ioctl,创建gpu fence
我们可以通过ftrace进行分析整个渲染流程:
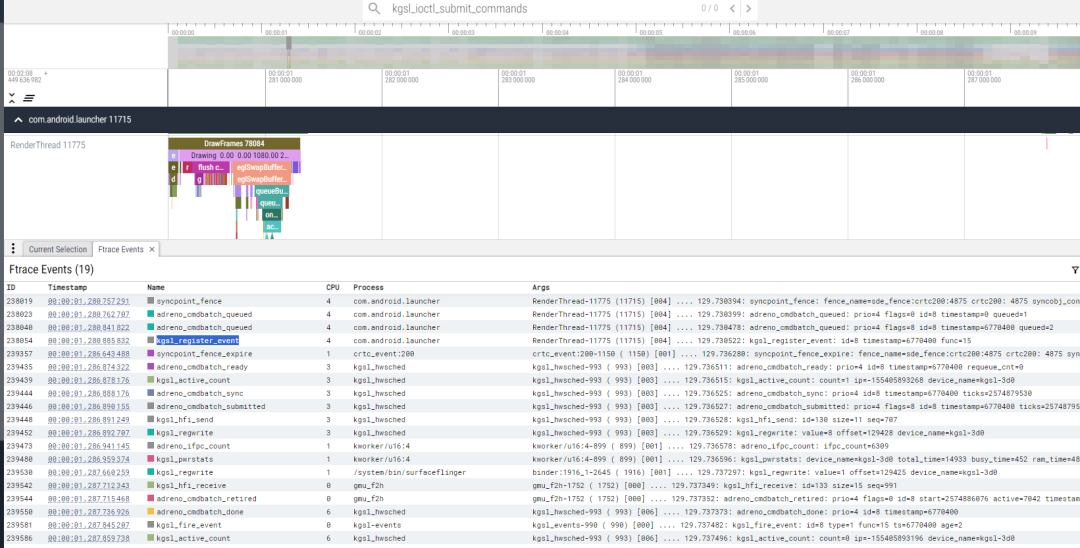
syncpoint_fence:表示解析fence syncpoint command完成
第一个adreno_cmdbatch_queued:表示fence syncpoint command进入待处理队列
第二个adreno_cmdbatch_queued:表示绘制命令进入待处理队列
kgsl_register_event: 表示在创建gpu fence
syncpoint_fence_expire:表示release fence signal
adreno_cmdbatch_submitted:表示指令提交到了GPU HW
kgsl_fire_event:表示gpu fence signal
4. 总结
本文是基于SM8650, Android系统,GLES API进行分析的,并不能适用所有高通平台,系统,图形接口,有一定的局限性。如有疏漏,在所难免,还请读者朋友海涵。
以上所有的代码,都来自开源网站:
https://git.codelinaro.org/clo/la/platform/vendor/qcom/opensource/graphics-kernel/-/tree/gfx-kernel.lnx.14.0.r6-rel?ref_type=heads

往
期
推
荐
Linux内存管理中锁使用分析及典型优化案例总结
Binder驱动中的流程详解
2024年Arm最新处理器架构分析——X925和A725

长按关注内核工匠微信
Linux内核黑科技| 技术文章| 精选教程
这篇关于一文读懂高通GPU驱动渲染流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





