本文主要是介绍数据防泄密,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么要做数据防泄密?
各研发行业都有自己的核心数据以及核心文档,这些数据存在以下共性:
属于核心机密资料,万一泄密会给造成恶劣影响;
核心数据类型多,有源代码数据,员工计算机水平高;
很多数据是业务系统中,不是文件,属于非结构型文件;
如果不管控,设计者和使用者很容易通过各种途径把该数据复制出去,造成泄密;
所以数据防泄密,文件保密等工作非常重要。
研发人员常用的涉密方法;
由于研发人员比普通办公人员要精通电脑,除了常见的网络,邮件,U盘,QQ等数据扩散方法外,还有很多对于研发人员来说非常容易的方法未列全):
物理方法:网线直连,winPE启动,虚拟机,其他非受控电脑中转,网络上传。
数据变形:编写控制台程序,把代码打印到DOS控制台上然后屏幕信息另存;把代码写到Log日志文件中,或把代码写到共享内存,然后另一个程序读走;编写进程间通信程序,把代码通过socket,消息,LPC,COM,mutex,剪切板,管道等进程间通信方式,中转把数据发走;通过IIS/Tomcat等web解析器中转,把代码数据当网页发布出去,然后浏览器浏览后另存,或干脆写个txt框,初始化时把代码都拷贝进来。
外设中转:对于嵌入式开发场景,可以通过串口,U口,网口把代码烧录到设备中转泄密。
数据防泄密的解决方案:
深信达SDC沙盒数据防泄密系统,是专门针对敏感数据防泄密的保护系统,尤其是对研发型企业数据防泄密保护。实现对数据的代码级保护,且不影响工作效率,不影响正常使用。所有敏感数据都自动加密并配合多种管控机制,从而得到有效的范围控制,防止泄密。
1、不影响正常使用
2、支持所有格式
3、数据只进不出,外发需审批;
SDC沙盒系统构成的概念
• 管理端: 系统控制中心,对整个沙盒系统进行管理控制
• 机密端: 源代码及设计文档版本管理服务器,可以有复数台
• 外发审核服务器 ( 可选 ): 外发涉密文件
• 客户端: 防泄密终端,可以有复数台,所有终端源代码,文档全盘透明加密
下面是SDC沙盒整体架构图:
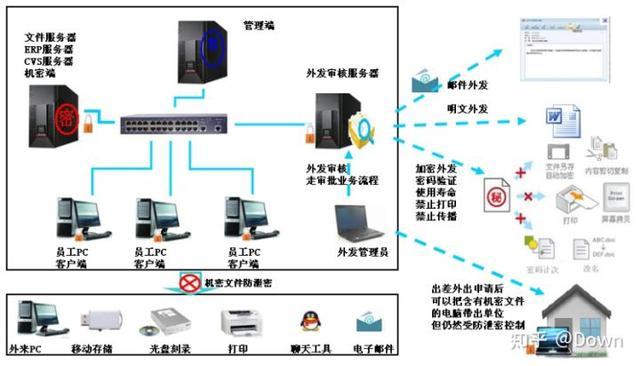
添加图片注释,不超过 140 字(可选)
1、左上角灰色方框内属于安装了沙盒的保密范围,该范围内的电脑无法与方框外的任何设备交互,包括但不限于 其他电脑主机、U盘、光盘刻录、QQ微信、打印机、邮件等。
2、所有文件想要明文发出去,必须经过审批,流程是 用户提交申请-->审核服务器-->审批员通过-->文件通过。通过之后的文件可以和未安装SDC沙盒一样,通过任意软硬件发送出去。
3、针对于不在公司内网的同事,沙盒也可以起到保护作用,这是由于沙盒的策略是保存在客户端本地。还可以设置用户能离线的时间,比如设置7天,超出时间的话会将电脑锁屏,届时只有联系负责沙盒的管理员才能够帮忙解锁。
源代码防泄密是一个复杂而重要的任务,需要综合运用多种技术和方法。通过物理隔离、网络隔离、数据加密、访问控制、行为监控和使用专业的数据防泄密软件,可以有效防止源代码的泄露,保障企业的核心竞争力和信息安全。SDC沙盒作为一种专门针对敏感数据防泄密的保护系统,能够在不影响工作效率的情况下,提供全面的源代码防护,值得IT安全管理员重点关注和使用。
这篇关于数据防泄密的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









