本文主要是介绍一些3D数据集的简单介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Objaverse 1.0
Objaverse 1.0: a large dataset of objects with 800K+ (and growing) 3D models with descriptive captions, tags and animations. Assets not only belong to varied categories like animals, humans, and vehicles, but also include interiors and exteriors of large spaces that can be used, e.g., to train embodied agents(具身智能是Embodied Intelligence,这个应该可以理解为机器人)
Objaverse 1.0 includes 818K 3D objects. There are >2.35M tags on the objects, with >170K of them being unique. We estimate that the objects have coverage for nearly 21K WordNet entities. Objects were uploaded between 2012 and 2022, with over 200K objects uploaded just in 2021. 下图是Objaverse数据集的一些数据展示,包括物体所属的Sketchfab categories、tags的词云、tags的频率图、Objaverse-LVIS categories中的object数量
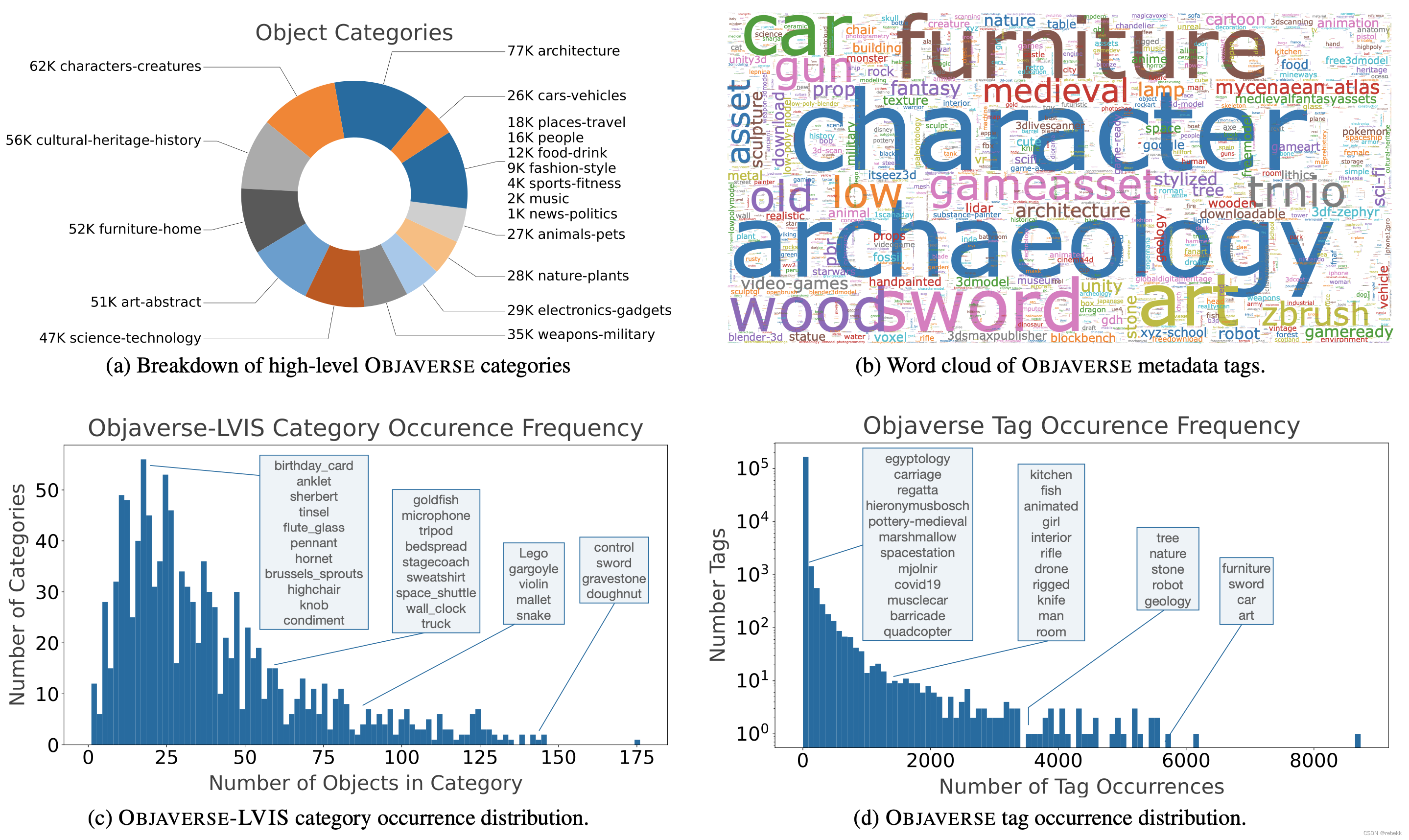
Objaverse contains 3D models for many diverse categories including tail categories which are not represented in other datasets. It also contains diverse and realistic object instances per category. Qualitatively, the 3D-meshes generated by the Objaverse-trained models are high-quality and diverse, especially when compared to the generations from the ShapeNet-trained model.

