本文主要是介绍【课程总结】Day10:卷积网络的基本组件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
由于接下来的课程内容将围绕计算机视觉展开,其中接触最多的内容是卷积、卷积神经网络等…因此,本篇内容将从卷积入手,梳理理解:卷积的意义、卷积在图像处理中的作用以及卷积神经网络的概念,最后利用pytorch搭建一个神经网络。
卷积的理解
卷积其实是一个数学概念
在第一次接触到"卷积"的概念时,我与大多数人的想法类似,首先想的问题是,“卷积"到底是怎样的一个"卷”?
在网上搜索卷积的概念之后,我初步了解到卷积本质上是一个数学问题,它的表示如下:
( f ∗ g ) ( t ) = ∫ − ∞ ∞ f ( τ ) g ( t − τ ) d τ (f * g)(t) = \int_{-\infty}^{\infty} f(\tau)g(t-\tau) d\tau (f∗g)(t)=∫−∞∞f(τ)g(t−τ)dτ
以上的表示过于抽象,所以通过搜索B站的视频,找到了介绍卷积较为形象的示例。
卷积的理解示例(吃饭问题)
示例:如果用图示来表示一个人的吃饭情况,那么他进食的过程和消化的过程可以用如下图来分别表示
进食过程:用f函数来表示进食,横坐标是时间,纵坐标是进食(也就是吃东西)了多少。

消化过程:消化的过程与进食是独立,吃的东西进入胃里面会进行消化,这个过程可以用g函数来表示。横坐标是时间,纵坐标是剩余食物的比例。

此时,如果我们想知道这个人在下午2点时,胃里还剩多少食物。这个问题如果直接求解是不好求解的,但是如果借助上面的两个函数,就比较容易可以求得,具体如下:

- 首先,通过f函数求积分,可以得到14点之前所有吃的东西;
- 其次,假设该人在12点吃了一碗米饭,那么通过g函数可以求得:14点~12点时,米饭还剩余的比率;
- 然后:将12点吃的米饭f(12) 与 14点米饭剩余的比率g(14-12)相乘,就可以得到米饭在14点时还剩余多少。
- 依次类推,如果吃了多个食物,那么在14点食物剩余的比例就可以如下表示

由此,推导得到这个人在t时刻,胃里剩余食物的比例可以用如下的公式表示:

上面的公式因为是求吃饭问题场景下的食物剩余比例,所以积分上下限是0~t;如果是将此问题场景换成其他场景,只需要把公式中做微调如下,即可求更加广泛的问题:
( f ∗ g ) ( t ) = ∫ − ∞ ∞ f ( τ ) g ( t − τ ) d τ (f * g)(t) = \int_{-\infty}^{\infty} f(\tau)g(t-\tau) d\tau (f∗g)(t)=∫−∞∞f(τ)g(t−τ)dτ
卷积:在一个系统中,输入不稳定、输出稳定的情况下,可以用卷积求系统的存量。
例如:
在一个热力系统中,可以利用卷积计算:燃料持续添加 f ( τ ) f(\tau) f(τ)和燃料持续燃烧 g ( t − τ ) g(t-\tau) g(t−τ)下,燃烧过程中产生的总热量。
在一个信号系统中,信号持续输入 f ( τ ) f(\tau) f(τ)和系统的响应 g ( t − τ ) g(t-\tau) g(t−τ)下,信号对系统产生影响的累积效果。
上述对卷积的理解,还可以换一种角度(例如:蝴蝶效应)来理解:

