本文主要是介绍可视化生信分析利器-Galaxy(第一讲),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是Galaxy
很多公司开始推广他们的可视化生信分析工具,有人说未来的趋势是无代码,分析只要拖拖点点就行了。无代码只能说是一个噱头,毕竟人人都会“用"excel,也不是人人都是数据分析师。
但是一个数据分析师肯定知道如何正确的使用excel,所以一个真正的生信媛/猿也不会嫌弃那些可视化的工具。毕竟写代码累了,没事拖拖点点也是别样的乐趣。
Galaxy就是很多年前在云计算背景下诞生的开源项目, 目前在GitHub上有362个star,165个贡献者。
官方站点: https://usegalaxy.org/,如果感兴趣的话可以在云端玩耍下。

然后,将有一波galaxy学习笔记更新而来。
安装
在正式安装之前,确保自己使用的是Unix/Linux系统,并且安装了Python,且版本是2.7.(最好还有Git)。
galaxy的安装非常简单,就是从github上克隆一份到本地,然后运行部署脚本,然后等着。
# 我习惯把软件安装在biosoft下
cd ~/biosoft
# 克隆到本地
git clone -b release_17.09 https://github.com/galaxyproject/galaxy.git
cd galaxy
# 修改配置文件
cp config/galaxy.ini.sample config/galaxy.ini
# The port on which to listen.
port = 1024
# The address on which to listen. By default, only listen to localhost (Galaxy
# will not be accessible over the network). Use '0.0.0.0' to listen on all
# available network interfaces.
host = 0.0.0.0
# 运行
sh run.sh
我这里简单的修改了配置文件, 使其可以被内网的其他用户通过“IP:1024"的方式访问。

配置
管理员账号
Galaxy后续如果要进行软件安装,管理用户等操作,就必须要先要成为管理员。
第一步: 在galaxy进行注册
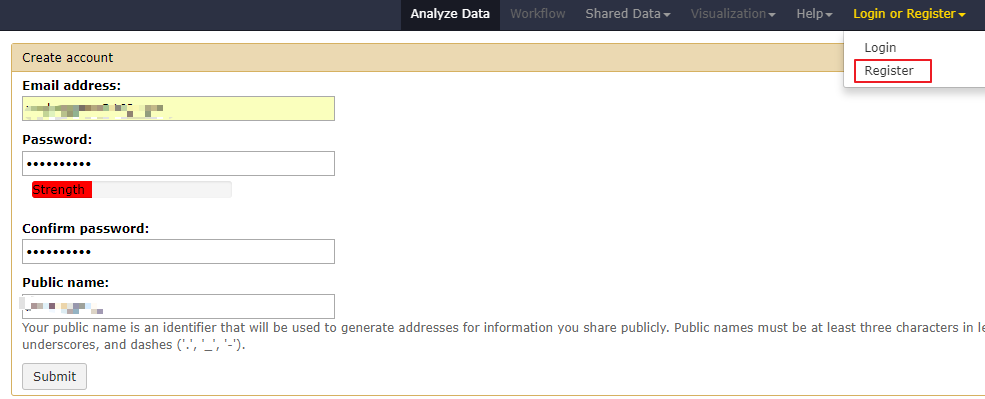
第二步: 修改配置文件config/galaxy.ini,更改其中的admin_users.
