本文主要是介绍「Bionano系列」下机数据的BNX文件到底说了什么,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我拿到了一批Bionano数据,用关键字 “Bionano+组装” 进行检索时,并没有发现任何的教程,所以这应是中文网络世界里第一个Bionano数据分析系列
Bionano技术简单来说,就是给分子加上荧光标记,然后拍照,所以最原始的下机数据就是TIFF格式,但是用户拿到的一般都是经AutoDetect/IrysView 转换过的BNX格式。这篇文章主要就是讲讲BNX格式的具体含义。
根据Bionano的30038号文件,即"BNX File Format Specification Sheet"的定义,
The Bionano Genomics® BNX file is a raw data view of molecule and label information and quality scores per channel identified during a run. BNX v1.3 supports one or two label channels (colors).
BNX记录的是在泳道中每个单分子原始信息,包括分子中的标记信息和每个泳道的质量得分

类似于SAM/VCF这类格式,BNX也分为两个部分,元信息行和数据行。
元信息行中比较容易理解的行是下面几个,基本不需要解释

后面的"#rh" 和" Run Data" 会稍微复杂一些。但是"rh"其实是Required Headers的缩写,记录的是"Run Data"中一定要有的列, 而"Run Data"每一行表示的是不同的队列(corhart)或者称之为泳道。我会着重看以下几个记录
- SNRFilterType: 信噪比的过滤类型,如果有这一列,就表示你后续就不用做SNR Filter
- MinMoleculeLength: 所允许的最短的分子长度
- MinLabelSNR:所允许的最低标记的SNR
下面的"0h",“1h”,“Qh”, “QX11”,“QX12” 需要结合数据行才能理解。首先要明确一点,对于单酶系统(Label Channels: 1),每个分子都会对应4个数据行。
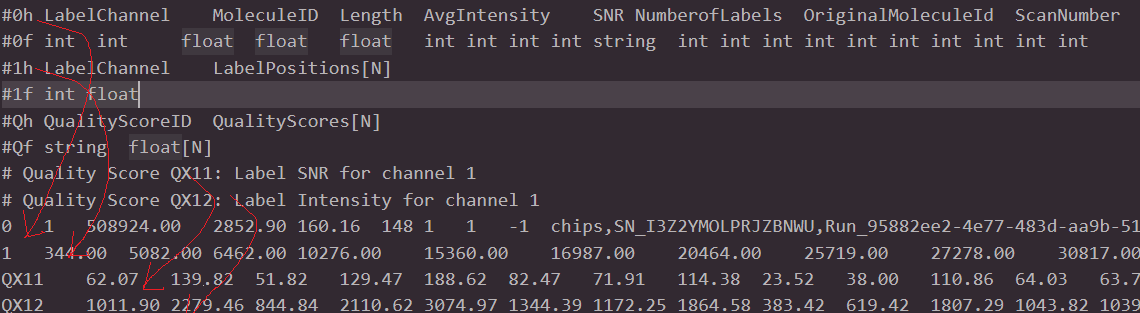
“0h” 记录的是每个分子中简要信息,例如分子的长度(length), 信噪比(SNR), 标记的数目(NumberofLabels), 其中"0f"则是告诉程序它将要解析的数据格式是什么。
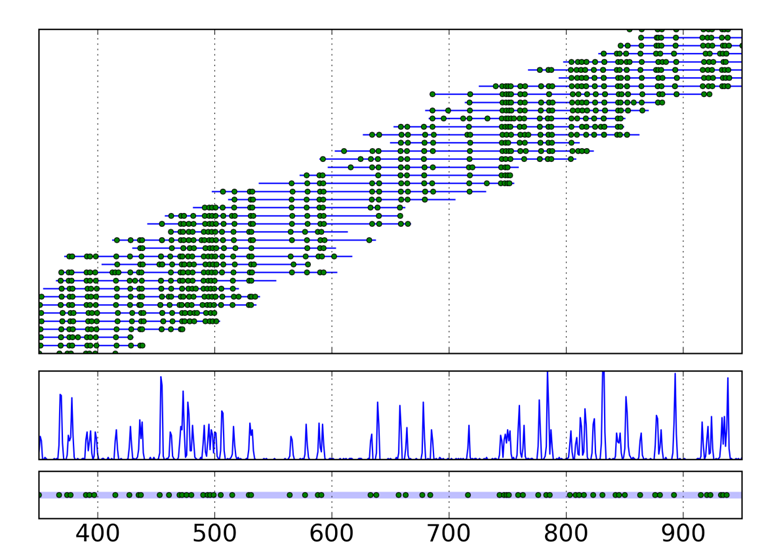
“1h” 记录的是每个标记的位置信息,对应"0h"中的NumberofLabels。标记间的相对位置信息就是后续进行组装和比对的基础,如下图所示。
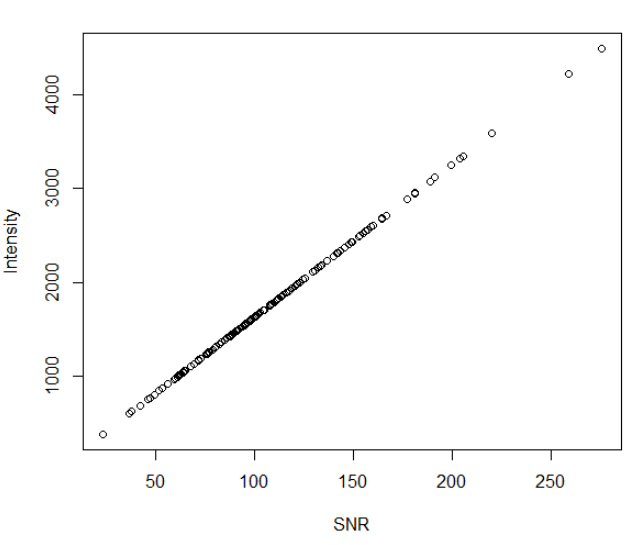
“Qh” 中的QualityScoreID对应"QX11",“QX12”,而QualityScores[N]表示会记录N个质量分数。"QX11"记录的每个标签的信噪比(SNR), "QX12"则是记录信号强度,这两者正相关。 同样"Qf"则是告诉程序它将要解析的数据格式是什么。
介绍完数据格式后,你会有一个问题,如何评判数据的好坏呢?以及如何进行数据质量控制?
我们可以根据以下质标评估数据的好坏:
- 标记密度(Label Density): 一般NRLS为 8-15 Labels/100Kb, DLS 为 10-25 Labels/100Kb
- 分子量 N50:评估总体分子的长度
- 假阳性(FP): 原本没有标记的地方识别出信号
- 假阴性(FN): 原本应该有标记的地方却没有信号
- 比对率(Mapping Rate): 有多少分子能够回贴到基因组上。
那么这些评估信息如何获取呢?请期待后续的更新
这篇关于「Bionano系列」下机数据的BNX文件到底说了什么的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