在t时刻发生了一件事,t时刻之前很多事情都会产生影响,而其中x时刻对t时刻的影响(g函数)是随着时间逐步减弱的。
卷积是如何卷的
对于上述的f函数和g函数在t时刻的对应关系,可以用如下图表示:
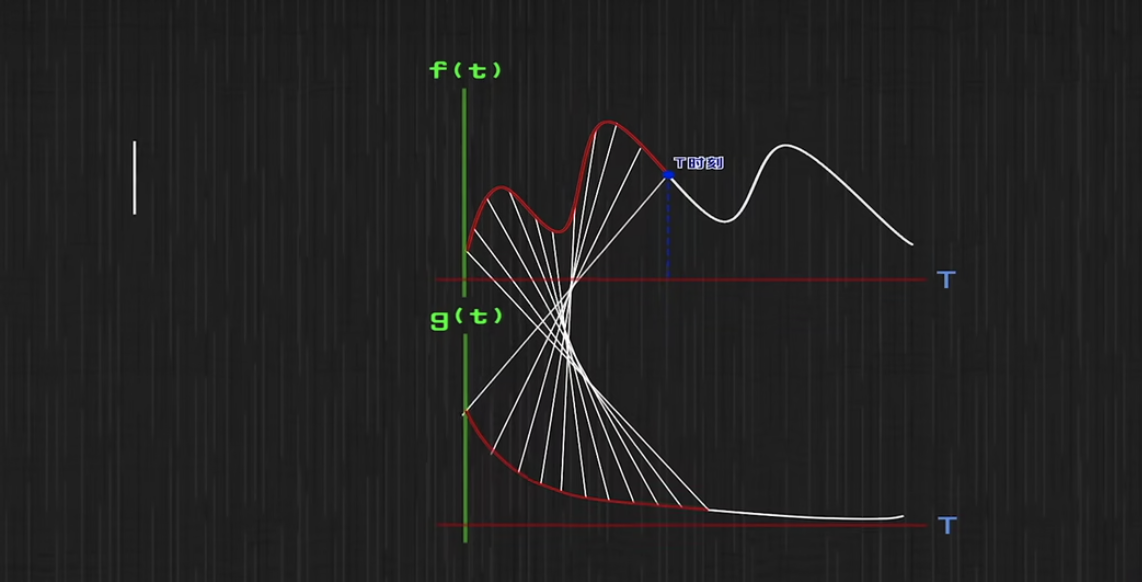
-
在t时刻进食的食物f(t),此时在消化过程g(t)时刚开始,所以对应g(t)函数图的最左侧;
-
在t时刻之前时刻进食的食物f(t),则对应对应消化过程g(t)的第二个点(从左向右)。
备注:此处对于上图其他点的理解,得用逆转的思想来理解。
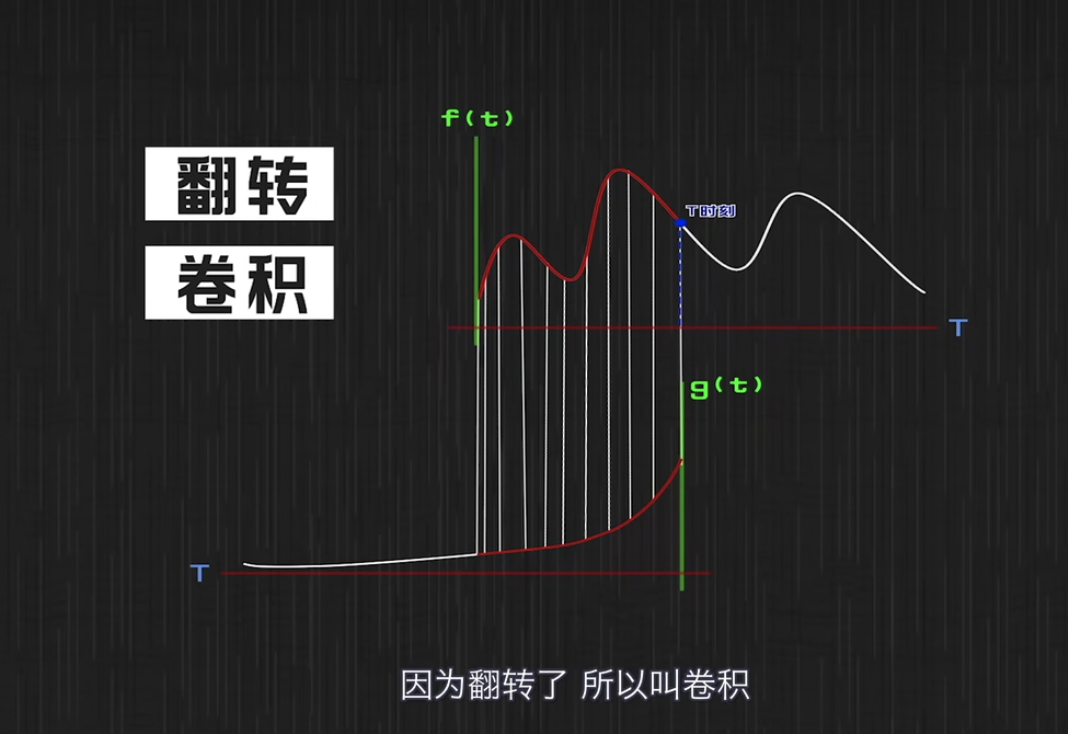
将上图的g函数做翻转,上下两图的对应关系就更加清晰。因为这个翻转,所以称之为"卷积"。
卷积在图像处理中的作用
在《【课程总结】Day8(下):计算机视觉基础入门》中,我们学习了解过:
- 图片本质上就是一个二维的矩阵;
- 通过一个3×3的矩阵与原图进行相乘再相加的计算,可以得到一个新的图片。
- 通过设计不同的3×3矩阵内容,可以得到不同的新图片。