# this should be a comma-separated list of valid Galaxy users
admin_users = user1@example.com,user2@example.com
第三步: 重启run.sh或者重新登陆账号,就会发现在工作栏上多了Admin这一部分。
安装软件
安装工具OR下载数据有三种方法:
- 从Tool Shed安装
- 手动添加到Galaxy中
- 脚本自动化完成
其中从Tool shed安装最方便,官方教程介绍的非常详细,跟从APP Store下载软件没有啥太大区别。
如下演示BWA软件如何安装。
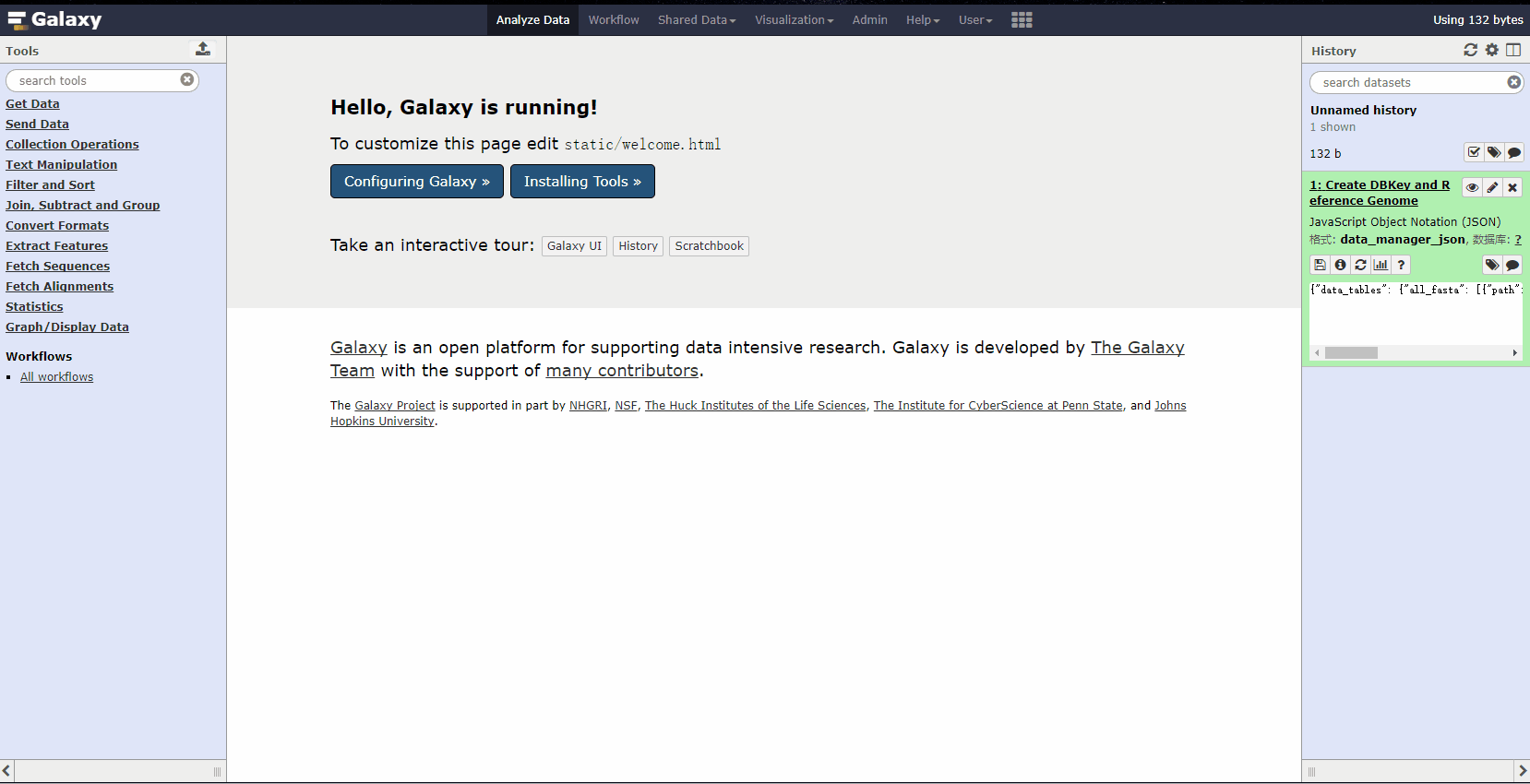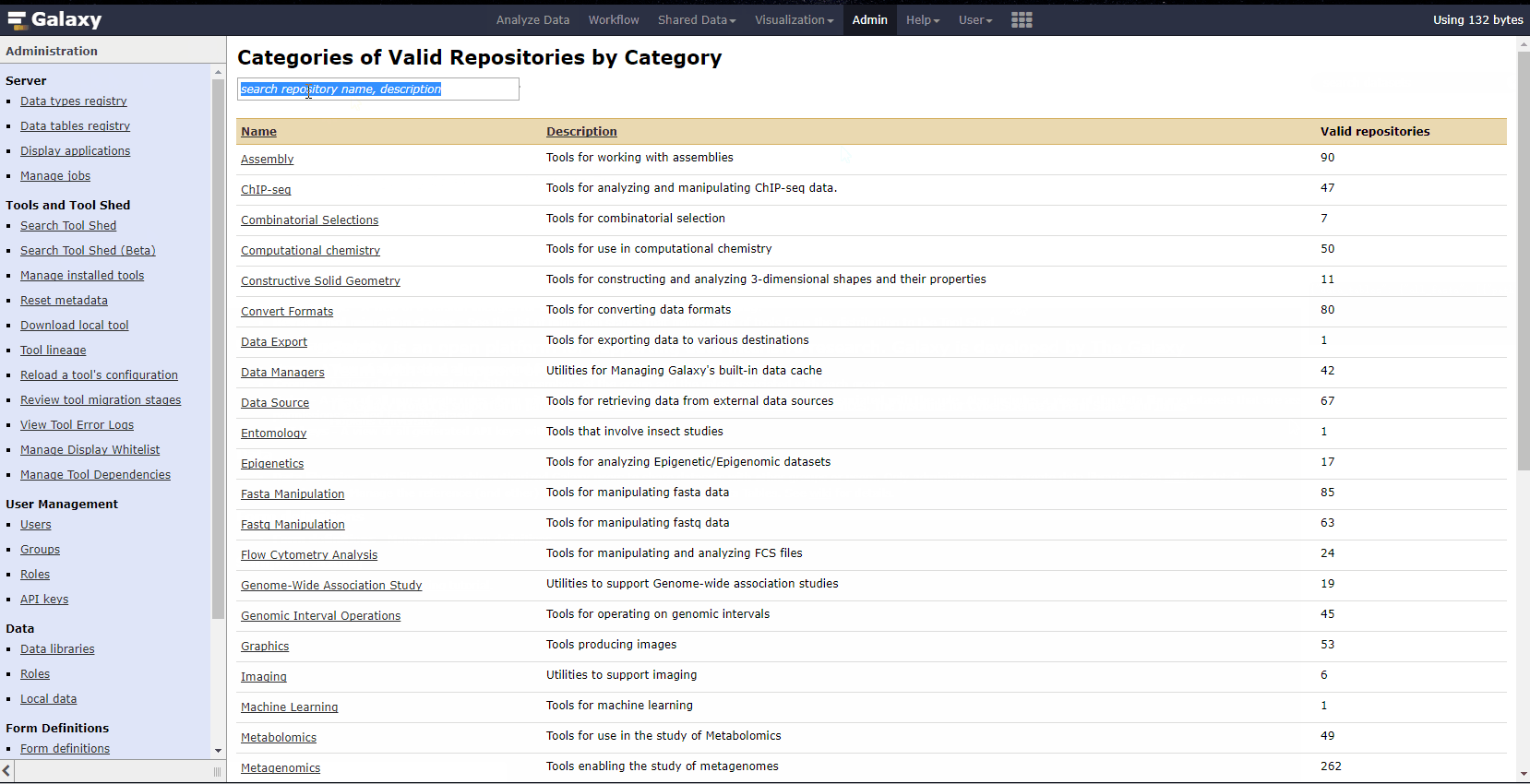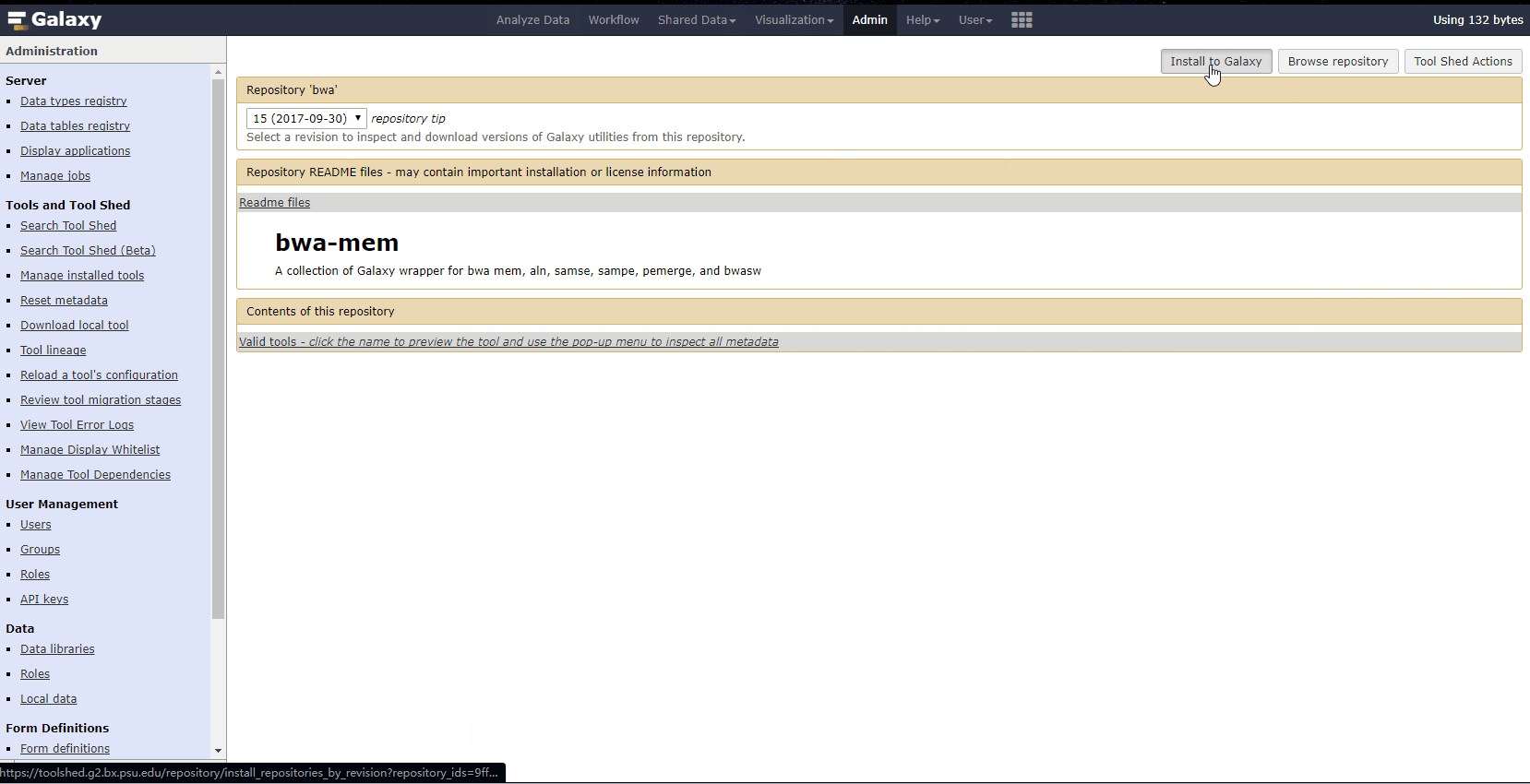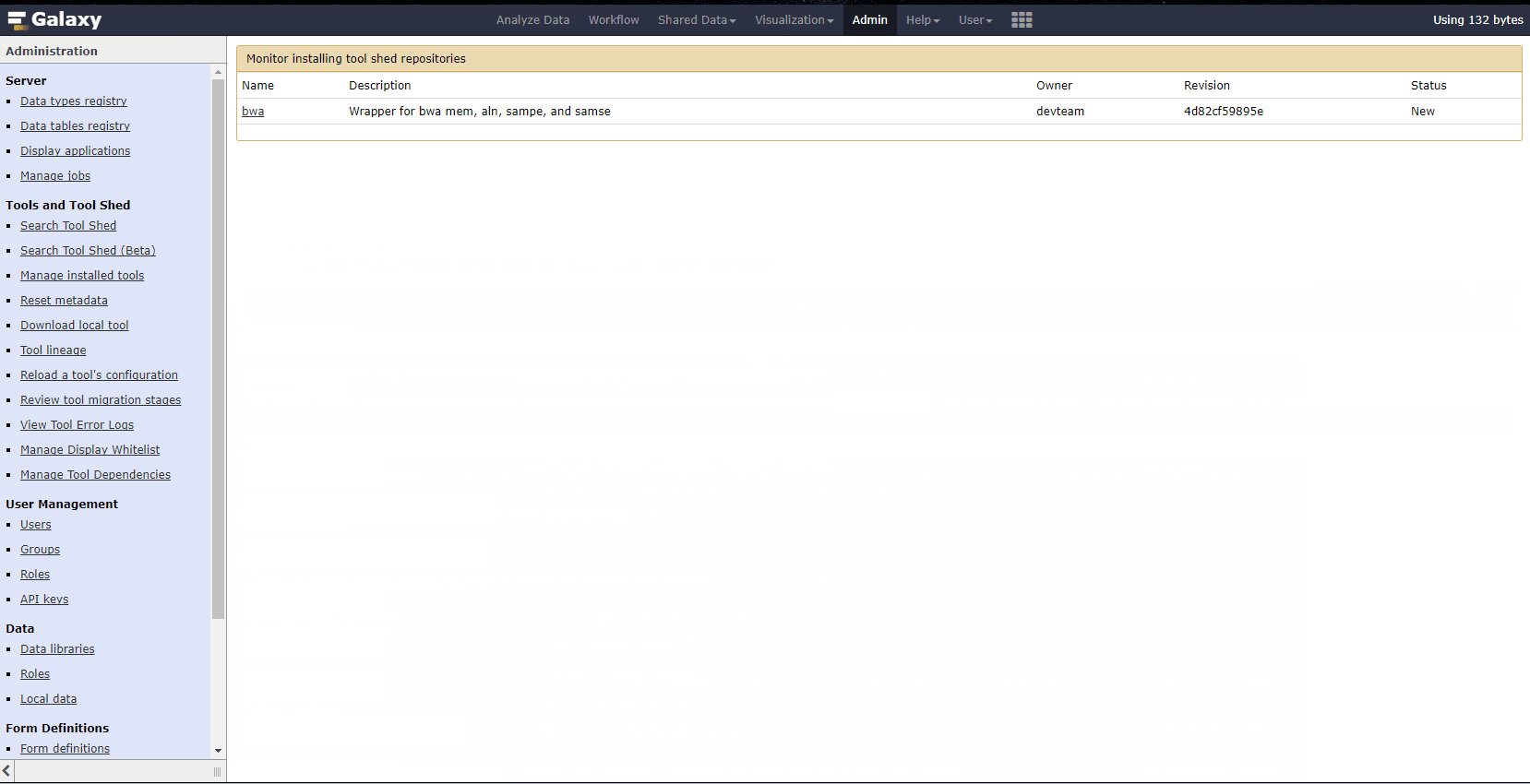
小技巧: galaxy同样利用bioconda进行生信软件管理,因此修改galaxy/config/galaxy.ini中如下行
