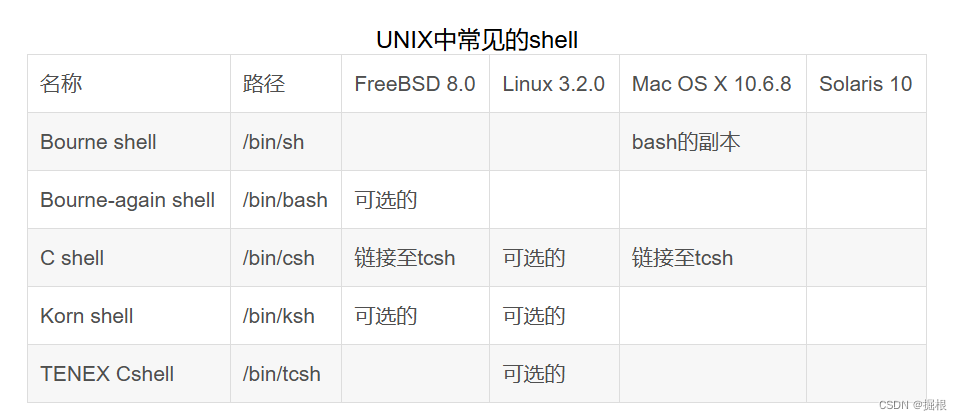
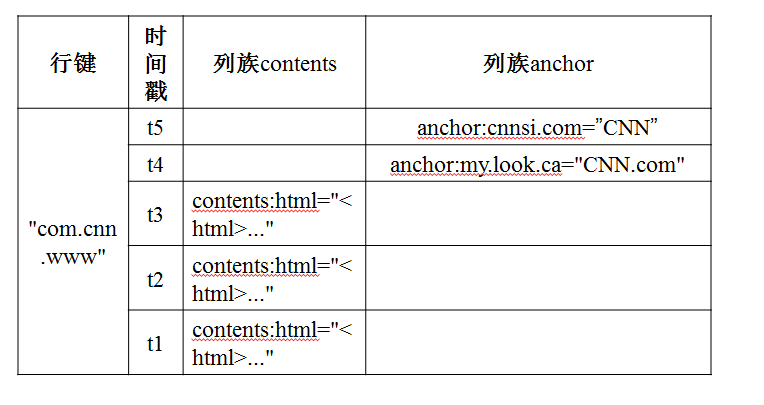
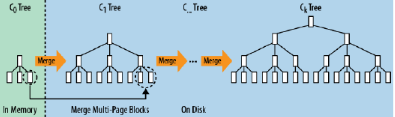
本文主要是介绍hbase中shell命令,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
HBase scan命令详解 - 简书![]() https://www.jianshu.com/p/0ccfd59d73f4
https://www.jianshu.com/p/0ccfd59d73f4
Hbase中多版本(version)数据获取办法_牛奋lch-CSDN博客_hbase 多版本前言:本文介绍2种获取列的多版本数据的方式:shell和spring data hadoop一、hbase shell中如何获取 1、在shell端创建一个Hbase表create 't1','f1' 2、查看表结构describe 't1'表结构如下:Table t1 is ENABLED  https://blog.csdn.net/liuchuanhong1/article/details/53895234/Mac下安装HBase及详解 - 简书
https://blog.csdn.net/liuchuanhong1/article/details/53895234/Mac下安装HBase及详解 - 简书 https://www.jianshu.com/p/510e1d599123
https://www.jianshu.com/p/510e1d599123
Hbase Filter+Scan 查询效率优化_u013465194的博客-CSDN博客_hbase scan 优化Hbase Fileter+Scan 查询效率问题众所周知,Hbase利用filter过滤器查询时候会进行全表扫描,查询效率低下,如果没有二级索引,在项目中很多情况需要利用filter,下面针对这种情况尝试了几种优化的方案,仅供参考,欢迎交流。根据业务要求,作者需要根据时间范围搜索所需要的数据,所以作者设计的rowKey是以时间戳为起始字符串的。正确尝试:1.scan 设置 开始行和结束行...https://blog.csdn.net/u013465194/article/details/83044910
这篇关于hbase中shell命令的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!