在上图这个计算过程中,其与卷积有着相同之处:
- 计算过程相同:先相乘再相加(计算周围像素点与中间像素点)
- 计算整体情况相同:对源像素依次扫一遍,得到一个结果
上图计算过程,本质上是计算周围像素点对中间像素点的影响,因此套用吃饭问题可以如下图来理解:

上图中左下角的点对中心点的影响,可以换做是x时刻的事件对t时刻的影响,以此来理解图像中卷积的意义。
至此,在图像处理中:
- 卷积过程:计算周围像素点对中心点像素的影响
- f函数:即为输入的原图片
- g函数:即为卷积核,其规定了要对原图片如何影响
卷积神经网络的理解
卷积神经网络一般是用来做图像识别的,通过卷积神经网络可以将下面的图片中的X分别识别出来。
- 通过对图片进行特征提取,可以得到图像中的像素情况
- 但实际场景中X一般不是规规整整的写的(如下图),这种情况人是可以一眼识别都是X,但是计算机在像素计算时,由于下面两个像素点不同,是无法识别两个表示的是一个东西。

虽然上述图片的整体像素不同,但是仔细看,可以看到局部是相同的:

所以,如果利用之前学习的机器学习思想:
- 将图片(本质是矩阵)作为输入
- 将卷积核作为待调整的参数
- 让卷积运算作为机器学习的一部分
- 让机器学习寻找特征,寻找过程中:
- 可以将一个卷积的操作,作为另外一个卷积的输入
- 对于一个特征矩阵,可以利用不同的卷积核,生成不同的特征矩阵
- 将这些输入输出全部连接到一起
由此,我们得到一个与人体神经系统类似的网络,卷积神经网络。



卷积网络组件
BatchNorm层
定义
Batch Normalization是一种用于神经网络的技术,通过在神经网络的每一层对输入进行归一化处理,即将每个特征维度的数据归一化为均值为0、方差为1的分布,以减少内部协变量转移(Internal Covariate Shift)。
作用:
- 加速收敛:Batch Normalization有助于加速神经网络的收敛速度,减少训练时间。
- 减少梯度消失/爆炸:通过归一化输入,可以减少梯度消失或爆炸的问题。
- 正则化效果:Batch Normalization在一定程度上具有正则化的效果,有助于防止过拟合。
计算公式
对于输入 (x),Batch Normalization的计算公式如下:
x ^ = x − μ σ 2 + ϵ \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} x^=σ2+ϵx−μ
y = γ x ^ + β y = \gamma \hat{x} + \beta y=γx^+β
其中:
- μ \mu μ 是均值
- s i g m a 2 sigma^2 sigma2 是方差
- γ \gamma γ 和 β \beta β 是可学习的缩放和偏移参数
- ϵ \epsilon ϵ是一个很小的数,用于避免除以零

