本文主要是介绍MySQL系列:innodb源码分析之redo log恢复,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在上一篇《innodb源码分析之重做日志结构》中我们知道redo log的基本结构和日志写入步骤,那么redo log是怎么进行数据恢复的呢?在什么时候进行redo log的日志推演呢?redo log的推演只有在数据库异常或者关闭后,数据库重新启动时会进行日志推演,将数据库状态恢复到关闭前的状态。那么这个过程是怎么进行的呢?以下我们逐步来解析。
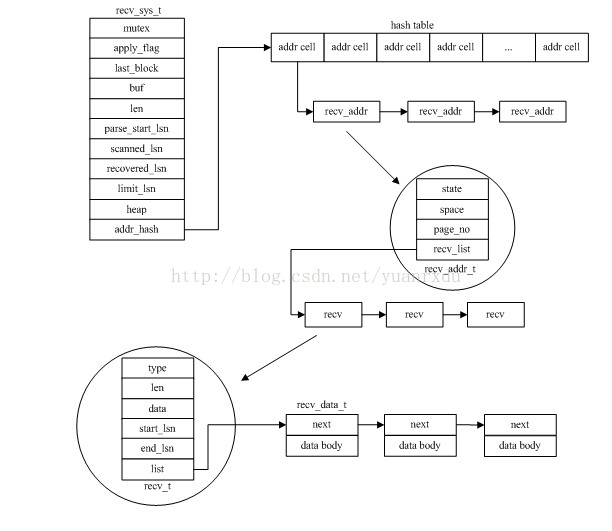
1.recv_sys_t结构
innodb在MySQL启动的时候,会对重做日志文件进行日志重做,重做日志是通过一个recv_sys_t的结构来进行数据恢
复和控制的。它的结构如下:
struct recv_sys_struct
{mutex_t mutex; /*保护锁*/ibool apply_log_recs; /*正在应用log record到page中*/ibool apply_batch_on; /*批量应用log record标志*/dulint lsn;ulint last_log_buf_size;byte* last_block; /*恢复时最后的块内存缓冲区*/byte* last_block_buf_start; /*最后块内存缓冲区的起始位置,因为last_block是512地址对齐的,需要这个变量记录free的地址位置*/byte* buf; /*从日志块中读取的重做日志信息数据*/ulint len; /*buf有效的日志数据长度*/dulint parse_start_lsn; /*开始parse的lsn*/dulint scanned_lsn; /*已经扫描过的lsn序号*/ulint scanned_checkpoint_no; /*恢复日志的checkpoint 序号*/ulint recovered_offset; /*恢复位置的偏移量*/dulint recovered_lsn; /*恢复的lsn位置*/dulint limit_lsn; /*日志恢复最大的lsn,暂时在日志重做的过程没有使用*/ibool found_corrupt_log; /*是否开启日志恢复诊断*/log_group_t* archive_group;mem_heap_t* heap; /*recv sys的内存分配堆,用来管理恢复过程的内存占用*/hash_table_t* addr_hash; /*recv_addr的hash表,以space id和page no为KEY*/ulint n_addrs; /*addr_hash中包含recv_addr的个数*/
};/*对应页的数据恢复操作集合*/
struct recv_addr_struct
{ulint state; /*状态,RECV_NOT_PROCESSED、RECV_BEING_PROCESSED、RECV_PROCESSED*/ulint space; /*space的ID*/ulint page_no; /*页序号*/UT_LIST_BASE_NODE_T(recv_t) rec_list;hash_node_t addr_hash;
};
/*当前的记录操作*/
struct recv_struct
{byte type; /*log类型*/ulint len; /*当前记录数据长度*/recv_data_t* data; /*当前的记录数据list*/dulint start_lsn; /*mtr起始lsn*/dulint end_lsn; /*mtr结尾lns*/UT_LIST_NODE_T(recv_t) rec_list;
};
/*具体的数据体*/
struct recv_data_struct
{recv_data_t* next; /*下一个recv_data_t,next的地址后面接了一大块内存,用于存储rec body*/
};
2.重做日志推演过程的LSN关系
除了这个恢复的哈希表以外,recv_sys_t中的各种LSN也是和日志恢复有非常紧密的关系。以下是各种lsn的解释:
parse_start_lsn 本次日志重做恢复起始的lsn,如果是从checkpoint处开始恢复,等于checkpoint_lsn。
scanned_lsn 在恢复过程,将恢复日志从log_sys->buf解析块后存入recv_sys->buf的日志lsn.