上图是Objaverse的作者,分别基于Objaverse的Bag分类和ShapeNet的bag分类,训练了一个模型,生成的3D物体效果。结果就是前者质量更高一点,然后说是91%的情况下Objaverse训练的模型生成的物体在外观上更具多样化
The objects are sourced from Sketchfab, an online 3D marketplace where users can upload and share models for both free and commercial use. Objects selected for Objaverse have a distributable Creative Commons license and were obtained using Sketchfab’s public API.
Objaverse objects inherit a set of foundational annotations supplied by their creator when uploaded to Sketchfab. 下图展示了每个model的可用metadata示例,metadata包括一个名字、一些固定属性、一些tags、和一个自然语言描述


上图是Objaverse和ShapeNet数据集关于车辆、床铺、花瓶和书包这四类的物体模型对比,可见ShapeNet的模型相比起来就非常简单,因为Objaverse的对象来自许多3D内容创建平台,而ShapeNet都来自SketchUp(一个为简单的建筑建模而构建的3D建模平台)。91%的情况下Objaverse训练的模型生成的物体在外观上更具多样化
Objaverse-XL: 2023.7.11
Objaverse-XL is 12x larger than Objaverse 1.0 and 100x larger than all other 3D datasets combined.
Objaverse-XL comprises of over 10 million 3D objects, representing an order of magnitude more data than the recently proposed Objaverse 1.0 and is two orders of magnitude larger than ShapeNet.
Objaverse-XL is comprised of 10.2M 3D assets.
Objaverse-XL is composed of 3D objects coming from several sources, including GitHub, Thingiverse, Sketchfab, Polycom, and the Smithsonian Institution. While the data sourced from Sketchfab for our project is specifically from Objaverse 1.0, a dataset of 800K objects consisting of Creative Commons-licensed 3D models. Each model is distributed as a standardized GLB file.
Objaverse-XL评Objaverse 1.0:Objaverse 1.0 introduced a 3D dataset of 800K 3D models with high quality and diverse textures, geometry and object types, making it 15× larger than prior 3D datasets. While impressive and a step toward a large-scale 3D dataset, Objaverse 1.0 remains several magnitudes smaller than dominant datasets in vision and language. As seen in Figure 2 and Table 1, Objaverse-XL extends Objaverse 1.0 to an even larger 3D dataset of 10.2M unique objects from a diverse set of sources, object shapes, and categories.

ShapeNet: 2015.12.9
Objaverse-XL评ShapeNet:ShapeNet has served as the tesetbed for modeling, representing and predicting 3D shapes in the era of deep learning. Notwithstanding its impact, ShapeNet objects are of low resolution and textures are often overly simplistic. Other datasets such as ABO, GSO, and OmniObjects3D improve on the texture quality of their CAD models but are significantly smaller in size.
Objaverse-XL评ShapeNet:3D datasets such as ShapeNet rely on professional 3D designers using expensive software to create assets, making the process tremendously difficult to crowdsource and scale.
ShapeNet has indexed more than 3,000,000 models, 220,000 models of these models are classified into 3,135 categories (WordNet sunsets).
In order for the dataset to be easily usable by researchers it should contain clean and high quality 3D models. We identify and group 3D models into the following categories: single 3D models, 3D scenes, billboards, and big ground plane. We currently include the single 3D models in the ShapeNetCore subset of ShapeNet.
ShapeNetCore is a subset of the full ShapeNet dataset with single clean 3D models and manually verified category and alignment annotations. It covers 55 common object categories with about 51,300 unique 3D models.

这篇关于一些3D数据集的简单介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