# conda_ensure_channels = iuc,bioconda,conda-forge,defaults,r
conda_ensure_channels = iuc,https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/,https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/,defaults,r
这行代码仅针对国内用户,感谢清华镜像源。
可视化数据管理
数据管理是一件非常琐碎,非常基础,但是却非常重要的事情。你不能直接把数据丢在一边,假装他已经被你整理了。你必须面对这只”灰犀牛“,知道如何正确的对数据进行管理。
生信分析的数据可以分为以下几类:
- 参考序列,注释文件,索引文件
- 用户上传数据
- 分析过程中所产生的数据
Galaxy建立了专门的数据管理体系,用于记录这几类数据,便于不同工具间的交互。
Part I:准备参考基因序列并建立索引。
和这部分相关的工具位于Data Managers和Data source两个工具分类下。

这一部分需要安装的工具如下,请参考安装软件一节完成安装。
- data_manager_fetch_genome_dbkeys_all_fasta
- data_manager_bwa_mem_index_builde
- data_manager_bowtie2_index_builder
- data_manager_fetch_gene_annotation
- data_manager_hisat2_index_builder
安装完成之后,点击admin的local data会出现如下内容。

hu
以拟南芥为例, 我事先在TAIR上复制了其参考基因组的下载地址, 随后在admin的local data中选择"ata_manager_fetch_genome_dbkeys_all_fasta"进行下载。

hua
随后就能在如下的"Data Manager Jobs"查看运行进程。