recovered_lsn 已经将数据恢复到page中或者已经将日志操作存储addr_hash当中的日志lsn;
在日志开始恢复时: parse_start_lsn = scanned_lsn = recovered_lsn = 检查点的lsn。
在日志完成恢复时:
parse_start_lsn = 检查点的lsn
scanned_lsn = recovered_lsn = log_sys->lsn。
在日志推演过程中lsn大小关系如下:
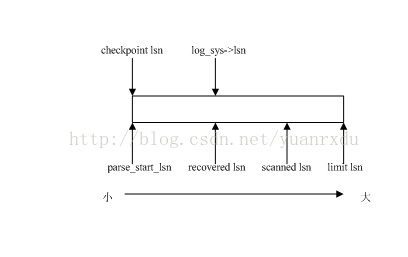
3.日志恢复的主要接口和流程
恢复日志主要的接口函数:
recv_recovery_from_checkpoint_start 从重做日志组内的最近的checkpoint开始恢复数据
recv_recovery_from_checkpoint_finish 结束从重做日志组内的checkpoint的数据恢复操作
recv_recovery_from_archive_start 从归档日志文件中进行数据恢复
recv_recovery_from_archive_finish 结束从归档日志中的数据恢复操作
recv_reset_logs 截取重做日志最后一段作为新的重做日志的起始位置,可能会丢失数据。
recv_recovery_from_checkpoint_finish 结束从重做日志组内的checkpoint的数据恢复操作
recv_recovery_from_archive_start 从归档日志文件中进行数据恢复
recv_recovery_from_archive_finish 结束从归档日志中的数据恢复操作
recv_reset_logs 截取重做日志最后一段作为新的重做日志的起始位置,可能会丢失数据。
重做日志恢复数据的流程(checkpoint方式)
1.当MySQL启动的时候,先会从数据库文件中读取出上次保存最大的LSN。
2.然后调用recv_recovery_from_checkpoint_start,并将最大的LSN作为参数传入函数当中。
3.函数会先最近建立checkpoint的日志组,并读取出对应的checkpoint信息
4.通过checkpoint lsn和传入的最大LSN进行比较,如果相等,不进行日志恢复数据,如果不相等,进行日志恢复。
5.在启动恢复之前,先会同步各个日志组的archive归档状态
6.在开始恢复时,先会从日志文件中读取2M的日志数据到log_sys->buf,然后对这2M的数据进行scan,校验其合法性,而后将去掉block header的日志放入recv_sys->buf当中,这个过程称为scan,会改变scanned lsn.
7.在对2M的日志数据scan后,innodb会对日志进行mtr操作解析,并执行相关的mtr函数。如果mtr合法,会将对应的记录数据按space page_no作为KEY存入recv_sys->addr_hash当中。
8.当对scan的日志数据进行mtr解析后,innodb对会调用recv_apply_hashed_log_recs对整个recv_sys->addr_hash进行扫描,并按照日志相对应的操作进行对应page的数据恢复。这个过程会改变recovered_lsn。
9.如果完成第8步后,会再次从日志组文件中读取2M数据,跳到步骤6继续相对应的处理,直到日志文件没有需要恢复的日志数据。
10.innodb在恢复完成日志文件中的数据后,会调用recv_recovery_from_checkpoint_finish结束日志恢复操作,主要是释放一些开辟的内存。并进行事务和binlog的处理。
2.然后调用recv_recovery_from_checkpoint_start,并将最大的LSN作为参数传入函数当中。
3.函数会先最近建立checkpoint的日志组,并读取出对应的checkpoint信息
4.通过checkpoint lsn和传入的最大LSN进行比较,如果相等,不进行日志恢复数据,如果不相等,进行日志恢复。
5.在启动恢复之前,先会同步各个日志组的archive归档状态
6.在开始恢复时,先会从日志文件中读取2M的日志数据到log_sys->buf,然后对这2M的数据进行scan,校验其合法性,而后将去掉block header的日志放入recv_sys->buf当中,这个过程称为scan,会改变scanned lsn.
7.在对2M的日志数据scan后,innodb会对日志进行mtr操作解析,并执行相关的mtr函数。如果mtr合法,会将对应的记录数据按space page_no作为KEY存入recv_sys->addr_hash当中。
8.当对scan的日志数据进行mtr解析后,innodb对会调用recv_apply_hashed_log_recs对整个recv_sys->addr_hash进行扫描,并按照日志相对应的操作进行对应page的数据恢复。这个过程会改变recovered_lsn。
9.如果完成第8步后,会再次从日志组文件中读取2M数据,跳到步骤6继续相对应的处理,直到日志文件没有需要恢复的日志数据。
10.innodb在恢复完成日志文件中的数据后,会调用recv_recovery_from_checkpoint_finish结束日志恢复操作,主要是释放一些开辟的内存。并进行事务和binlog的处理。
上面过程的示意图如下:
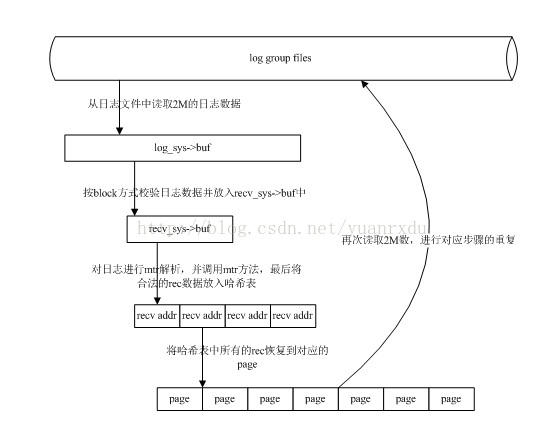
这篇关于MySQL系列:innodb源码分析之redo log恢复的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