ReLU层
定义
ReLU是一种简单而有效的激活函数,其数学表达式为 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x),即当输入 (x) 大于零时输出为 (x),否则输出为零。
作用
- 非线性:ReLU引入了非线性,有助于神经网络学习复杂的模式和特征。
- 稀疏性:ReLU的输出在负值部分为零,可以使网络更加稀疏,减少参数之间的相关性,有助于防止过拟合。
- 计算速度:ReLU的计算速度快,且不存在复杂的指数运算,适合大规模深度学习模型。
线性层
定义
线性层是神经网络中的基本层之一,其输出是输入特征的线性组合。在线性层中,每个输入特征与对应的权重相乘,然后将所有结果相加得到输出。
作用
线性层的计算公式为:output = input * weight + bias,其中weight是权重矩阵,bias是偏置项。线性层的作用是对输入进行线性变换。
Dropout层
定义
Dropout是一种在神经网络训练过程中随机丢弃一部分神经元的技术。在每次训练迭代中,随机选择一部分神经元不参与前向传播和反向传播,从而减少神经网络的复杂度和提高泛化能力。
作用
- 减少过拟合:Dropout有助于减少神经网络的过拟合风险,提高模型的泛化能力。
- 增加模型鲁棒性:通过随机丢弃神经元,使得模型对输入数据的扰动更加稳健。
- 避免协同适应:Dropout可以减少神经元之间的协同适应,提高模型的鲁棒性。
其思想非常类似于集成学习,在训练(正向传播)的时候,随机进行失活(让一部分参数置为0),相当于训练了多个弱分类器;在预测的时候,dropout层失效(由于数学期望是一样的)
试验代码
import torch
from torch import nndropout = nn.Dropout(p=0.5)
X = torch.randn(10)
运行结果:

右上可以看到,dropout会50%概率将X中的值置为0。
卷积网络搭建
LeNet简介
LeNet5诞生于1994年,是最早的卷积神经网络之一,其作用主要用来进行手写字符的识别与分类。由于LeNet网络结构比较简单,但是刚好适合神经网络的入门学习。
LeNet结构

如图所示,LeNet共分为7层,分别是:
- C1,卷积层
- S2,池化层
- C3,卷积层
- S4,池化层
- C5,卷积层
- F6,全连接层
- OUTPUT,全连接层
输入层
-
定义:LeNet的输入层接受原始图像数据,并将每个像素的灰度值作为输入信号传递给下一层的卷积层。输入层的作用是将原始数据转换为神经网络可以理解和处理的格式,为后续的特征提取和分类任务奠定基础。
-
参数:输入层为尺寸32 × 32的图片。
一般来说不将输入层视为网络层次结构之一,上面讲的"7层"也不包括输入层。
卷积层C1
-
定义:卷积层C1是LeNet模型中的第一个卷积层,用于提取输入图像的特征。
-
功能:卷积层C1的主要特点和功能如下:
- 卷积操作:卷积层C1使用多个卷积核(也称为滤波器)对输入图像进行卷积操作。每个卷积核都是一个小的二维矩阵,通过在输入图像上滑动并与局部区域进行点乘操作,从而提取特定的特征。
- 特征映射:每个卷积核在卷积操作后会生成一个特征映射(feature map),表示了输入图像中某种特定特征的分布情况。通过使用多个卷积核,卷积层C1可以同时提取多种特征。
- 非线性激活函数:在卷积操作后,通常会应用非线性激活函数(如ReLU)来引入非线性性,帮助网络学习更复杂的特征。
-
主要参数:
-
输入:
32 × 32的图像 -
卷积核种类:
6 -
卷积核大小:
5 × 5 -
输出特征图数量:
6每个卷积核分别与输入图像进行卷积运算,共得到6份输出
-
输出特征图大小:
28 × 28输出图大小的计算方法:原图片的大小 - 卷积核大小 + 1 = 输出图片大小
如图所示:5(原图) - 3(卷积核) + 1 = 3(输出图)
-
池化层S2
-
定义:池化层(Pooling Layer)是深度学习神经网络中常用的一种层类型,用于减少特征图的空间维度,从而降低模型复杂度、减少参数数量,并且有助于防止过拟合。
-
作用:
- 减少特征图的空间尺寸:通过池化操作(如最大池化、平均池化等),将特征图的某个区域(池化窗口)内的值进行汇总,从而降低特征图的空间维度。这有助于减少后续层的计算量,提高计算效率。
- 提取特征:池化层可以帮助网络提取特征的不变性,即使输入图像发生轻微平移、旋转或缩放,提取到的特征仍然具有稳定性。
-
常见池化操作有两种:最大池化(Max Pooling)和 平均池化(Average Pooling)
以最大池化为例:采用2 × 2的滤波器(filter),最大池化的结果如上,即对每个2 × 2的区域取最大值。