不难发现,其实我也是在2次失败的尝试后,才找到的正确地使用方式。但是由于我重复添加同一个物种,结果后面各种报错,于是我就只能使用了最后的绝招--重装Galaxy。
后续需要对参考基因组建立索引,过程和上面的一致,只不过你需要选择BWA-MEM index,之后就是点点然后等几分钟就行了。
如果是人类的参考基因组,可以考虑下载已有的索引,然后修改galaxy的配置文件。
Part II: 用户上传数据
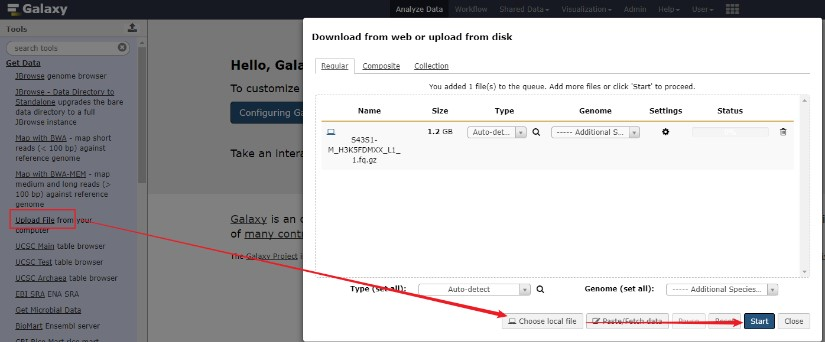
用户上传数据这一块比较简单,如下图选择Upload File, 然后从本地选择需要的数据进行上传即可。
Part III: 中间数据。 这个部分目前不需要担心,你可以将分析结果下载到本地,然后在本地用IGV进行查看。这个部分在workflow会继续再介绍。

下一讲
如何自动化安装软件?如何配置galaxy项目还没有的工具?大规模数据应该如何上传?
这些内容见下一讲吧。
这篇关于可视化生信分析利器-Galaxy(第一讲)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