- 主要参数:
- 输入:
28 × 28的特征图(6张) - 采样区域:
2 × 2 - 输出特征图大小:
14 × 14 - 输出特征图数量:
6
- 输入:
卷积层C3
-
定义:卷积层C3是LeNet模型中的第三个卷积层,用于进一步提取输入特征图的更高级别特征。其输出将作为下一层的输入,经过池化层等操作逐步提取更加抽象和高级的特征。
-
主要功能和作用:
- 多通道卷积:卷积层C3通常会使用多个卷积核对前一层(一般是池化层S2)的特征图进行卷积操作。每个卷积核对应一个输出特征图,通过多通道卷积操作实现对不同特征的提取。
- 局部连接:与全连接层不同,卷积层C3中的神经元只与输入图像的局部区域连接,这样可以减少参数数量和计算复杂度。
-
主要参数:
-
输入:
14 × 14的特征图(6张) -
卷积核种类: 16
因此卷积层C3能够提取出更多细微的特征
-
卷积核大小:
5 × 5 -
输出特征图数量:
16 -
输出特征图大小:
10 × 10输出特征图的边长为14 - 5 + 1 = 10
-
池化层S4
- 定义:池化层S4通常紧跟在卷积层C3之后,用于对卷积层提取的特征图进行下采样和降维,以减少计算量、提高计算效率,并增强模型的鲁棒性。
- 主要功能和作用:
- 下采样:池化层S4通过对输入特征图的局部区域进行池化操作(如最大池化、平均池化),将每个池化窗口内的值进行汇总,从而减少特征图的空间维度。
- 降维:池化操作可以降低特征图的分辨率,减少参数数量,有助于防止过拟合,提高模型的泛化能力。
- 平移不变性:池化操作可以提高模型对输入数据的平移不变性,即输入数据发生轻微平移时,池化层的输出保持稳定。
- 主要参数:
-
输入:
10 × 10的特征图(16张) -
采样区域:
2 × 2在这里,采样方式为4个输入相加,乘以一个可训练参数,再加上一个可训练偏置,并将结果通过sigmoid函数。
-
输出特征图大小:
5 × 5 -
输出特征图数量:
16
-
卷积层C5
-
定义:卷积层C5是LeNet模型中的第五个卷积层,也是整个网络中的最后一个卷积层。卷积层C5的主要作用是进一步提取输入特征图的高级别特征,并将这些特征用于后续的分类任务。
-
主要作用:通过卷积层C5的特征提取操作,网络可以学习和理解输入数据的更加抽象和复杂的特征,从而提高模型对不同类别的区分能力。
-
主要参数:
- 输入:
5 × 5的特征图(16张) - 卷积核种类:
120 - 卷积核大小:
5 × 5 - 输出:
120维向量
- 输入:
-
算法:
每个卷积核与16张特征图做卷积,得到的结果求和,再加上一个偏置,结果通过sigmoid函数输出。

全连接层F6
-
定义:全连接层F6是LeNet模型中的最后一个层,用于将卷积层提取的特征进行分类和预测。
-
主要功能:
- 全连接层F6在LeNet模型中扮演着连接卷积层特征提取和最终分类预测的桥梁作用,负责将高级别的特征映射转换为最终的输出结果,实现对输入数据的分类和识别。
- 全连接层F6的输出通常是一个向量,每个元素对应一个类别或回归值的预测结果。在分类任务中,通常会使用softmax函数对输出进行归一化,得到各个类别的概率分布,从而实现对输入数据的分类预测。
-
主要参数:
- 输入:
120维向量 - 输出:
84维向量
- 输入:
-
算法: 计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
F6层有84个结点,本质上对应一张7×12的比特图。实际上,ASCII码就可以用一张7×12的比特图来表示,每个像素若为-1则表示白色,1表示黑色。该全连接层的设计也是利用了这一思想。

全连接层OUTPUT
- 输入:
84维向量
本质上是一张7×12的比特图,表示经过我们多层处理最终得到的一张"数字图像"。
- 输出:
10维向量
OUTPUT层共有10个结点y0、y1、…、y9,分别对应着数字0到9。
LeNet整体工作示意图
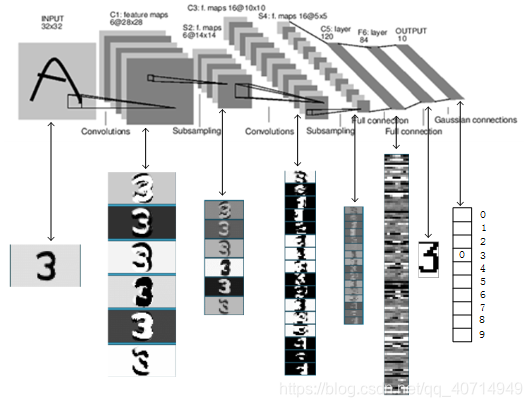
LeNet代码实现
import torch
from torch import nnclass ConvBlock(nn.Module):"""一层卷积块:- 卷积层- 批规范化层- 激活层"""def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):super().__init__()self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,kernel_size=kernel_size, stride=stride, padding=padding)self.bn = nn.BatchNorm2d(num_features=out_channels) # 批规范化层self.relu = nn.ReLU() # ReLU激活函数def forward(self, x):x = self.conv(x) # 卷积操作x = self.bn(x) # 批规范化操作x = self.relu(x) # 激活操作class LeNet(nn.Module):def __init__(self):super().__init__()# 特征提取部分self.feature_extractor = nn.Sequential(# 第一层卷积块ConvBlock(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0),nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # 最大池化层# 第二层卷积块ConvBlock(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0),nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # 最大池化层)# 分类部分self.classifier = nn.Sequential(nn.Flatten(), # 展平操作nn.Linear(in_features=400, out_features=120), # 第一个全连接层nn.ReLU(), # ReLU激活函数nn.Linear(in_features=120, out_features=84), # 第二个全连接层nn.ReLU(), # ReLU激活函数nn.Linear(in_features=84, out_features=10) # 输出层)def forward(self, x):# 1. 特征提取x = self.feature_extractor(x)# 2. 分类x = self.classifier(x)return xmodel = LeNet()
model
内容小结
-
卷积神经网络
- 卷积本质上是一个数学问题,表示方法为 ( f ∗ g ) ( t ) = ∫ − ∞ ∞ f ( τ ) g ( t − τ ) d τ (f * g)(t) = \int_{-\infty}^{\infty} f(\tau)g(t-\tau) d\tau (f∗g)(t)=∫−∞∞f(τ)g(t−τ)dτ
- 卷积可以理解为:在一个系统中,不稳定输入f和稳定输出g的情况下,用卷积求系统的存量。
- 卷积还可以理解为:在t时刻发生一件事,用卷积求t时刻之前事情f(x)对t时刻的影响。
- 图像的卷积是利用卷积核对原图片的二维矩阵进行相乘再相加的计算,本质上是计算周围像素点对中间像素点的影响。
- 因为图像多种多样的形式存在,其整体显示不同,但是局部却是相同的;人是很容易看出来的,而让机器也像人一样识别出图像的话,就需要利用卷积进行局部特征提取。
- 神经网络的学习过程就是将图片作为输入,将卷积核作为待调整的参数,通过机器学习的方式让机器在卷积运算中寻找特征,从而固定卷积核。
- 神经网络的学习过程中,可以将有一个卷积的操作,作为另外一个卷积的输入;同时特征矩阵可以利用不同的卷积核生成不同的特征矩阵,这种输入输出全部连接在一起的形式与人体神经网络非常类似,因此叫卷积神经网络。
-
卷积网络组件
- Batch Norm层:对每一层对输入进行归一化处理,即将每个特征维度的数据归一化为均值为0、方差为1的分布。
- ReLU层通过 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)引入了非线性,有助于神经网络学习复杂的模式和特征。
- Dropout层随机选择一部分神经元不参与前向传播和反向传播,从而减少神经网络的复杂度和提高泛化能力。
-
LeNet
- LeNet共分为7层,3个卷积层、2个池化层、2个全链接层。
- LeNet的整体工作过程:通过2层卷积+池化对图片进行特征提取,然后展平再利用2个全连接层,将高级别的特征映射转换为最终的输出结果,实现对输入数据的分类和识别。
参考资料
B站:【卷积神经网络】为什么卷积哪儿都能用?
B站:【从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变】
CSDN:深度学习入门(一):LeNet-5教程与详解
CSDN:LeNet讲解+代码实现,训练MNIST数据集
这篇关于【课程总结】Day10:卷积网络的基本组件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








